
《第1章 编程常识》节略部分
统治地球的冯·诺依曼们
1961年,一个叫叶永烈的21岁青年(他也是《十万个为什么》的作者,前网文时代的先驱),写了一本叫做《小灵通漫游未来》的科普小说。

书中提到了可视电话、电子表、家庭机器人、助听器、隐形眼镜、人造食品、语音识别、远程教学等诸多科学幻想。时至今日,这些当年的痴心妄想早已成为现在人人都习以为常的东西。而这其中,计算机所起到的作用居功至伟。 计算机确实帮助人们做到了很多很多不可思议的事情,它渗透到从银行、证券、通信、能源、交通、电力、水利、农业、基建、制造、天文、贸易、医学、教育、住房、旅行、购物、交友到互联网的方方面面,它让我们得以自由地探索自己和外面的大千世界。“计算是计算机存在的目的和意义,一切都为算力(Computility)而生,为了能更快更高效地计算,在计算机的发展历程中,偶然里又带着必然。 世界上第一台通用`计算机有个好听的名字:埃尼阿克(ENIAC,Electronic Numerical Integrator And Computer,电子数字积分计算机)。严格来说,它不能叫做计算机,只能说是有一间房子那么大的计算器(而且还是世界上第二台计算器,不是第一台)。

通用计算机ENIAC因为ENIAC主要是由真空管拼凑起来的,里面包括了几百个电子逻辑门、开关和电线。
所以也可以把ENIAC看成浑身长满大灯泡的铁箱子。

灯泡的铁箱子
灯泡的铁箱子电子计算机由电力驱动,而这些构成逻辑门的真空管只有两种状态:不是被打开的状态,就是被关闭的状态(在物理学尚还存在情况下,不可能有第三种状态)。所以为了数学和物理表达上的简便,就用1表示开,用0表示关——计算机中的二进制由此诞生。 但在电子计算机诞生的一个多世纪以前(也就是1834年),就已经有人构思出了现代计算机的完整雏形——分析机。它拥有分工明确的处理器、控制器、存储器、输入与输出等不同装置,它是一个叫查尔斯·巴贝奇(Charles Babbage)的英国天才发明家的杰作。只是由于他的设计过于先进,那时候的世界还制造不出他所需要的设备,达不到他所要求的工艺精度而无法实现这种构想。直到100多年后,在万事俱备,只欠东风时,才由一个叫约翰·冯·诺依曼的匈牙利裔美籍数学家、计算机科学家、物理学家、化学家、博弈论之父,跨越时空实现了查尔斯·巴贝奇(Charles Babbage)的天才构想。

虽然关于谁才是真正的计算机之父至今没有确切的定论,有人认为是查尔斯·巴贝奇(Charles Babbage)(通用计算机之父),有人认为是阿兰·图灵(计算机科学之父),有人认为是约翰·阿坦那索夫(电子计算机之父),还有人认为是约翰·冯·诺依曼(现代计算机之父)。
从不同的侧面来说,这都对,但是笔者认为,查尔斯·巴贝奇(Charles Babbage)太过于超前,在错误的时间得到正确的结果,抱憾终生;阿兰·图灵更侧重于密码学和人工智能在计算机上的应用;而约翰·阿坦那索夫虽然也摸到了现代计算机体系结构的大门,但终归还是一颗近失弹(Near miss,军事术语,意思就是在极近的距离下失去目标,虽无杀伤但冲击力极大)。他们当中,只有冯·诺依曼是站在巨人的肩膀上(包括利用了莱布尼兹发明的二进制和查尔斯·巴贝奇(Charles Babbage)提出的通用计算机的设计理念等),第一次完整地提出了现代计算机体系结构的基本思想。
