
Impala高速查询引擎
Impala概述
Impala是Cloudera公司开发的一种高性能、低延迟的数据查询引擎,专门用于处理存储在Hadoop中的大数据,它的显著特点就是基于Hive,能够以SQL方式查询HDFS和HBase中的数据。
相对于MapReduce和Hive,Impala的速度更快,能实现秒级的即席查询。
Impala的优势在于以下几点。
之所以速度快,是因为它基于内存计算,不保存中间结果,能节省大量的
I/O开销。底层计算引擎用
C++开发,通过LLVM统一编译运行,效率更高。兼容Hive的
SQL语法,学习成本低,容易上手。具有数据本地化(Data Locality)的特点,提高计算效率。
支持列式存储的数据格式,可以与HBase整合。
支持几乎所有Hadoop支持的文件格式,例如
TextFile、SquenceFile、RCFile等。
而Impala的不足也有下面几点。
因为基于内存计算,如果宕机或者崩溃,可能会不得不重头再来。
用
C++开发导致维护难度较大。当分区数量超过10000,性能会严重下降,容易出现问题。
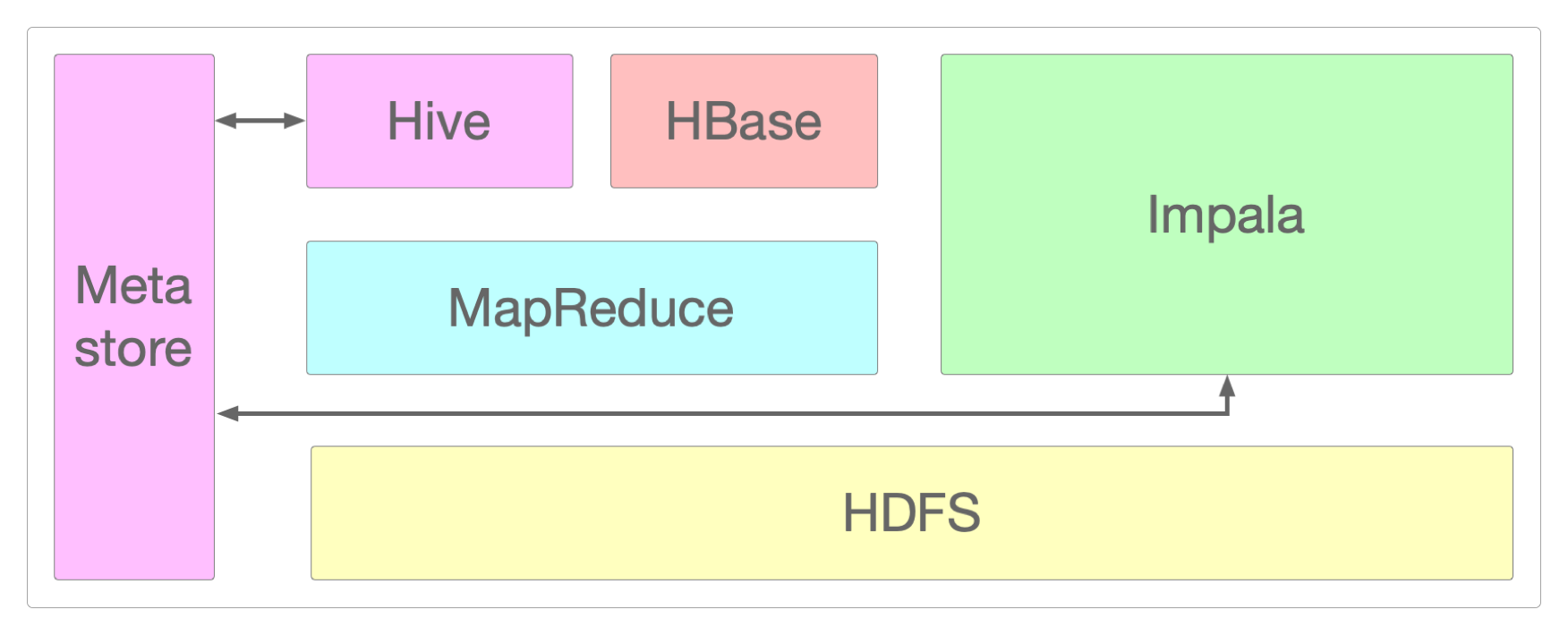
三大核心组件
Impala Daemon(impalad):这是Impala集群中的核心守护进程,一般和DataNode节点一起部署,与StateStore保持通信。它也负责接收客户端的查询请求,并向客户端返回查询结果。