
数据源和采集架构
原创大约 3 分钟
数据源
所有需要用到的分析数据都来源于下面这几个地方。
服务端日志数据:实时的用户关注数据(也就是接口调用数据)、内容数据(例如,关闭直播时上报的相关指标)。客户端日志数据:就是APP通过埋点上报到服务端的日志数据,也就是用户行为数据,这里使用的是用户活跃数据,也就是只要用户打开APP就会上报一条活跃记录。
采集架构
为了让采集到的数据更加通用,将数据采集组件再进行切分。
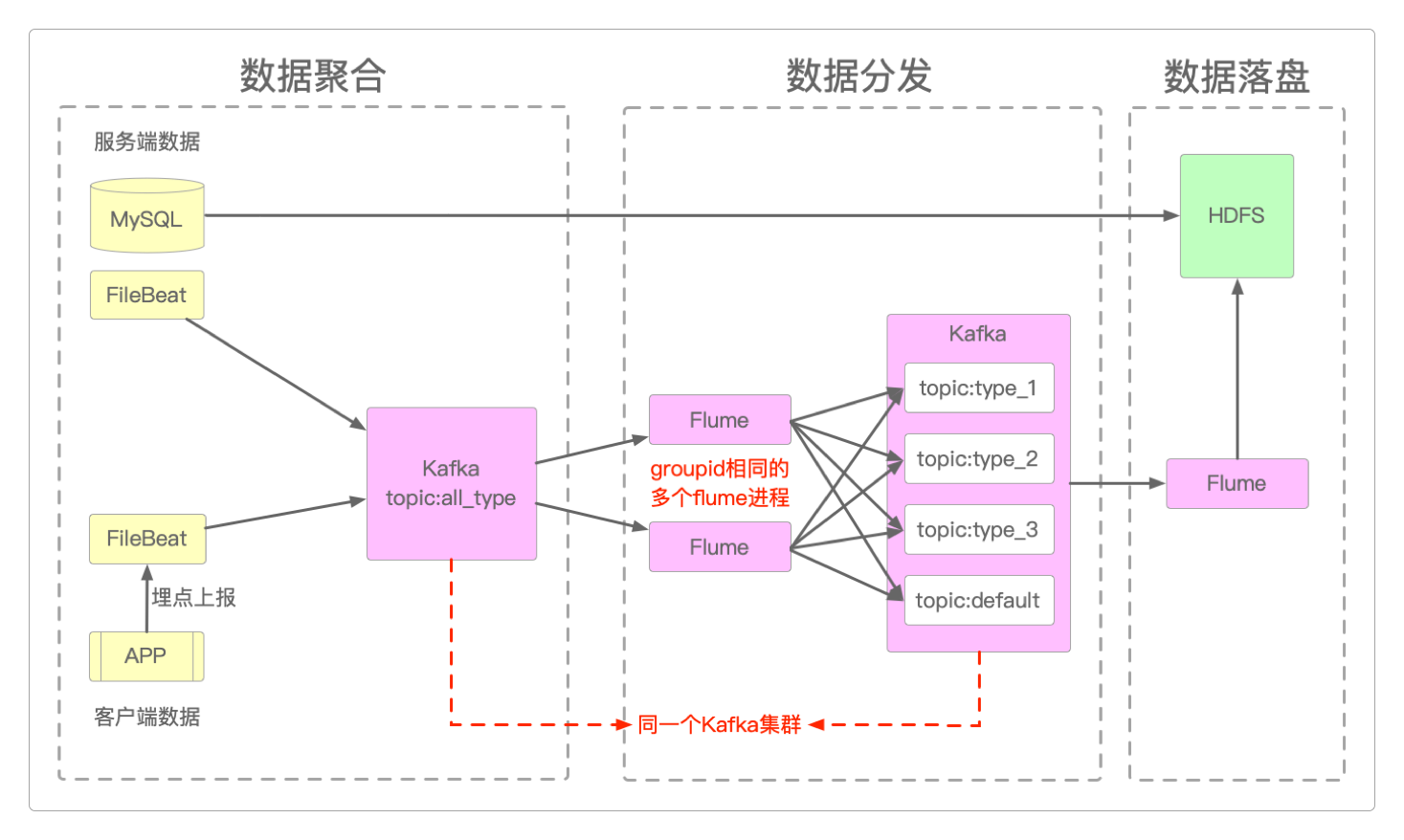
数据聚合:为了避免每次有新的业务指标到来时,就需要增加新的采集进程或者修改采集程序配置的问题,将所有的日志数据保存在特定目录中,并让Filebeat监控这个目录。所有的日志数据都使用JSON格式,并以type字段区分不同的业务种类。数据分发:所有的原始数据都会进入到Kafka的某个topic中,然后再由Flume按照指定的业务类别将它们重新发送到同一个Kafka的不同业务类型的topic。可以通过启动多个Flume进程来实现这种分发,前提是它们的groupid一致。
初始化
先在MySQL中初始化业务数据库数据,也就是初始化用户关注历史数据和博主/主播等级数据相关的数据表。
CREATE DATABASE IF NOT EXISTS recommend;
USE recommend;
-- t_follower_xx中的后缀xx是应对用户ID进行MD5计算后取模得到的值
-- 例如,某个MD5(用户ID) = 02,那么该用户的关注数据就会保存到t_follower_02
DROP TABLE IF EXISTS t_follower_00;
CREATE TABLE t_follower_00
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_01;
CREATE TABLE t_follower_01
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_02;
CREATE TABLE t_follower_02
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_03;
CREATE TABLE t_follower_03
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_04;
CREATE TABLE t_follower_04
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_05;
CREATE TABLE t_follower_05
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_06;
CREATE TABLE t_follower_06
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_07;
CREATE TABLE t_follower_07
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_08;
CREATE TABLE t_follower_08
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_follower_09;
CREATE TABLE t_follower_09
(
fid BIGINT NOT NULL,
uid BIGINT NOT NULL,
time TIMESTAMP NOT NULL
);
DROP TABLE IF EXISTS t_user_level;
CREATE TABLE t_user_level
(
id BIGINT NOT NULL,
uid BIGINT NOT NULL,
vexpress INT(11) NOT NULL,
vlevel INT(11) NOT NULL,
CREATEtime TIMESTAMP NOT NULL default CURRENT_TIMESTAMP,
updatetime TIMESTAMP NOT NULL default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
express INT(11) NOT NULL,
level INT(11) NOT NULL
);服务端日志数据中的实时用户关注数据格式如下。
{
"fid":"1",
"uid":"2",
"time":1718102763768,
"type":"follow", # follow表示关注,或者为unfollow,表示取消关注
"desc":"follow" # 同上
}而服务端内容数据,也就是上报的相关指标数据,格式如下。
{
"area":"asia_china",
"pv":183,
"uv":183,
"hosts":183,
"gifter":28,
"nofollow":257,
"length":5741,
"rating":"A",
"smlook":183,
"type":"live",
"gold":183,
"uid":2,
"nickname":"lixingyun",
"looktime":183,
"id":"208815658792108453",
"express":183,
"timestamp":1718102763768
}最后,客户端日志数据也都保存在/var/logs/中,它们的格式如下。
{
"uid":"1",
"version":"1.2.3",
"country":"China",
"ip":"102.247.59.36",
"timestamp":1718102763768,
"type":"user_active"
}和前面的Hive离线数据仓库一样,以上所有的这些数据也都可以通过ChatGPT生成。
感谢支持
更多内容,请移步《超级个体》。