在1944年,ENIAC还未建成之时,冯·诺依曼在返回洛斯·阿拉莫斯的列车上写出了那篇长达101页且影响整个计算机历史走向的《EDVAC报告书的第一份草案》,准备着手设计建造EDVAC(Electronic Discrete Variable Automatic Computer,电子离散变量自动计算机)。

这份草案不仅详细说明了EDVAC的设计思路,也为现代计算机的发展指明了道路。
计算机使用二进制表示数据。
计算机要像存储数据一样存储程序。
计算机由运算器、控制器、存储器、输入和输出五大部分组成。
这最终奠定了现代冯·诺依曼型计算机的体系结构(以下简称冯·诺依曼机)。在冯·诺依曼机中规定:指令和数据要事先保存在存储器中,然后控制器按地址编码顺序逐一取出这些指令和数据,由运算器执行指令功能,完成计算任务。同时,也规定了冯·诺依曼机必须具备的五大功能。
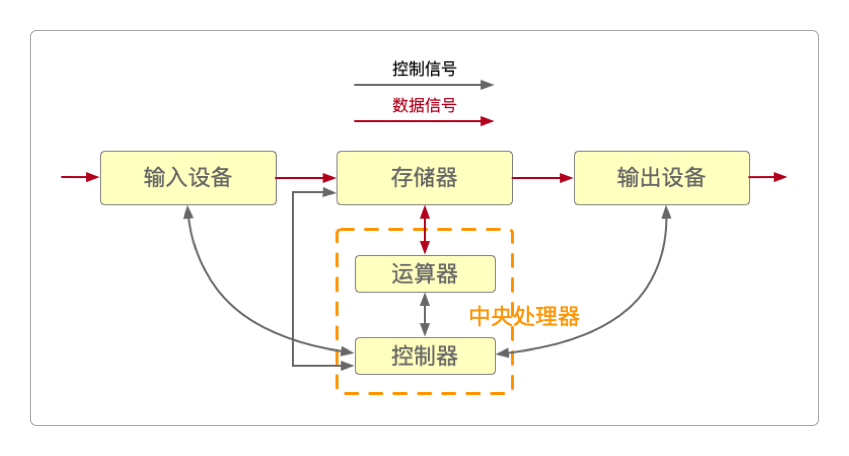
输入/输出功能。计算机必须能输入数据和指令(也就是解题步骤),同时能够把按照要求把计算结果和计算过程中输出给用户。
存储功能。计算机必须有能够长期记忆数据、指令、计算的中间结果和最终结果的能力。
计算功能。这是计算机的核心功能,它必须能够完成各种算术和逻辑的运算,并能进行数据传送和数据加工的能力。
判断功能。计算机必须具备控制程序走向,从预先设定的若干种方案中选择一种方案的能力。
控制功能。计算机必须具备保证执行的正确性和控制各部件之间正确协调的能力。
从那时起直到现在,不管是巨型机、大型机、中型机、小型机还是微型机(个人计算机);不管是台式机、笔记本、PAD(平板电脑)、PDA(个人数字助理,在工业、医疗、物流等行业广泛使用,例如,抄表器、扫码枪、护理机)、智能手机还是智能电视,全世界大部分的计算机都还是遵照冯·诺依曼机所规定的体系结构设计和制造出来的。
当然,世界上除了冯·诺依曼机还有一些其他体系结构的计算机,例如光子计算机、分子计算机、量子计算机等,除非有特别说明,不然在一般情况下,本书后续的内容都是建立在冯·诺依曼机的基础上进行论述的。
二进制
可以看到,中间部分第一行第二至四列的内容分别为01010000、01001110和01000111,它们分别对应ASCII码表中的P、N、G。

P、N、G所对应的ASCII码这正是这个文件名的后缀。这是巧合吗?不是!因为在右边部分的剩余内容中可以看到其他和这个文件相关的一些信息,如创建文件的软件工具,文件创建时间等信息,这和用Windows显示出来的信息是一致的,而且用Hex Editor Neo软件展示出来的内容更多。
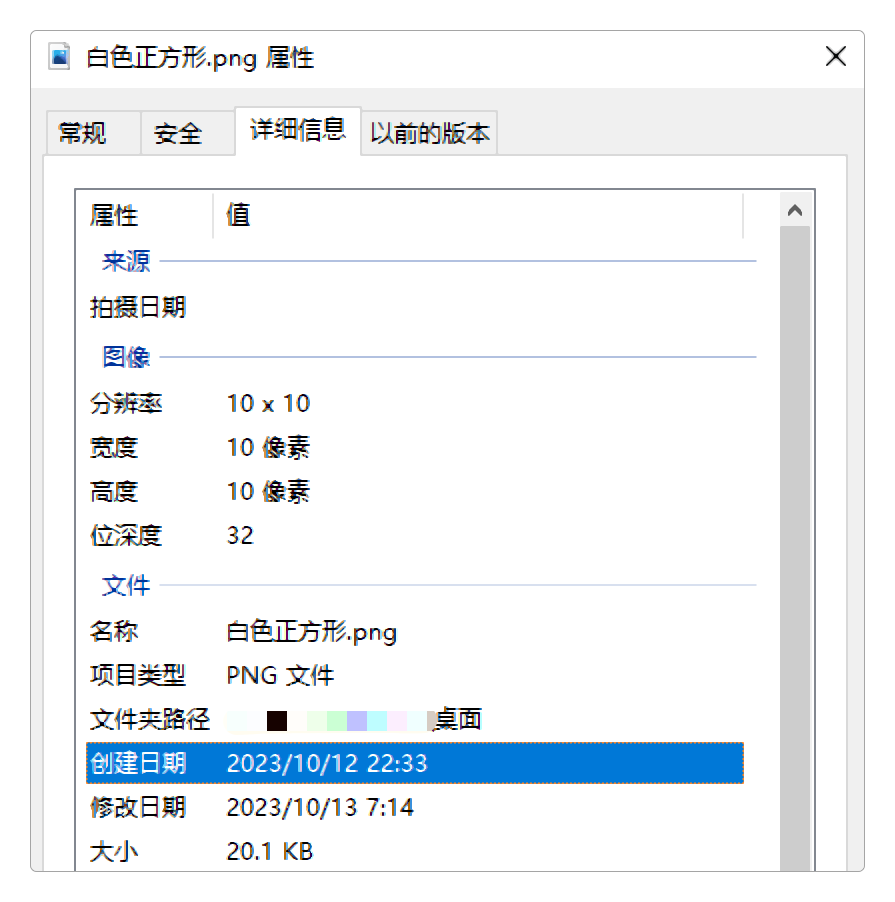
这里没有逐一对照用Hex Editor Neo软件和Windows属性面板展示出来的信息之间有什么不同,但如果按数学方式来表示的话,可以断定:Windows属性集一定是二进制内容的子集。有兴趣的读者还可以尝试用画图软件创建10×10像素的黑色正方形,再用Hex Editor Neo软件比对一下和白色正方形之间的二进制内容有什么不一样,这里就不继续了。 从这个意义上说,如果能够完全掌握用二进制创建文件的规则,是不是可以用Hex Editor Neo代替任何软件呢?例如,用Hex Editor Neo代替文本编辑器,代替Word,代替Photoshop,甚至代替IDEA来编程呢?这不但理论上是完全可以的,而且事实上也确实可行。不过,却不会有人真那么做,因为太费时费力,效率太低!
