
Reactor
什么是Reactor
Reactor是第四代反应式库,它围绕Reactive Streams标准,在JVM之上构建出一组非阻塞、事件驱动风格的API。
它的主要目标是希望用有限数量的线程来满足高性能计算的需要。Reactor直接和Java函数式编程整合,例如组合异步组件CompletableFuture和Stream。
Reactor目前由projectreactor.io维护,其主要核心库是reactor-core,它是基于事件回调实现反应式编程,从命令时编程转化为响应式编程有一定的学习成本,Java工程师一开始可能不太习惯这种编程模式。所以对于学习Reactor的建议如下。
掌握异步的概念,理解为什么需要异步。
掌握函数式编程范式。
掌握观察者模式。
理解Reactive Streams规范。
多参考projectreactor.io的官方文档。
Reactor提供了两个异步组件:Flux和Mono。它们都实现了Reactive Streams规范的Publisher接口。
Flux表示可以发出0个或者N个元素的反应式序列,并根据实际情况结束处理或触发错误。而Mono则表示可以发出0个或1个事件,所以它常用于在异步任务完成时发出通知。为了满足开发需求,也为了减少工程师的工作量,Flux和Mono都已集成了大量生成数据的方法和操作符,使用它们的一般流程如下图所示。

所谓操作符就是函数式编程中提到过的算子,其实创建或定义数据源的方法也是算子。对于它们的区别,官网给出的图示也非常清晰。
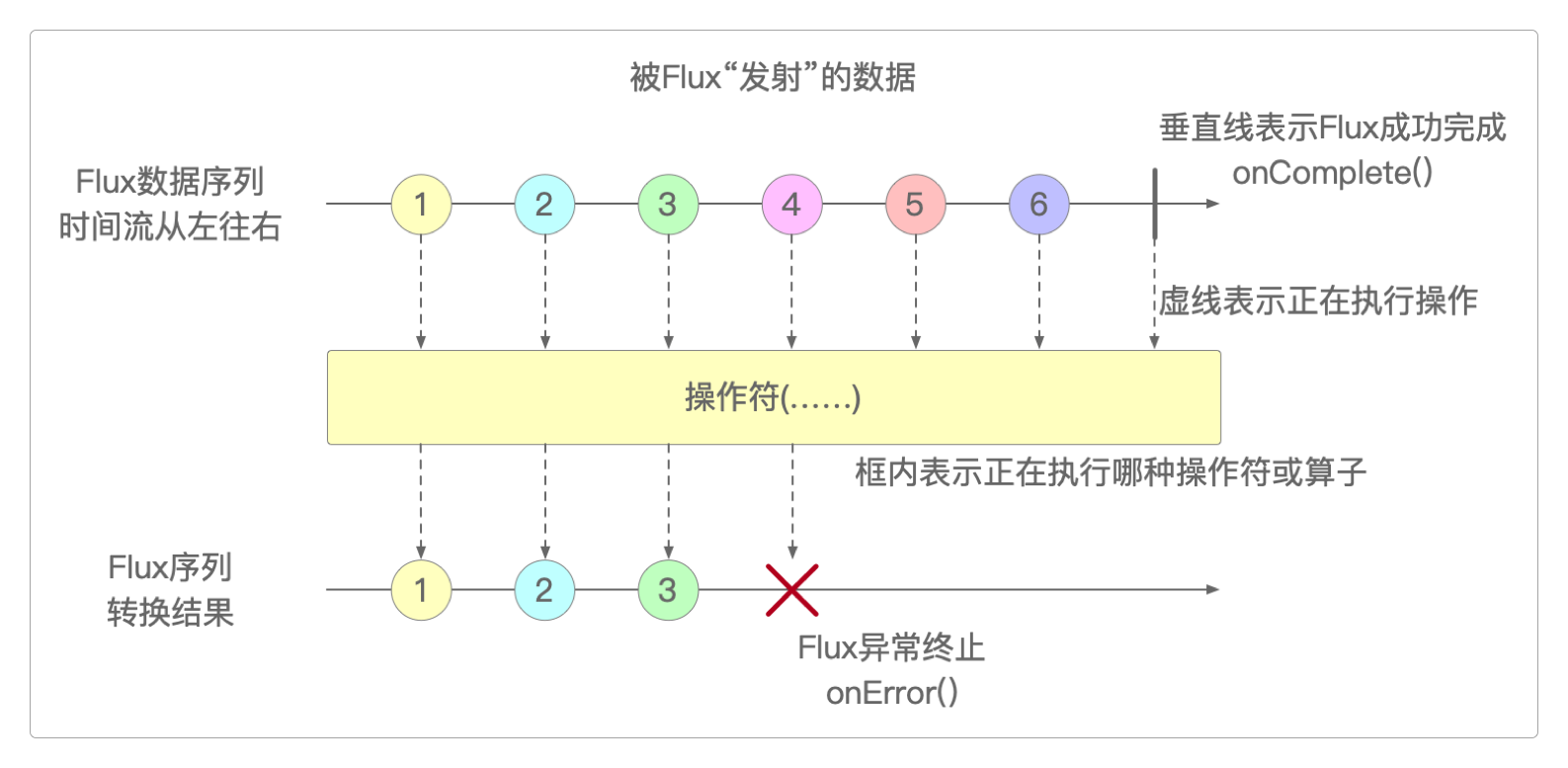
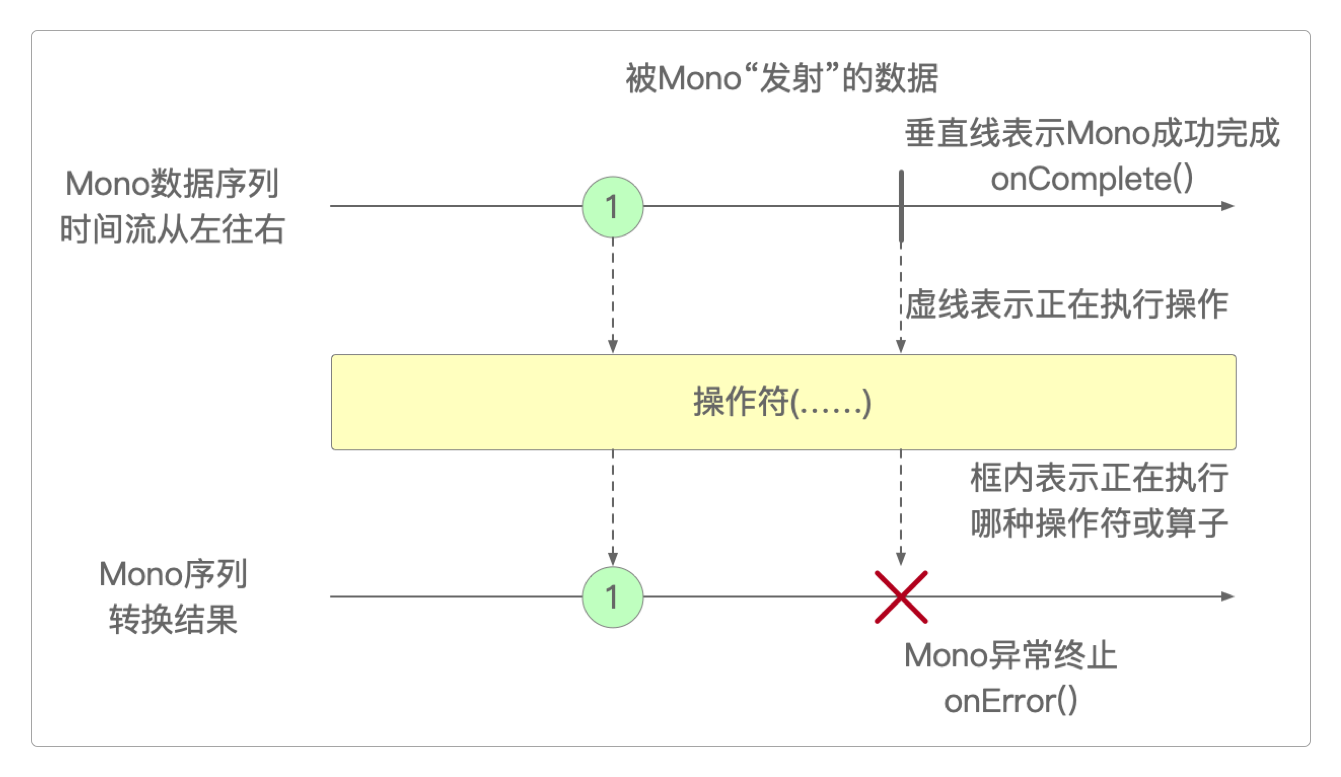
Flux
对Reactor有了一个大致的概念之后,就可以先试试水了。
package cn.javabook.chapter06;
import com.java.book.chapter05.lambda.Employee;
import reactor.core.publisher.Flux;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.Duration;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* Flux实例
*
*/
public class FluxDemo {
public static void main(String[] args) throws InterruptedException {
/*
* 一:两段代码完成一样的功能:一段命令式编程,一段反应式编程
*/
// 命令式编程
int[] array = new int[] {1, 2, 3};
for (int i : array) {
int result = i * i;
if (result > 3) {
System.out.println(result);
}
}
// 反应式编程
Flux.just(1, 2, 3).log()
.map(i -> {
return i * i;
}).log()
.filter(i -> i > 3).log()
.subscribe(System.out::println);
// Flux.just(1, 2, 3).log()
// // 产生异步边界
