
HBase列式存储
基本概念
行式存储与列式存储
Hive作为一个数据仓库,它侧重的是离线的数据分析,也就它本质上是一个OLAP系统。
但咋大数据处理的过程中,不仅仅需要OLAP,有时候也需要执行实时的OLTP任务。
而Hive并不支持事务,且MySQL或者Oracle这种传统的OLTP数据库系统又无法处理上亿级别的数据量,所以就有了HBase。
HBase和Hive的共同点是,它们都基于Hadoop,都是分布式系统。但HBase有一个很重要的特点,它是基于列的存储。
大多数传统的RDBMS系统都是按照一行一行的方式来存储数据的,就像这样。
这种方式可以一次性查询出所有与指定条件相关的列,但如果只需要少量的列或者只需要查询某一列的内容时,它也需要进行全表扫描,然后再过滤出所需的列数据。
在数据量比较小的情况下,这种弊端还不明显。但在海量数据的查询中,就极其拖累整体性能了,这就是基于行存储逻辑的数据库系统最大的问题。
而在基于列存储的数据库系统中,数据是按照列的方式存储的,某一列的数据在存储介质中就是一组连续的地址。

行式存储中每一行的数据作为一个基础逻辑存储单元进行存储。列式存储中每一列的数据作为一个基础逻辑存储单元进行存储。
适用场景
列式存储非常适用于下面的应用场景。
在半结构化数据和非结构化数据中,其数据字段无法完全确定或杂乱无章,很难按一个概念去进行抽取时,就非常适合使用
列式存储来保存它们。例如,用户或商品的标签(tags)信息都是不断动态变化的,有多有的少,而且几乎都不同。在数据非常
稀疏时。这里的稀疏不是指的稀少,而是指设计了多个字段,却最终只使用了其中比较少的几个字段,那么那些值为NULL的字段会浪费大量的连续存储空间。需要记录多个不同版本的数据时。MySQL中每一条记录的值如果被更新的话,都会覆盖之前的数据,如果想保存历史数值,就只能通过插入多条记录的方式来实现。但这样一来,除了某一列的数据不同之外,其余列的数据都是完全一样的,这也造成存储空间的浪费和性能的损耗。而HBase却能对某一个记录保存任意数量的不同版本的值,也不会有多条记录存在。