可以把同样类型的文件(例如,PNG图片)多创建几个,仅改变不同文件之间的尺寸和颜色,然后通过二进制进行比对,就可以发现这样一个事实:我们平常所看到的任何文件,除了文件的内容本身,还含有一部分附加信息。这些附加信息用户是看不到的,即使看到了也没有意义。因为它们是给计算机操作系统准备的,用以区分各类不同的文件类型及读取、存储方式,如下图所示的那样。
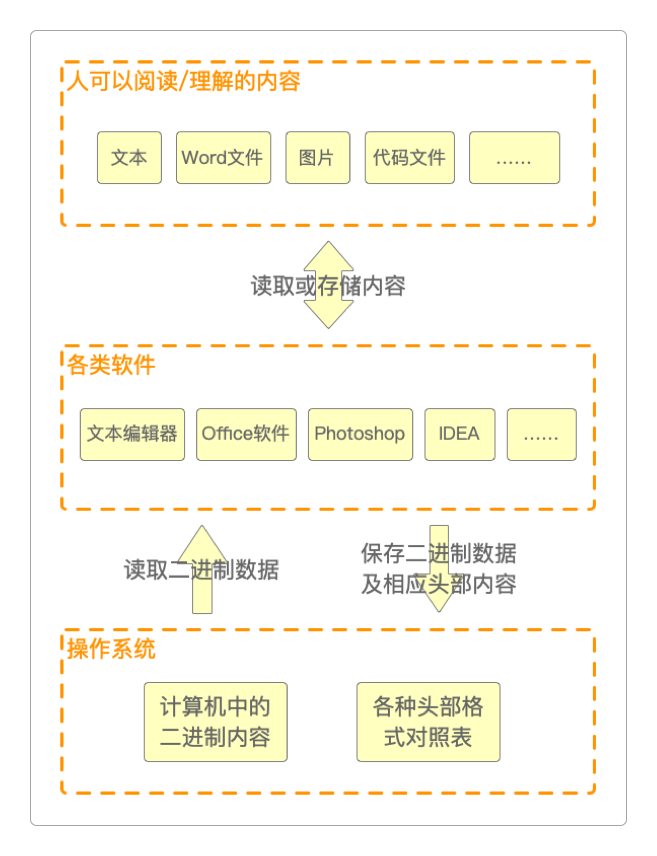
从上图可以看出,操作系统及其中的各种软件是这样工作的。
读取时,操作系统通过这些附加信息就知道这种文件该给交由哪种软件处理、转译并展示。
存储时,各种软件会给文件额外增加专属的附加信息(软件安装时就会在操作系统的注册表中
登记这些附加信息)。卸载后,由于对应的附加信息被一并清除,所以操作系统也就不知道对应类型的文件该给哪种软件处理了。
这种附加信息有一个计算机专有名词术语:文件头。这也正是操作系统及各种应用软件存在的意义:有些文件头十分庞大,如果要人力用二进制的方式编写完成,无疑既费力又不讨好,但计算机却十分擅长这种精确无误的重复性劳动。
另外,如果有些读者真想挑战一下用二进制创建文件,可以试试code.org网站。这是由微软开发的一个计算机科学入门的免费的网上实验室,有一些好玩的小东西。比如下面就是笔者做的一个简单二进制演示,有兴趣的读者可以自己玩一玩。
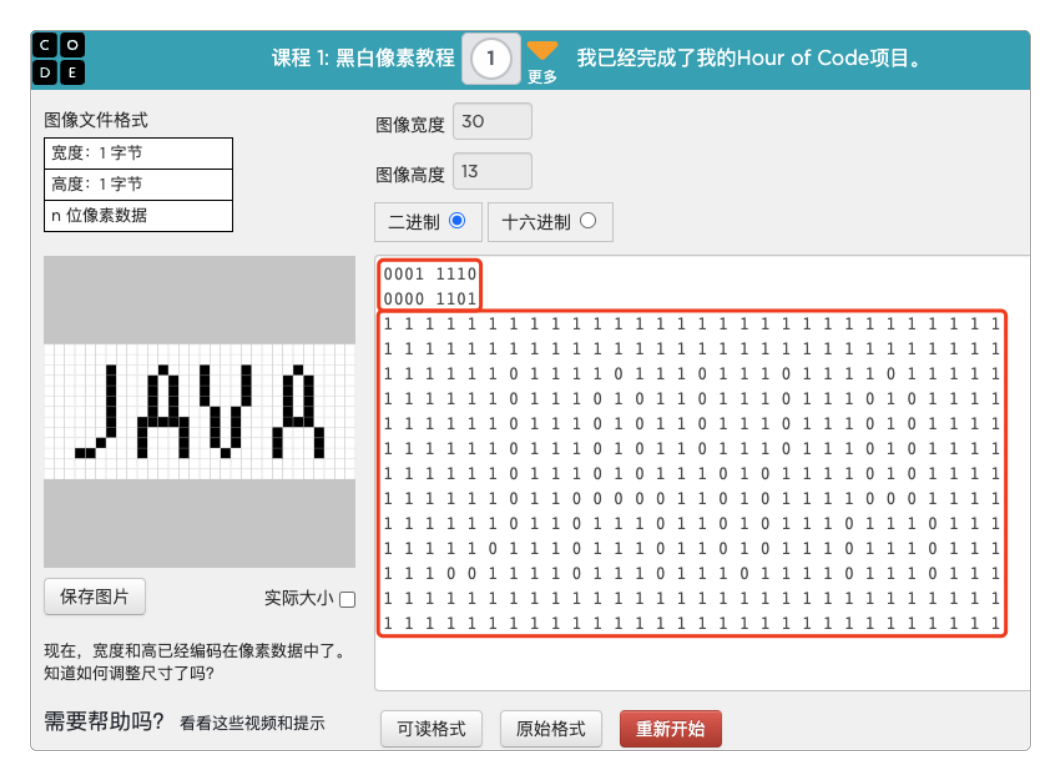
稍做说明:图中小框是左边图片区域的宽和高,也就是白色小方块的行数和列数(上方也可以直接输入指定),大框是图片中的内容部分:由白色的小方块和黑色小方块拼成的Java组成。其中1代表白色背景小方块,而0代表黑色绘图线条小方块。
位深、采样率和码率
多媒体这个词已经成为了互联网的一部分,如果有些读者希望从事多媒体开发,那么位深、采样率和码率这几个和二进制相关的概念就不能不了解。而且在视频和音频中,这几个文字相同的名词,其意思还有些差别。 所谓位深(Bit Depth),在图像领域,指的是在分辨率不变的情况下,每一个像素点可以容纳多少种色彩,单位为bit。在计算机成像中,每个像素都由红绿蓝三基色组合而成(RGB色彩模式),每种基色被称为颜色通道。位深可以作用于颜色通道(此时为每通道比特数),也可以作用于像素点(此时为每像素比特数,Bits Per Pixel,称为bpp)。