// .publishOn(Schedulers.boundedElastic()).log()
// .map(i -> {
// return i * i;
// }).log()
// .filter(i -> i > 3).log()
// .subscribe(System.out::println);
System.out.println();
System.out.println("################");
System.out.println();
/*
* 二:定期生成一个自增数
*/
Flux.interval(Duration.ofMillis(300)).log()
// 大于5重算
.map(output -> {
if (output < 5) {
return " output " + output;
}
throw new RuntimeException("good game!");
}).log()
// 遇到错误重新运行一遍
.retry(1).log()
// 元素转为类似Scala的Tuple2<Long, T>类型,第一个字段为运行间隔
.elapsed().log()
// 输出映射后的数据
.subscribe(System.out::println, System.err::println);
TimeUnit.MILLISECONDS.sleep(3000);
System.out.println();
System.out.println("################");
System.out.println();
/*
* 三:读取文件内容并打印
*/
Path path = Paths.get("/Users/bear/Downloads/常用命令.txt");
// 创建Flux对象并读取文件内容
Flux.using(
() -> Files.lines(path),
Flux::fromStream,
stream -> {
try {
stream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
).log()
// 订阅Flux对象并输出文件内容
.subscribe(System.out::println);
System.out.println();
System.out.println("################");
System.out.println();
/*
* 四:获取员工信息并按照年龄排序后打印
*/
List<Employee> employees = Arrays.asList(
new Employee("梅丽", "女", 26, true, Employee.Type.OFFICER),
new Employee("郑帅", "男", 29, false, Employee.Type.OFFICER),
new Employee("曾美", "女", 27, true, Employee.Type.SELLER),
new Employee("郝俊", "男", 22, true, Employee.Type.SELLER)
);
// 创建Flux对象
Flux.fromIterable(employees).log()
// 按照年龄排序
.sort(Comparator.comparing(Employee::getAge)).log()