需要存储和查询海量数据时。过去的RDBMS数据库都是通过主从分离或分库分表的方式来实现对大数据量的操作的。但HBase依托于Hadoop,就使得这一过程非常简单,只需要简单增加处理业务的机器就行了。
HBase逻辑存储模型
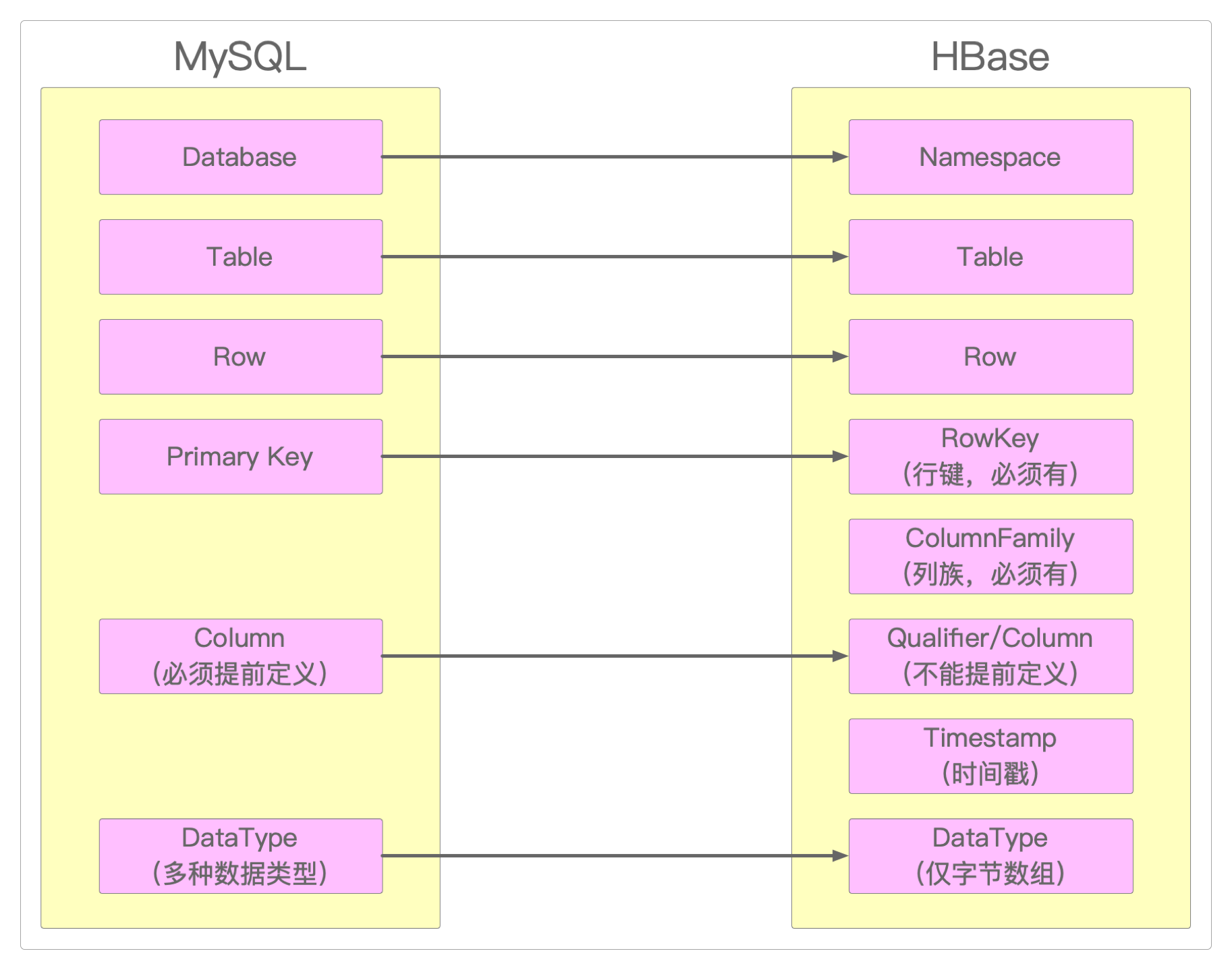
所谓逻辑存储模型就是操作HBase时所用到的组件及其概念。
例如,有下面的HBase数据。
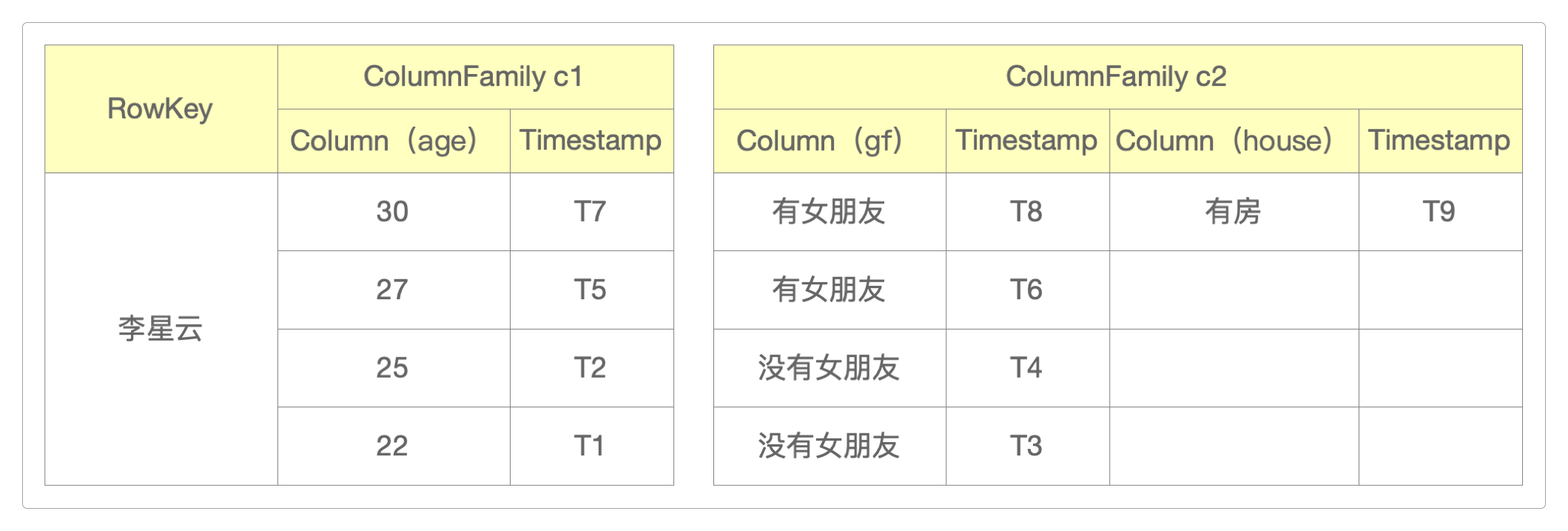
表中只有一条数据,它的
RowKey是李星云。表中有两个列族(
ColumnFamily)c1和c2。c1只有1列,而c2有两列,每个列都自带Timestamp。c1中的age列有4个历史版本,而c2的gf列也有4个历史版本,但house列只有1个历史版本。数据中时间戳(从
T1到T9)的顺序,就是数据插入的顺序。定位表中某一列的过程是:
Namespace-->Table-->RowKey-->ColumnFamily-->Column-->Timestamp。
所以从逻辑模型可以看出,HBase是三维有序存储的,所谓三维指的是RowKey、Column Key(ColumnFamily + Column)和Timestamp,这三个维度也都依照ASCII码表排序。
查询出来的会数据先按照
RowKey的升序排序。如果
RowKey相同,再按照Column Key升序排序。如果
RowKey和Column Key都相同,则按照Timestamp降序排序。
本机部署
官方已经给出了部署HBase单节点的方法,但文档并不完整。
根据官方给出的版本搭配关系,Hadoop 3.2.x搭配HBase 2.3.x或者2.4.x版本是比较合适的。
下载并解压HBase安装包。
> cd /home/work
> wget https://dlcdn.apache.org/hbase/2.4.18/hbase-2.4.18-bin.tar.gz
> tar xzvf hbase-2.4.18-bin.tar.gz
> cd hbase-2.4.18修改配置文件hbase-env.sh,在文件结尾处添加以下内容。
> cd vi conf/hbase-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_401再修改hbase-site.xml文件,修改下面的内容。
> cd vi conf/hbase-site.xml
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/work/volumes/hbase</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://172.16.185.176:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>修改完之后就可以启动HBase了。
> ./bin/start-hbase.sh
> jps
65092 HMaster
65966 Jps如果看到出现HMaster进程就算启动成功了,之后就可以在浏览器中访问http://172.16.185.176:16010/,或者通过命令行进行测试。
> ./bin/hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.4.18, ra1767f4d76859c0068720a6c1e5cb78282ebfe1e
Took 0.0017 seconds
hbase:001:0>如果启动或使用时不想看到日志冲突警告信息,可以这样做。
> cd /home/work/hbase-2.4.18/lib/client-facing-thirdparty
> mv slf4j-reload4j-1.7.33.jar slf4j-reload4j-1.7.33.bak感谢支持
更多内容,请移步《超级个体》。