一般的彩色图像成像时,其每通道比特数为8,也就是每种基色可以有28(2的8次方,即256)个不同的强度值,例如暗红、深红、大红、粉红等不同强度。而每个像素是三种基色组合在一起的。所以对一个8位的像素来说,三个颜色通道组合在一起就可呈现出超过28×3=1670万种不同的颜色或真彩色。

为了更直观地说明位深的效果,可以看看下面这张图。

可以看到,位深越大,图像质量越高。根据不同的图像位深,下面列出了关于位深的一些相关信息。
| 位深 | 可用颜色总数 | 分辨率的通用名称 | 分辨率 |
|---|---|---|---|
| 1 | 2 | 单色 | |
| 2 | 4 | CGA | 320 × 200 |
| 4 | 16 | EGA | 640 × 350 |
| 8 | 256 | VGA | 640 × 480 |
| 16 | 65535 | SVGA,增强色 | 800 × 600 |
| 24 | 16777216 | XGA,真彩色 | 1024 × 768 |
在数字音频系统中,计算机需要通过声卡将模拟信号转换为数字信号才能得到音频信息。声卡能够很轻松地进行每秒上万次的采样,每一次的采样都会记录声波在某一时刻的状态,这个东西就叫样本。把这一连串的样本连接起来时,就组成了一段完整的声波。因此,所谓采样率就是声卡每秒钟所采集的样本数量,单位为赫兹Hz。例如48000Hz,也就是每秒采样数为48KHz。自然,采样率越高,就说明每秒采集的样本数越多,拼接出的声波质量就越好。 在音频领域,位深也被称为采样精度,表示每个样本中所包含的比特数。常见的位深有16Bit和24Bit。
最后,码率,其实也就是比特率,音视频中都有码率一说。它指的是单位时间内传输或处理的比特数量,和带宽的概念有些类似。显而易见,单位时间内,传输的比特数越多,声音就越清晰,视频画质就越好。 其实,在多媒体领域的相关开发工作中,还有很多的名词术语和相关概念,例如编码模式、编码格式、制式、帧率、场序、灰度级数、DTS & PTS、GOP、IDR帧、跨距等,但其本质都是上大同小异的,不过就是对二进制数据的传输、处理和存储的方式不同而已。