// 订阅Flux对象并打印员工信息
.subscribe(emp -> System.out.println(emp.getName() + " - " + emp.getAge()));
}
}这四个小例子分别代表了四种不同的应用场景,比较有代表性。
除了
subscribe()方法之外,每个Flux操作符或算子后面都跟了一个.log()方法,它可以打印出每个算子的执行过程。subscribe()算子的作用等同于函数式编程中的终端操作符,例如,forEach()。也就是说,除非调用subscribe()算子,否则流不会对其中的数据进行任何处理,也不会产生任何数据,它什么都不会做。
当不存在任何中间算子时,代码中的Publisher、Subscriber和Subscription之间的调用关系如下图所示。
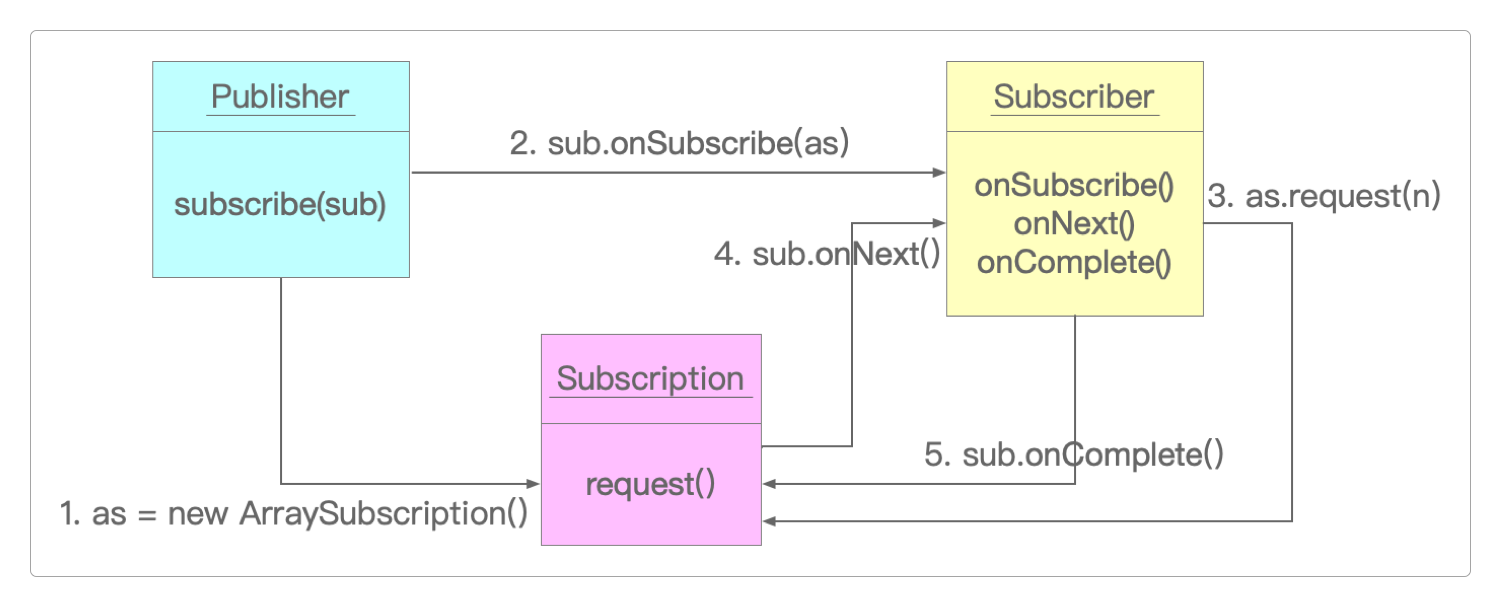
在subscribe()算子执行后发生如下动作。
发布者
Publisher新建了ArraySubscription变量as。通过订阅者
Subscriber的回调onSubscribe()算子,将as传递给sub。订阅者
sub通过as发起request(n)请求。因为代码中没有明确指定发起多少次请求,故而会显示request(unbounded),但默认为1。发布者通过
as发起sub.onNext()调用。如果发布者的序列结束或出错,则通过订阅者的
onComplete或onError传递信息。
至于所谓执行阶段或执行管道,可以先不必了解。以上过程完全是以同步的方式执行的,但Reactive Streams是提倡异步执行的。如果希望数据异步执行,从而通过异步边界实现组件隔离,那么只需要在代码中加上publishOn(Schedulers.boundedElastic())即可。
Flux.just(1, 2, 3).log()
.publishOn(Schedulers.boundedElastic()).log()
......
.subscribe(System.out::println);开启异步后的执行结果如下。
[main]INFOreactor.Flux.Array.1-|onSubscribe([SynchronousFuseable] FluxArray.ArraySubscription)
......
[boundedElastic-1] INFO reactor.Flux.MapFuseable.3 - | onNext(4)
[boundedElastic-1] INFO reactor.Flux.FilterFuseable.4 - | onNext(4)
4
[main] INFO reactor.Flux.Array.1 - | onComplete() // 主线程到此就已经结束了
[boundedElastic-1] INFO reactor.Flux.PublishOn.2 - | onNext(3)
[boundedElastic-1] INFO reactor.Flux.MapFuseable.3 - | onNext(9)
[boundedElastic-1] INFO reactor.Flux.FilterFuseable.4 - | onNext(9)
9