StateStore Daemon(statestored):负责收集集群中各个impalad进程的资源信息、各节点健康状况,以及同步节点信息,还负责Query的协调和调度。Catalog Daemon(catalogd):负责分发表的元数据信息到各个impalad,接收来自StateStore的所有请求。
整体运行架构
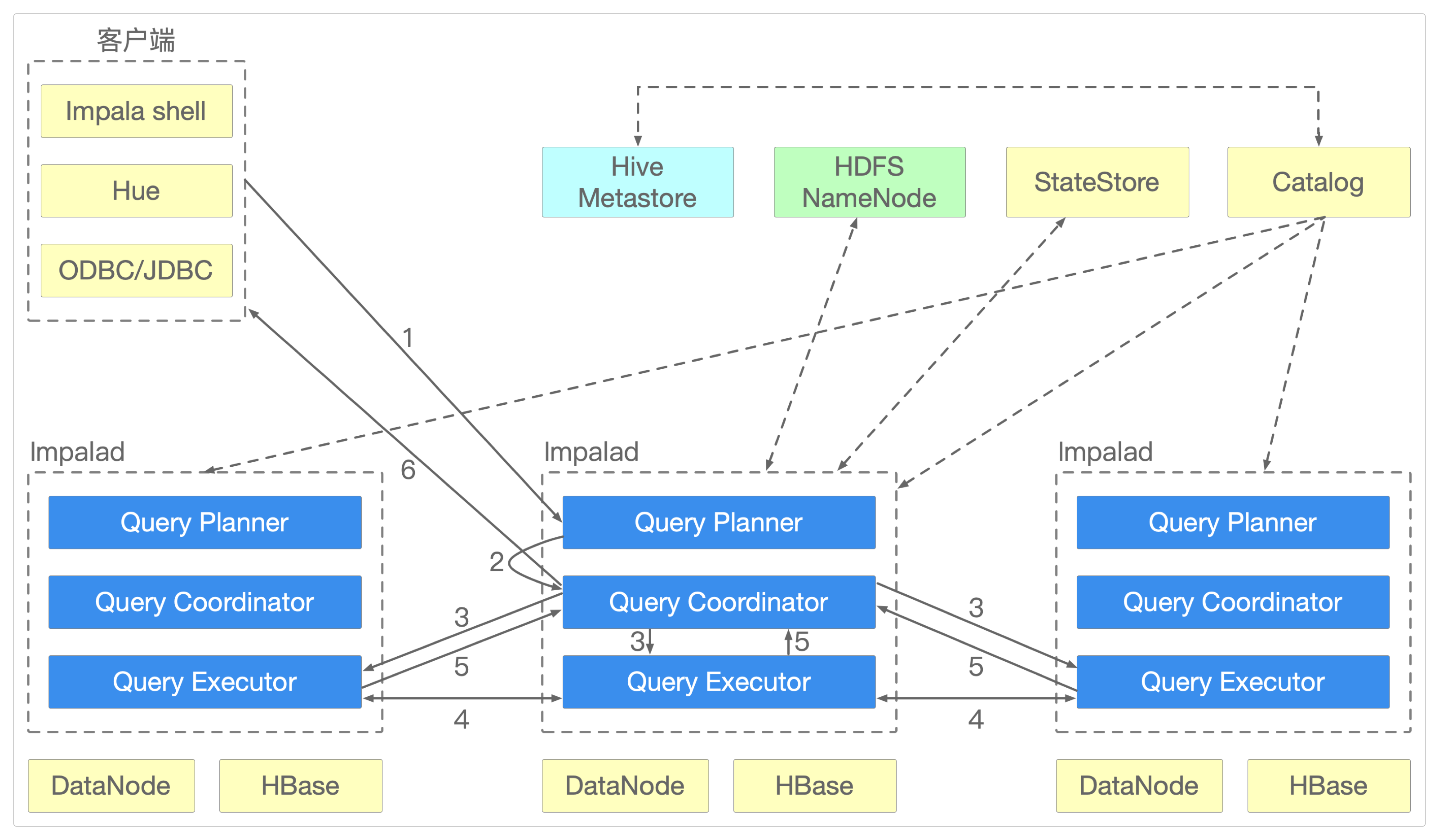
Hive Metastore负责维护Impala元数据信息。Impala的整个执行流程是这样的。
第1步:客户端向某个
Impalad发送一个Query(也就是SQL查询请求)。第2步:
Impalad将Query解析为具体的Query Pannner,然后交给当前节点的Query Coordinator去协调执行。第3步:
Query Coordinator根据Query Pannner通过节点的Query Executor执行,并转发给其他有数据的Impalad。第4步:多个
Impalad的Query Executor之间会进行通信,同步数据处理。第5步:
Query Executor将执行结果返回给Query Coordinator。第6步:由
Query Coordinator再将汇聚的执行结果返回给客户端。
本机部署
Impala的安装部署比较特殊,最佳安装方式是通过Cloudera(CDH)平台安装。
但Cloudera(CDH)平台本身的安装就非常麻烦,而且需要的节点资源众多,所以就不装了。
感谢支持
更多内容,请移步《超级个体》。