树型数据结构
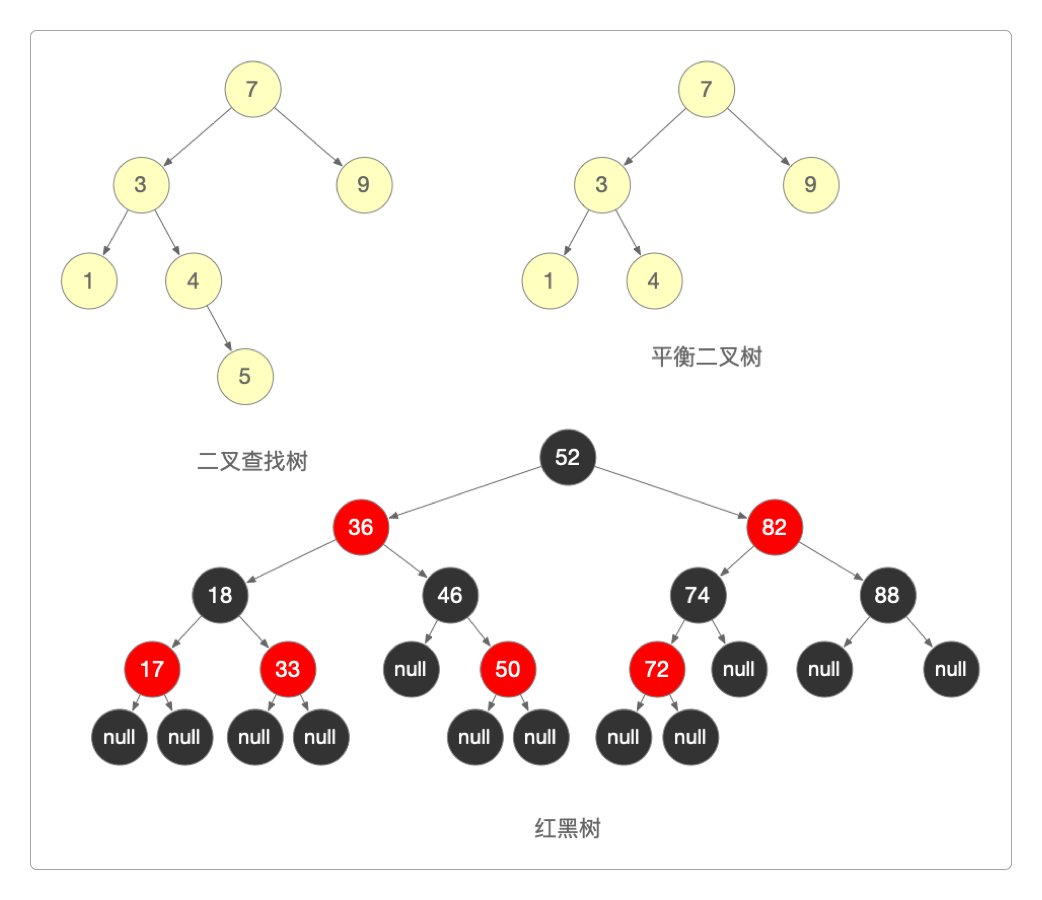
二叉查找树(BST)又称二叉搜索树,它是一颗二叉树。
若其左子树不空,则左子树上节点的值必定小于它根节点的值。
若其右子树不空,则右子树上节点的值必定大于它根节点的值。
任意节点的左右子树也都是二叉查找树。
平衡二叉树(AVL)是一颗二叉查找树,其左右子树的高度差的绝对值不超过1,且左右子树也都是平衡二叉树。
红黑树(RBT)是一颗二叉查找树。
根节点和叶子节点都是黑色的,且叶子节点都是值为null的节点。
每个节点要么是红色的,要么是黑色的。
红色节点的子节点和父节点都是黑色的。
从任一节点到叶子节点,其路径上包含的黑色节点数量相同。
B树在有些文档或资料中也叫B-树,但称它为B-树有些不妥,因为称其为B-树,可能会让人误认为是另一种数据结构。所以没有所谓的B-树,只有B树。
一个m阶的B树具有如下定义。
根节点不是叶子节点时,根节点有n个子节点,2 <= n <= m。
每个内部节点都至少有n个子节点,n =
Math.ceil(m / 2)。且其所含键k的数量范围为n - 1 <= k <= m - 1,键是用于指向数据记录的指针。Math.ceil()函数表示向上取整,例如Math.ceil(1.1)和Math.ceil(1.8)向上取整的结果都为2。有n个键的非叶子节点必须有n + 1个子节点。
所有叶子节点的深度(或高度)都一样,也就是说它们都要在同一层。
每个节点中键的数值都从小到大排序,且每个节点的子树也按照下列顺序从左至右依次排列。
第一个子树的所有键值都小于其父节点的最小键值。
第二个子树的所有键值都大于其父节点的最小键值,而又小于其父节点的第二小键值。
其他中间子树的键值属性及排列位置依此类推。
最后一个子树的所有键值都大于其父节点的最大键值。
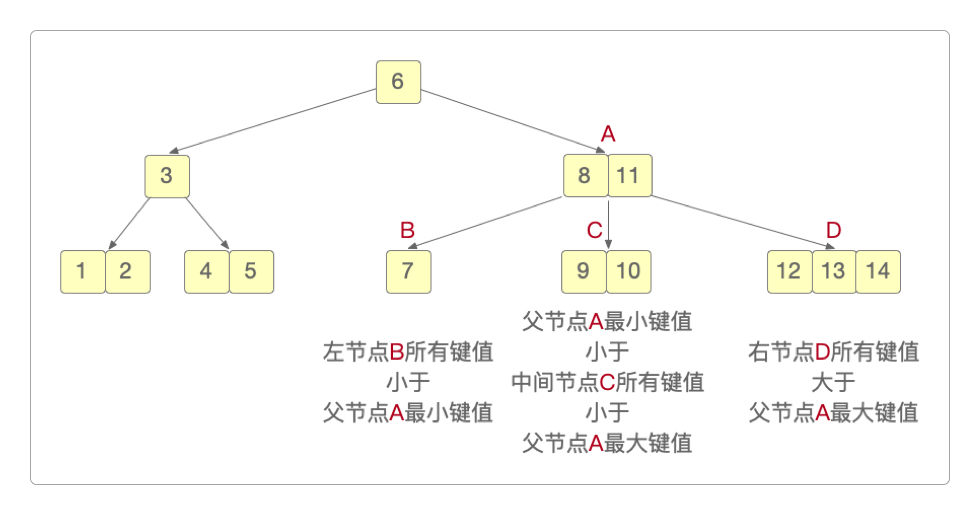
从上图也可以很容易地看出键值排列的规律。
左节点B中的所有键值都要小于父节点A中最小的键值
8。中间节点C中所有键值都要大于父节点A的最小键值
8,但又都小于父节点A第二小的键值11。右节点D中的所有键值都要大于父节点A中最大的键值
11。