[boundedElastic-1] INFO reactor.Flux.PublishOn.2 - | onComplete()
[boundedElastic-1] INFO reactor.Flux.MapFuseable.3 - | onComplete()可以看到,主线程在执行到[main] INFO reactor.Flux.Array.1 - | onComplete()这一行的时候就已经结束了,但之后仍然有onNext()事件流出,这就是典型的异步执行。
Mono
如果说Flux可以发出0个或者N个元素的话,那么Mono就只能发出0个或最多1个元素,从它们相同操作符或算子的不同签名就能看出来:Flux.just(T...data)和Mono.just(T data)。
对于工程师来说,没有必要记住什么时候应该使用Flux,什么时候应该使用Mono,因为IDE中早已给出了明确的反馈。
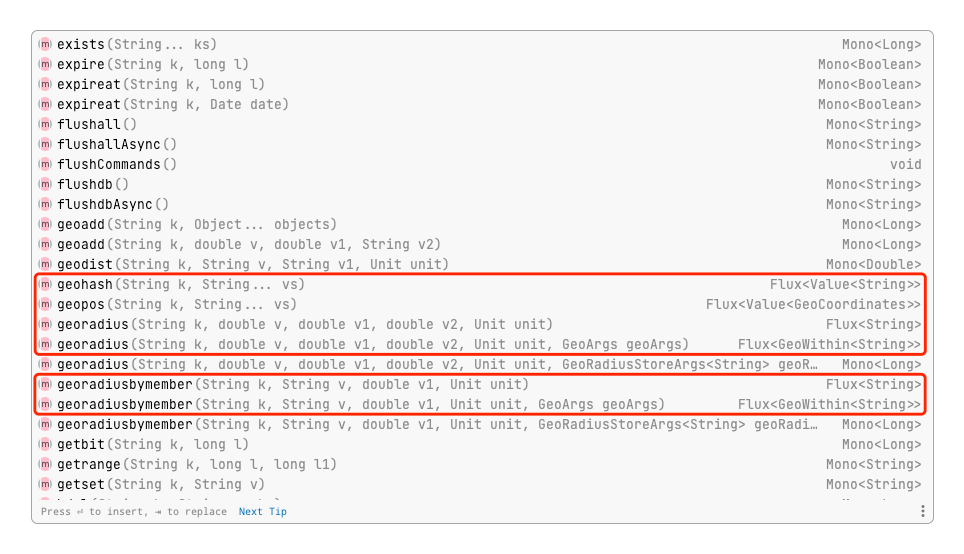
下面是用Mono操作Redis的典型应用案例。
package cn.javabook.chapter06;
import io.lettuce.core.RedisClient;
import io.lettuce.core.RedisURI;
import io.lettuce.core.api.StatefulRedisConnection;
import reactor.core.publisher.Mono;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
/**
* Mono实例
*
*/
public class MonoDemo {
private static final RedisURI redisUri = RedisURI.builder()
.withHost("172.16.185.166")
.withPort(6379)
.withDatabase(0)
.withPassword(new char[] {'1', '2', '3', '4', '5', '6'})
.build();
private static final RedisClient redisClient = RedisClient.create(redisUri);
private static final StatefulRedisConnection<String, String> conn = redisClient.connect();
/*
* 用命令式编程范式同步读取redis数据
*/
public static void getMonoBySync() {
System.out.println(conn.sync().get("cart"));
}
/*
* 介于传统与反应式之间的异步方式读取redis数据
*/
public static Mono<String> getMonoByAsync() {
return Mono.create(sink -> {
conn.async().get("cart").thenAccept(sink::success);
});
}
/*
* 用反应式编程范式读取redis数据
*/
public static Mono<String> getMonoByReactive() {
return conn.reactive().get("cart");
