
关系推荐项目说明
项目背景
相信很多人都见过这样的功能:当你关注了某位大V(博主或主播),也会将TA的粉丝关注的大V推荐给你。
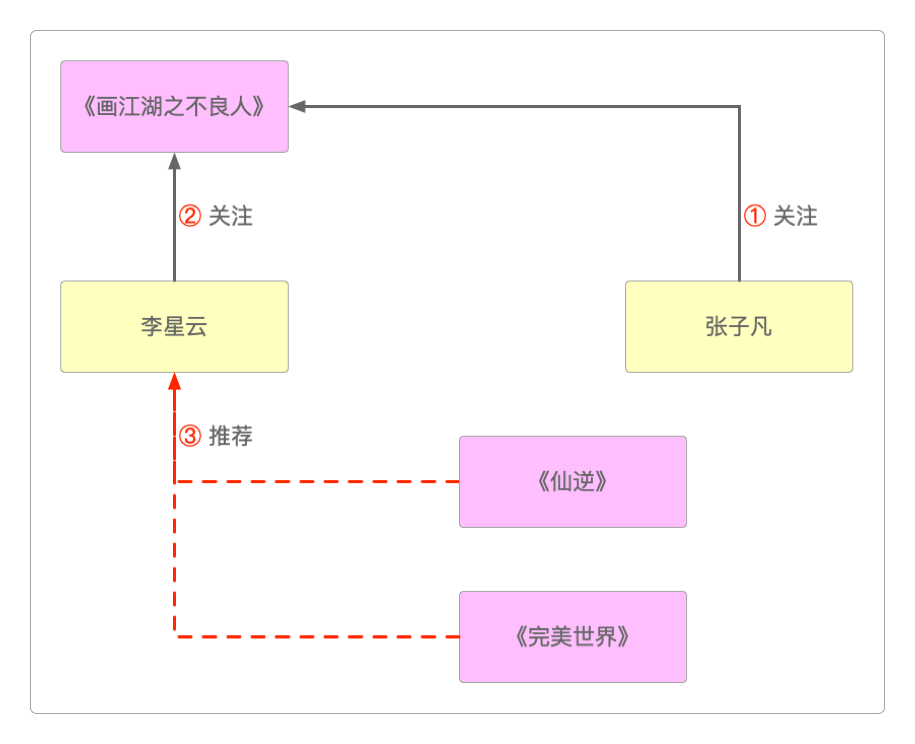
TA的人推荐给你①:
张子凡关注了《画江湖之不良人》。②:
李星云也关注《画江湖之不良人》。③:把
张子凡关注的内容也推荐给李星云。
这个功能就是所谓的三度关系推荐,不管推荐的是大V、粉丝还是别的什么,这种基于他们喜欢的你也可能会喜欢的功能在社交应用中还是比较普遍的。
例如,当用户关注某个直播平台的主播时,平台可能会向该用户推荐该主播的粉丝所关注的主播。
而且平台会按照推荐重合度来筛选满足条件的主播,并进行择优展示。
技术选型
和前面的案例Hive离线数据仓库一样,它也包括数据采集、数据存储、数据计算和数据展现这四大组成部分。
数据采集:Flume、Sqoop、Logstash、Filebeat等常用中间件前面已经做过比较,这里采用Filebeat部署在业务服务器上的方式,搭配Kafka、Flume和Sqoop实现数据采集。