下面展示了B树从1到14的插值生成过程。如果阶数太少说明不了问题,但阶数多了过程又太冗长。以4阶B树作为演示刚好合适。在4阶B树中,每个结点最多只4个子节点,最多只有3个键(key = m阶 - 1),最少有1个键(key = Math.ceil(m / 2) - 1),有n个键的非叶子节点必须有n + 1个子节点。
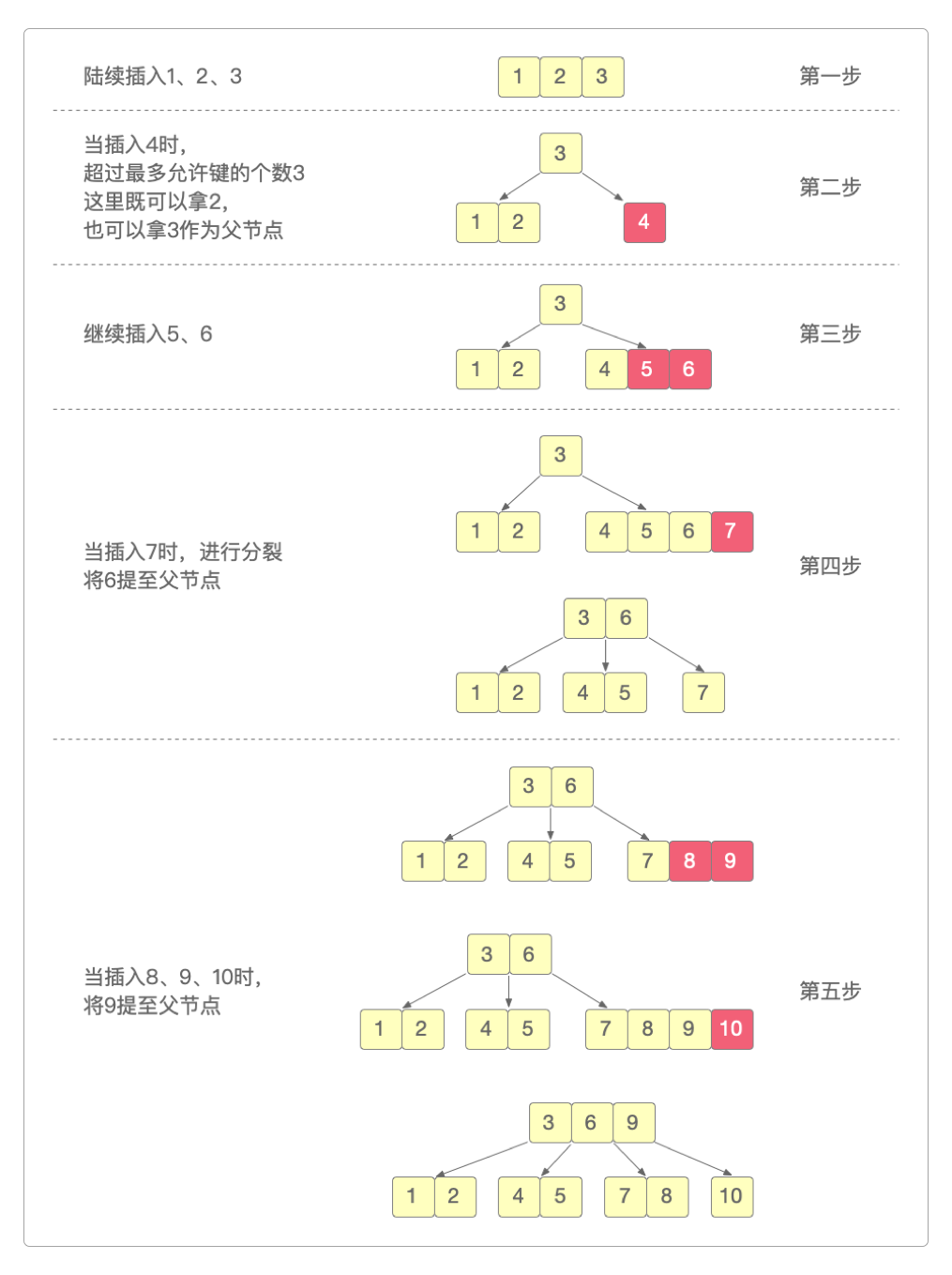
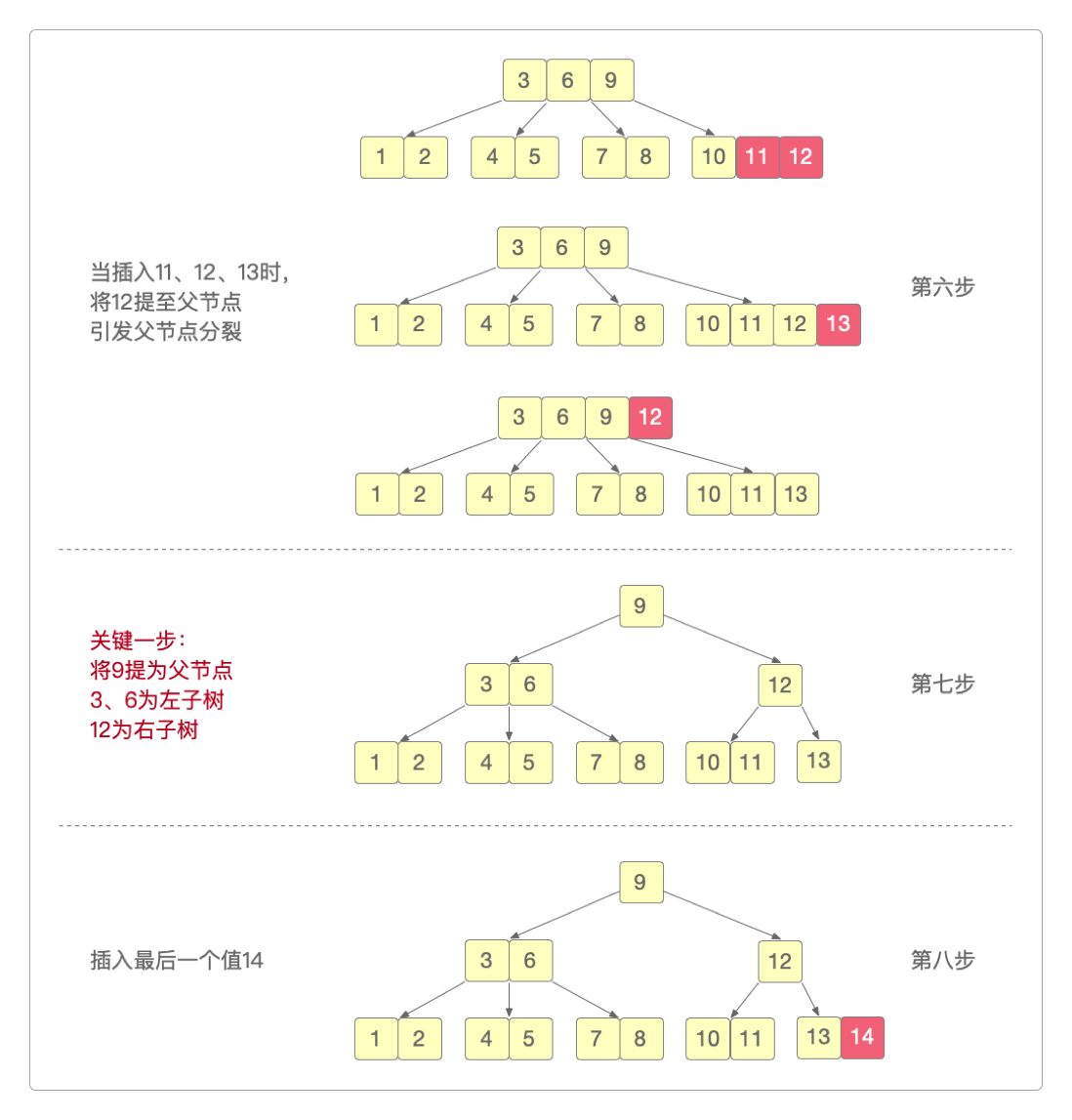
可以看到它和前面B树的结构有些不同。这也是笔者想指出的B树的另外一个隐藏属性。
如果不是从1开始插值,而是从其他数开始,也就是说生成B树的插值顺序不同,那么生成的B树也就不同。
如果第2步选择键值
2作父节点,那么最终生成B树的结果也会不同。
以上两点充分说明:插值顺序和权重对生成B树的结果有直接影响。这也是很多资料当中都没有提到的一点。
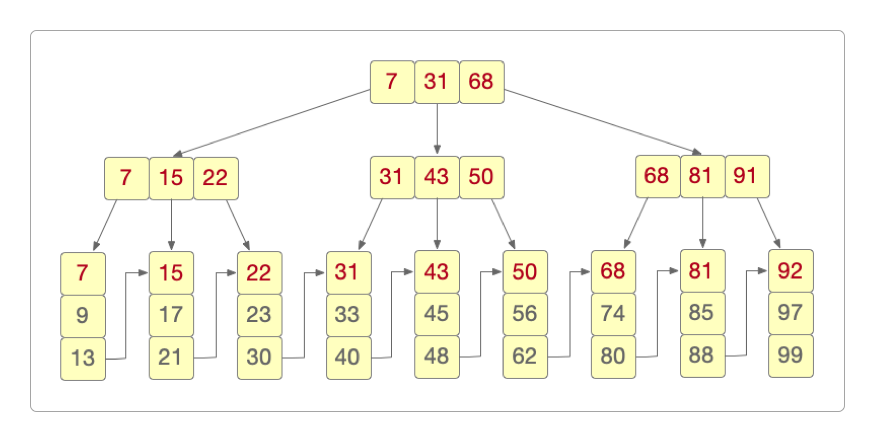
节点分为两种不同的类型:索引节点和数据节点。
所有数据节点全部都是叶子节点,其他子节点只存储索引。
每个叶子节点都存有相邻叶子节点的索引,如此组成一个单向链表。
父节点存有右子节点第一个元素的索引。
B+树的生成和B树非常类似,只是它所有的数据都在叶子节点上而已,此处就不再展示其生成过程了。
在树型数据结构中,B+树的生成和B树比较复杂,如果是需要开发文件系统一类的应用,或者数据库底层存储,那就必须要深入掌握它所涉及到的每一个技术细节,否则,了解其原理就行了。
只不过MySQL的底层存储是通过B+树实现的,所以有些面试官比较爱问相关的问题。
中断与轮询
另一个和并发比较类似且相关的概念,也在此一并澄清,那就是中断(Interrupts)与轮询(Polling)。
所谓中断,就是由计算机硬件或软件发出的一种请求(IRQ,Interupt ReQuest)信号,一旦CPU收到这种信号就会保留目前的执行状态(现场)并暂停执行当前的任务,转而去响应中断请求。这个中断请求对CPU来说是被动的,因为CPU并不知道它什么时候会发生。比如,当用户正在用USB设备拷贝资料时,如果这时候突然打开一个很大的文本文件(可能几百MB),性能较差的计算机就会明显看到卡顿现象。这种卡顿就是因为CPU被中断拷贝任务以后,去执行打开文件的操作了。由于性能较差,所以读取速度较慢,也就会出现了卡顿。

