
数仓项目背景
项目背景
这是很早之前开发过的一个数仓项目,现在将它还原出来,以作记录和分享。
当用户使用PC、APP或者小程序访问电商系统时,会通过埋点接口记录用户行为,这被称之为客户端记录数据。
同理,除了埋点记录的数据,业务系统也会有对应的操作行为,例如,用户下单或者取消支付,这被称之为服务端记录数据。
因此,针对同一个同户行为,可能会有两条数据来记录它,这两种类型的数据虽然都记录的是同一个用户行为,但应用场合是不同的。
客户端记录数据:可满足按分钟级甚至秒级来实时统计用户行为的需求,但统计数据本身可能会有遗失或不够准确,因为它不像业务系统会有各种一致性、完整性和安全性的保证,它适用于查看用户行为趋势,而不是准确的行为结果的汇总与聚合,例如,用户每日的消费总金额。服务端记录数据:和客户端记录数据应用场景刚好相反,它适用于查看用户行为结果的汇总与聚合,而非行为趋势。例如,用户每日消费的真实的总金额就只能通过业务系统的数据来汇总,而非埋点数据。
为了消除这种不一致,统一客户端记录数据和服务端记录数据,就必须有一个地方能够对平台中所有的数据进行整合,为所有部门和人员提供一个统一的、规范的数据访问入口,让所有基于数据的计算都是基于相同的数据源进行的。
经过这种整合以后,计算出来的各种指标就不会再有不同的结果了。
而且,一个完善且合理的数据仓库也是整个大数据系统中重要的一环,更高层次的数据分析、数据挖掘等工作都会基于数据仓库进行。
技术选型
基本上,任何数据仓库都需要具备下面这些功能组件。
数据采集组件:采集各种数据源中的数据,例如,MySQL数据、文档数据、日志数据等。通常会用到 Flume、Sqoop、Logstash或Filebeat等中间件,而数据采集方式也有两种。数据本地采集:直接在产生数据的业务服务中采集。例如,直接在订单服务器中部署Flume,采集它产生的日志数据,然后传输到远程数据采集组件里。相对于数据采集组件来说,这是一种推的方式。独立服务采集:部署一台独立的数据采集服务器,专门从多个不同的业务服务中采集数据。相对于数据采集组件来说,这是一种拉的方式。

数据采集方式的技术选型 数据计算组件:对原始数据进行清洗和计算。常规组合就是Hive + Spark(或者Flink、Clickhouse)。
整体架构
典型的数据仓库会划分为如下的几个层级。