}
public static void main(String[] args) {
Executor pool = Executors.newFixedThreadPool(10);
// 同步操作耗时
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
pool.execute(MonoDemo::getMonoBySync);
}
long endTime = System.currentTimeMillis();
System.out.println("同步耗时:" + (endTime - startTime));
// 异步操作耗时
startTime = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
pool.execute(() -> {
getMonoByAsync().subscribe(System.out::println);
});
}
endTime = System.currentTimeMillis();
System.out.println("异步耗时:" + (endTime - startTime));
// 反应式操作耗时
startTime = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
pool.execute(() -> {
getMonoByReactive().subscribe(System.out::println);
});
}
endTime = System.currentTimeMillis();
System.out.println("反应式耗时:" + (endTime - startTime));
// 主线程要等待子线程执行完成
for (;;);
}
}通过三种不同编程范式读取Redis中存储的String数据。从代码中可以非常清楚看到,当线程池中有10个线程,并且出现100并发请求时,异步或反应式的操作耗时远远小于同步方式。
既然反应式编程范式这么优秀,为什么至今没有彻底取代传统编程范式呢?笔者认为有如下几种原因。
由一种编程范式转换为另一种编程范式,不仅需要开发者的习惯陡变,而且所有相关的外围生态和依赖全部要跟着变,这个代价有点大。
在CPU速度越来越快,网络速度越来越快的情况下,反应式异步线程切换的时间开销已经慢慢和它所带来的速度提升相互抵消了,
好处已经越来越少。在代码调试的时候,显然传统的同步阻塞式代码更易操作、更易阅读理解。如果要调试反应式代码,且不说至今尚未出现可以完全实现自动进行异步调试的IDE,就算有,这种不断在不同代码间跳来跳去的风格,能不能为工程师所接受,恐怕都还不好说。
反应式编程范式的最底层需要依靠
NIO技术,目前大多数的数据库并不是技术上无法支持,而是因为JDBC已经存在了20年,要改变它影响太过巨大。并且NIO再怎么多路复用,都无法凭空变出更多的数据库连接数。另外,是现实世界仍有大量传统的分析型或批处理型事务在运行着,这种操作反应式是一点忙都帮不上的,搞不好还会添乱。
因此,只有在确切了解反应式编程能够提升性能且易维护的情况下,才应该考虑使用它。例如专门消费消息的程序、专门读写大量NoSQL的程序,或者专门执行I/O密集型操作的程序。
感谢支持
更多内容,请移步《超级个体》。