中断过程可以从图中看出,当CPU正在执行拷贝资料的任务时,突然收到一个IRQ请求,CPU立即响应它,在保护好前一任务现场的同时,马上执行打开文件的任务。如果拷贝资料的任务并未停止或结束,且文件较大,那么CPU此时可能就会进入并发工作模式,将工作时间片轮流分配给它们。这种通过时间片定时询问设备工作状态的机制,就叫做轮询(Polling)。
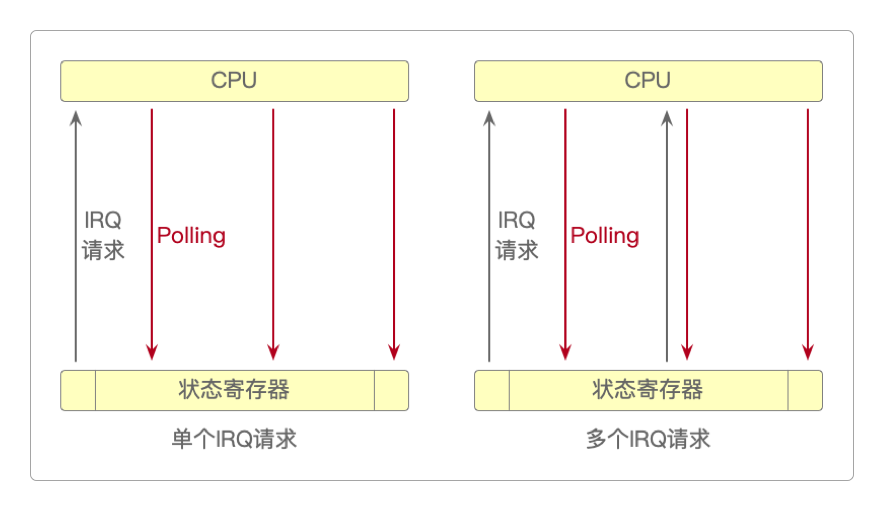
轮询过程计算机上的I/O设备都有一个状态寄存器,用于存储当前设备的工作状态。通过不断查询这个设备状态寄存器中的数据,CPU就可以准确地知道当前系统的整体运行情况,从而执行可能到来的I/O操作。为了节约CPU资源,轮询不是一直持续的,而是以固定时间间隔的方式执行。这种CPU级的时间间隔一般以毫秒甚至微秒为单位,人类无法感知。这也就是为什么并发工作模式会让人觉得好像是多个任务同时在执行的原因——快到让人察觉不到。可以说,CPU的并发工作模式正是因为有了中断与轮询的技术支持才得以运行。
至于中断与轮询的技术细节不必深究,这属于计算机硬件体系结构相关的领域,与本书内容所涉及的范畴无关。
国际化、本地化与全球化
国际化(Internationalization,又称i18n)与本地化(Localization,又称l10n)其实与技术没有多大关系,但是作为一名拥护并追求极致工程师文化的软件开发工程师,笔者思虑之后还是把它放在了本章的最后一节。一是希望人人都能开发出高质量且高可用(这里并非指性能,而是实用性)的软件。二是希望咱们软件产业能响应国家政策的号召,为走出去做好充分的常识性准备。 不同的国家和地区有不同的语言、政策、律法、价值观、货币、度量单位,甚至是日期、历法等文明印记。如果希望自己开发出来的软件或应用,可以仅凭一套代码在世界范围内发布,以最低成本快速适应全球需要,那么就要做好充分的国际化工作。
文本编码:例如将