数据采集技术选型 数据存储:在涉及大数据中应用中,首选基本上都是HDFS。但由于业务中需要存储大量的关系数据(这里的关系并非关系型数据库中的关系),所以如果用HDFS或MySQL来保存这些关系数据的话,会出现大量的冗余,且效果也不好。所以这里采用Neo4j这个图数据库系统。下面是几种不同图数据库之间的简单比较。
对比项 Neo4j OrientDB JanusGraph GraphX/Gelly 运行方式 计算+存储 计算+存储 计算+存储 仅计算但不保存数据 事务 支持 支持 支持 支持 数据模型 graph dov、graph、KV graph graph 查询语言 Cypher 类SQL Gremlin - 分布式 企业版支持 支持 支持 支持 维护成本 低 较高 高 低 是否开源 社区版开源 开源 开源 开源 数据计算:因为基于社交应用的关系推荐基本上都是实时计算出来的,所以基于MapReduce的第一代大数据计算引擎Hadoop显然无法胜任这种需求,而这个项目既需要实时计算,也需要离线计算,因此选择使用Spark来作为大数据计算的组件。数据展现:这里依然采用之前使用过的Zeppelin作为数据展现工具。
整体架构
在确定了需要使用的各个技术组件之后,三度关系推荐系统的整体技术架构可以这样来设计。
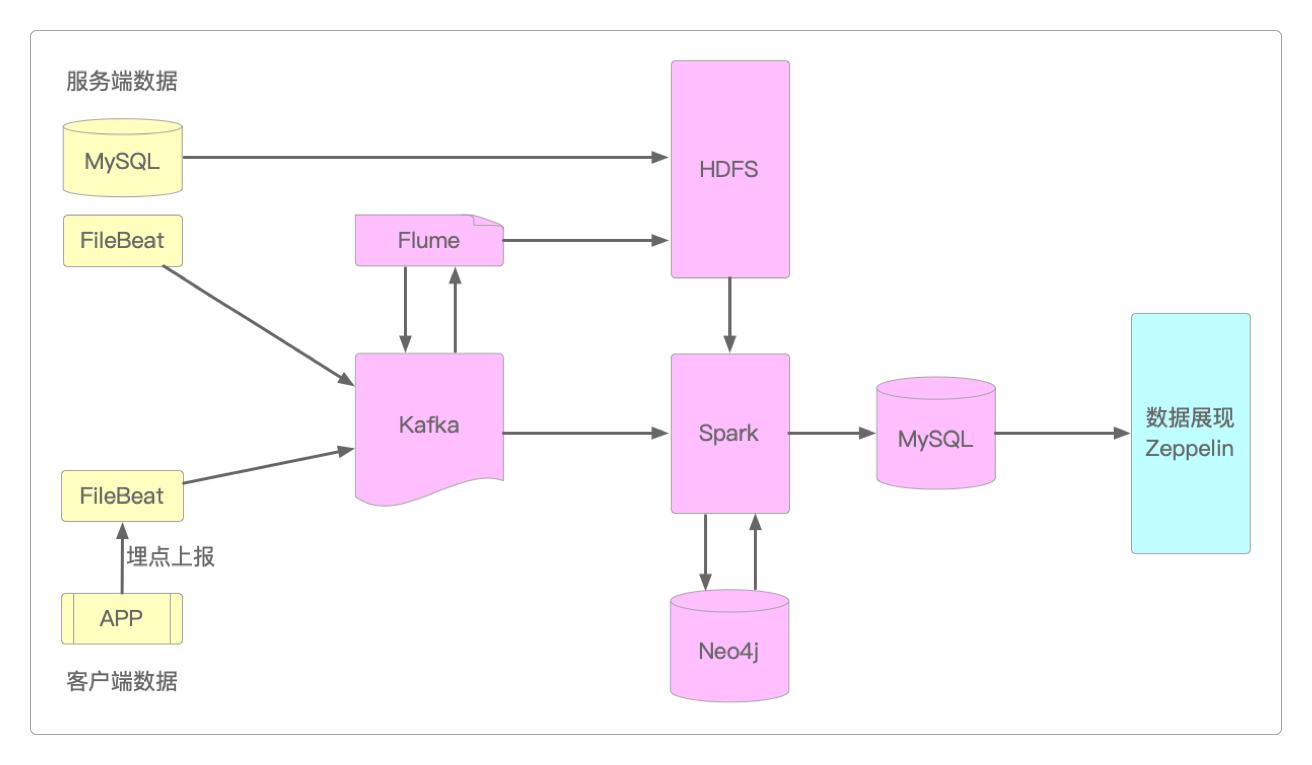
上面这个架构存在这么几个问题。
计算出来的结果直接用Zeppelin展示并不合适,完全可以改成
HTTP接口,供其他程序调用。
但前期采用这个架构已经能够实现所有需要的功能了。
它的服务器资源规划和Hive离线数据仓库类似。
虽然项目前期使用的是Spark,但到后期必须用Flink来代替它,这是因为社交应用的独特属性决定的——只有基于Watermark水印 + EventTime机制的Flink才能完全满足数据的准确性要求。
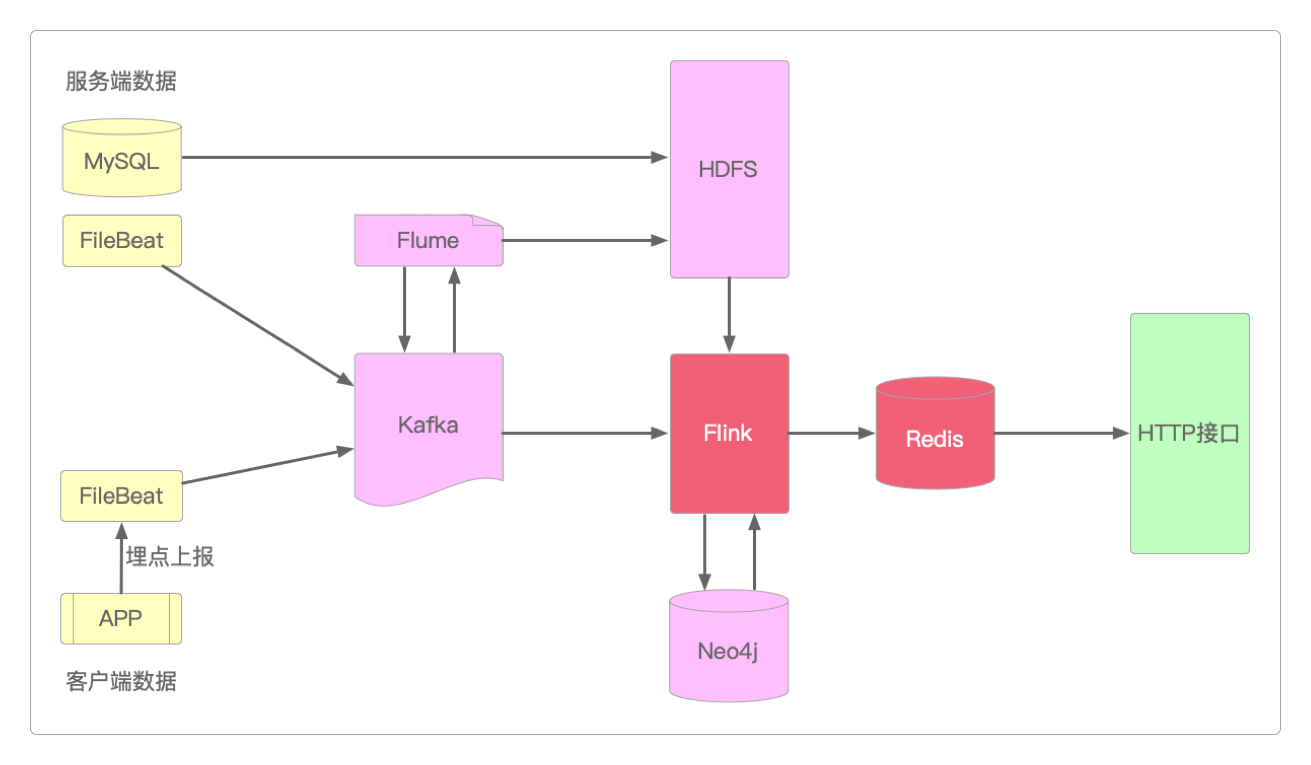
并且因为关系推荐数据即使有一些延迟,或者偶尔丢失数据,对推荐效果也没有多大影响,所以也可以将MySQL换成Redis,这样存储和查询的速度更快。
关注公众号后回复 关系推荐 即可获得三度关系推荐栏目剩余文章的访问密码。