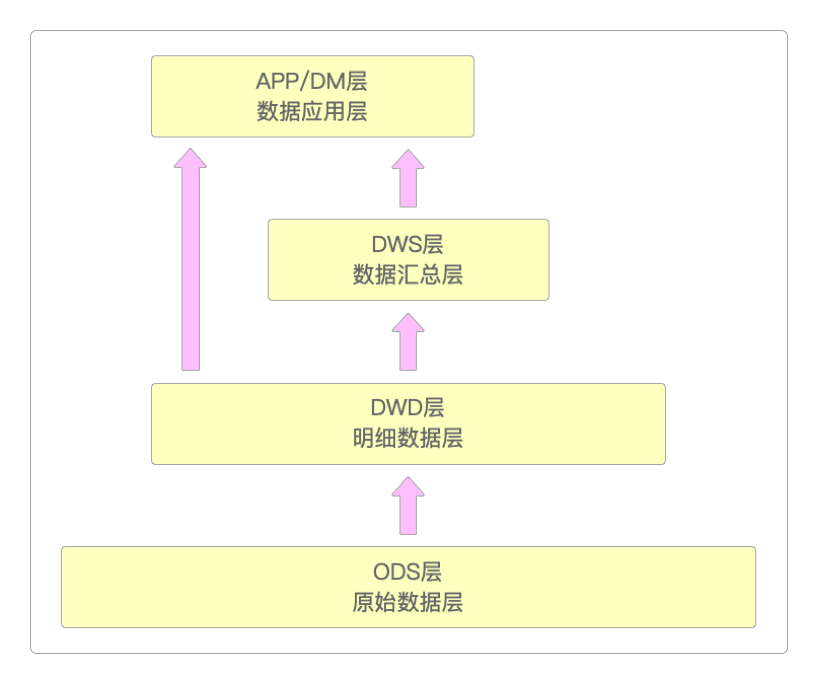
这样划分的好处在于。
显然,这样划分出来的整体数据结构非常清晰。
当出现问题时可以快速定位,例如,有利于数据血缘关系的追踪。
不同层次之间职责清晰,可以减少重复开发。
因为每一层关注的问题比较聚焦,就可以把复杂的问题简单化。
屏蔽不同层级业务之间的影响。
而在用户行为数仓这个案例中,数据仓库的整体架构设计如下。
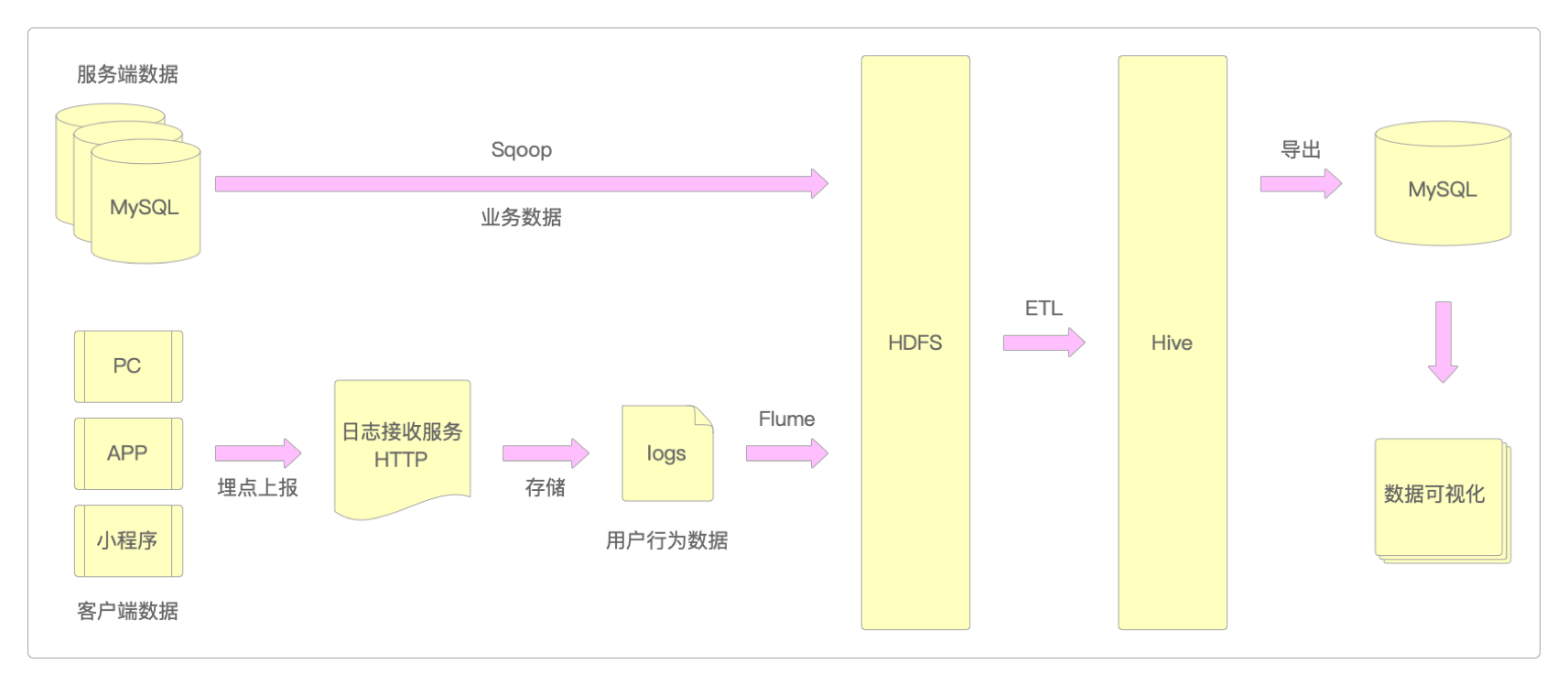
因为要统一
客户端和服务端的记录数据,所以需要同时对它们进行采集,统一采集到HDFS中。服务端数据就是商品详情、订单信息之类的数据,这些数据一般都存储在MySQL之类的关系型数据库中,这类数据主要通过Sqoop进行采集。客户端数据就是用户在网站、APP或小程序等客户端上的滑动、点击、浏览、停留时间之类的用户行为数据,这些数据通常会以埋点的形式直接上报。这种类型的数据没有事务性要求,并且对数据的完整性要求也不高,就算丢失一些数据,对整体结果影响也不大。这类数据主要通过HTTP接口进行传输。
资源规划


对生产环境资源规划的一点说明。
如果
NameNode开启了HA,就可以不需要SecondaryNameNode进程了。NameNode需要使用单独的机器,并且内存配置最好大一点,建议128G。DataNode和NodeManager需要部署在相同的集群上,这样可以实现数据本地化计算。日志接口服务器需要使用至少两台,便于实现负载均衡及故障转移,保证数据接收服务的稳定性。
MySQL需要单独部署,至少两台,一主一从。
Zeppelin可以单独部署在一台普通配置的机器上。
Azkaban至少部署三台,一主两从。
另外补充几点。
Hadoop集群规模需要根据数据量来预估。
假如集群机器通用配置为
64C-128G-8T。假如1天产生
1TB数据,那么宽泛一点估算1年就是370TB。集群默认3副本,那么数据量为
370TB×3=1110TB。预留
30%的空间,那么最终需要1110TB/70%≈1586TB。最终需要
1586TB/8TB≈199台服务器。
如果不用Docker来部署和编排,这么多服务器的管理工作会搞死人的。
但服务器的数量并不是一开始就要这么多,而是随着业务的开展动态扩容的。
关注公众号后回复 数据仓库 即可获得Hive离线数据仓库栏目剩余文章的访问密码。