ISO/IEC 8859转换为Unicode,将中文中的标点符号都转换为相适应的标点符号。数据适配:包括货币格式、汇率、度量单位(公斤转换为英镑、公里转为英里)、时区(北京时间转换为纽约时间)、日期格式、电话格式、地址格式、数字格式(中文数字转换为阿拉伯数字)。
功能适配:例如有些地区还没有移动支付或电子支付手段,那么就需要适应当地的支付方式,如VISA、MASTER等信用卡支付或者面对面的现金支付方式。
文化适配:在有些国家,红色可能不代表热烈,而是代表禁忌。
政策律法适配:需要遵守当地的法律、法规和条例,例如欧盟GDPR条例等。
如果说国际化是一套框架和方向,规定了软件需要进军海外的各项准备工作的话,那么本地化就是来具体完成这些工作的流程和手段。它针对的是具体的国家和地区需要执行转换的那些工作。
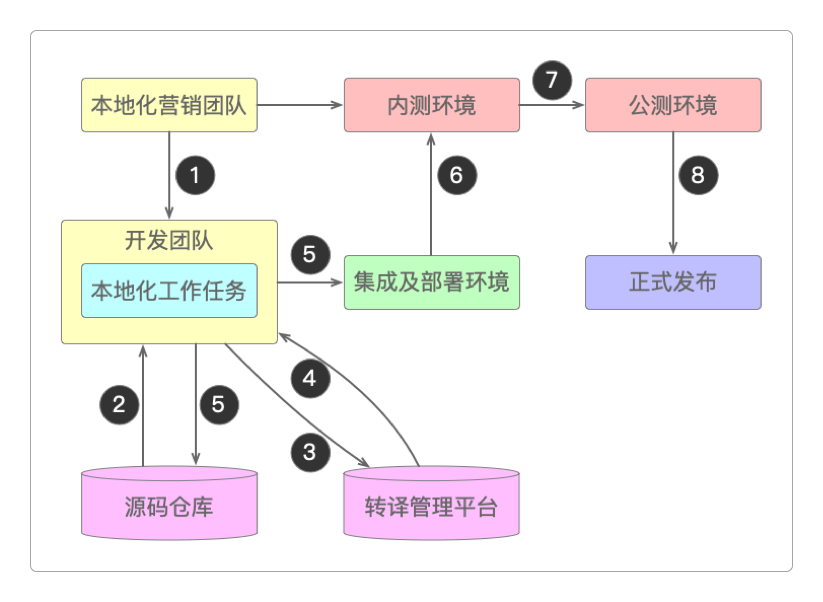
本地化的一般流程①首先是由营销部门整理产品中所有涉及到需要进行本地化的内容。
②开发团队根据营销部门整理的内容,结合源码提取出需要转译的语言字符、数据、功能等本地化工作任务。
③将本地化任务交给转译管理平台完成转译工作。这个转译管理平台可以是开源框架,可以是公司自研的软件工具,可以是第三方平台API、SDK,或者也可以是专业外包的产品全球化组织。
④转译管理平台完成本地化任务后,将内容输出给开发团队。
⑤开发团队整合转译管理平台的输出内容后开始集成并部署。
⑥发布的第一个版本作为内测版本开始测试,发现可能出现的本地化问题。
⑦内测通过后再扩大范围,开始小规模发布,交由一些种子用户或志愿者进行公测。
⑧公测通过后就可以正式发布了,在整个使用过程中还会不断地改进和完善。
除了上面的那套流程,完整的本地化其实还包括一些更高、更抽象层次上的内容,它包括但不限于SEO本地化、产品设计本地化、开发流程本地化、技术标准本地化、售后服务的本地化等。 从全局上来说,国际化和本地化都是全球化(Globalization,又称g11n)的一个子集。
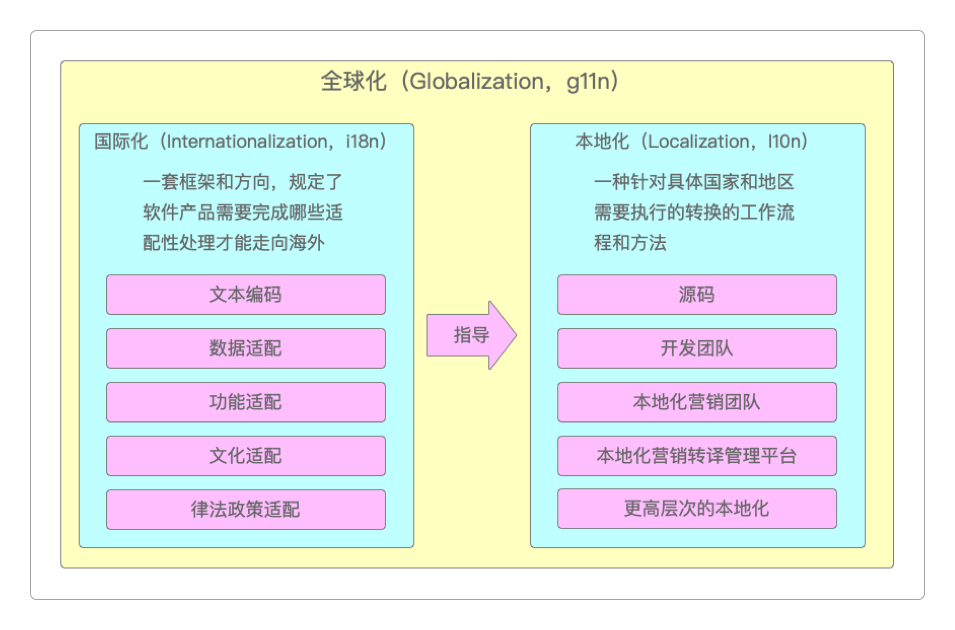
全球化代表的是一整套软件产品从设计、研发、测试再到全球营销落地的完整服务流程,它在更高的层次上关注研发管理、市场营销、售后服务等各业务环节。因此,优秀的全球化实践,其实就是向客户提供更好的产品和服务体验的实践。
感谢支持
更多内容,请移步《超级个体》。