
HBase底层技术机制

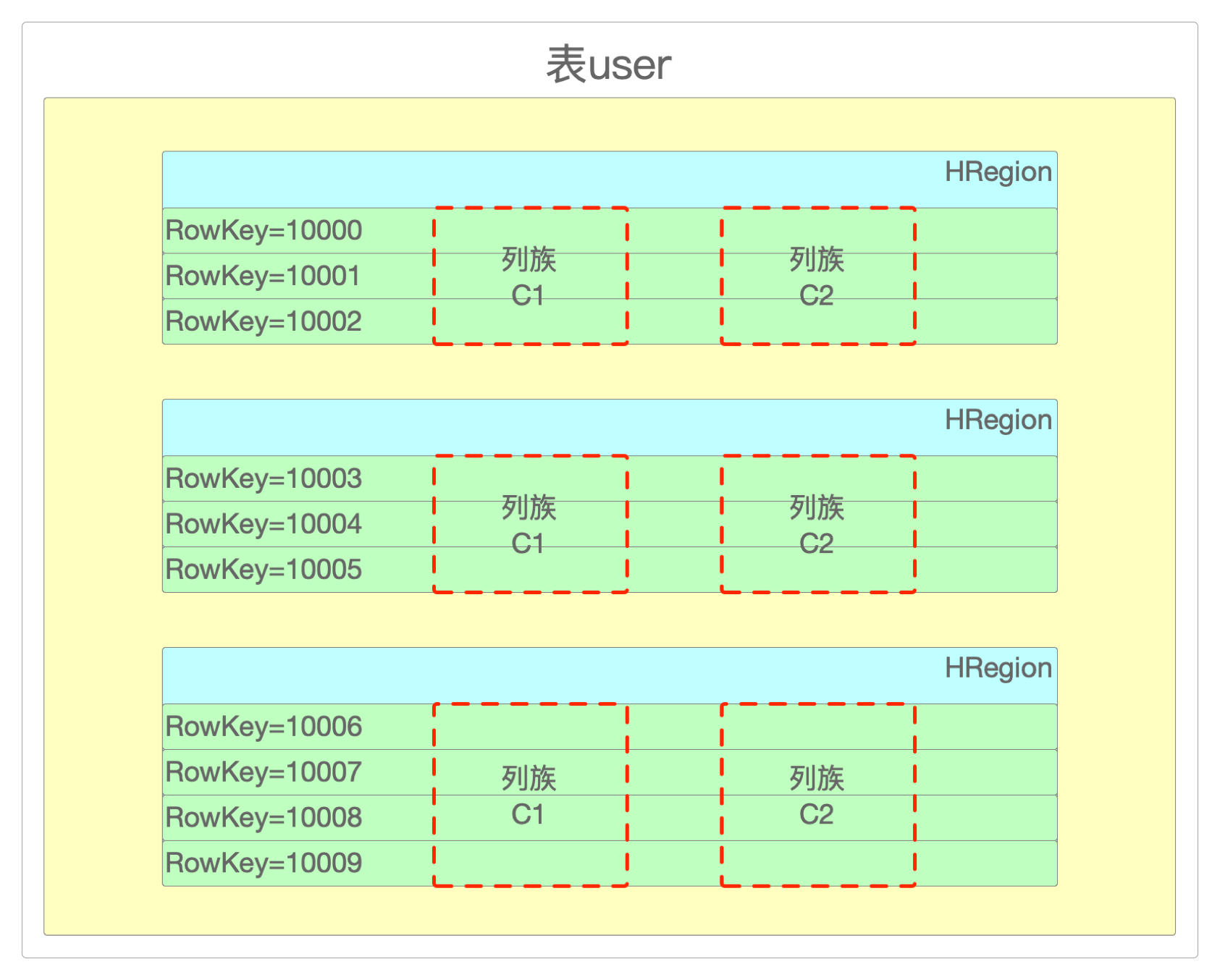
HRegion
每个
HRegionServer包含一个HLog和多个HRegion。HLog负责日志记录,针对HRegionServer的所有写操作(例如put、delete等)都会先记录到这个日志中,然后再把数据写到对应的HRegion。HRegion负责数据的存储,它的表面意思是区域,HBase表中的数据会按照行被横向划分为多个Region。每个
HRegion按照存储的最小RowKey和最大RowKey指定,也就是个HRegion包含的区间为[startRowKey, endRowKey),RowKey是按升序排列的。每一个
列族在HBase中都是一个单独的文件,对应一个Store,每个HRegion中都可能会有多个Store。
在向
HRegion写数据时,会根据指定的列族信息把数据写到不同的Store里。往
Store里写数据时,会先写入MemStore,也就是内存中专门存储Store一块区域。当内存的
MemStore写满之后,就会把数据持久化到StoreFile,然后再通过DFS Client写入到HDFS的DataNode中。
HRegion Split
由于HBase默认给每个新建的表只分配1个
HRegion,造成所有的读写都集中在一个HRegion上,进而产生读写热点问题。所以当表数据越来越多的时候,
HRegion会自动分裂(Split),保证每个HRegion不会太大,便于管理。
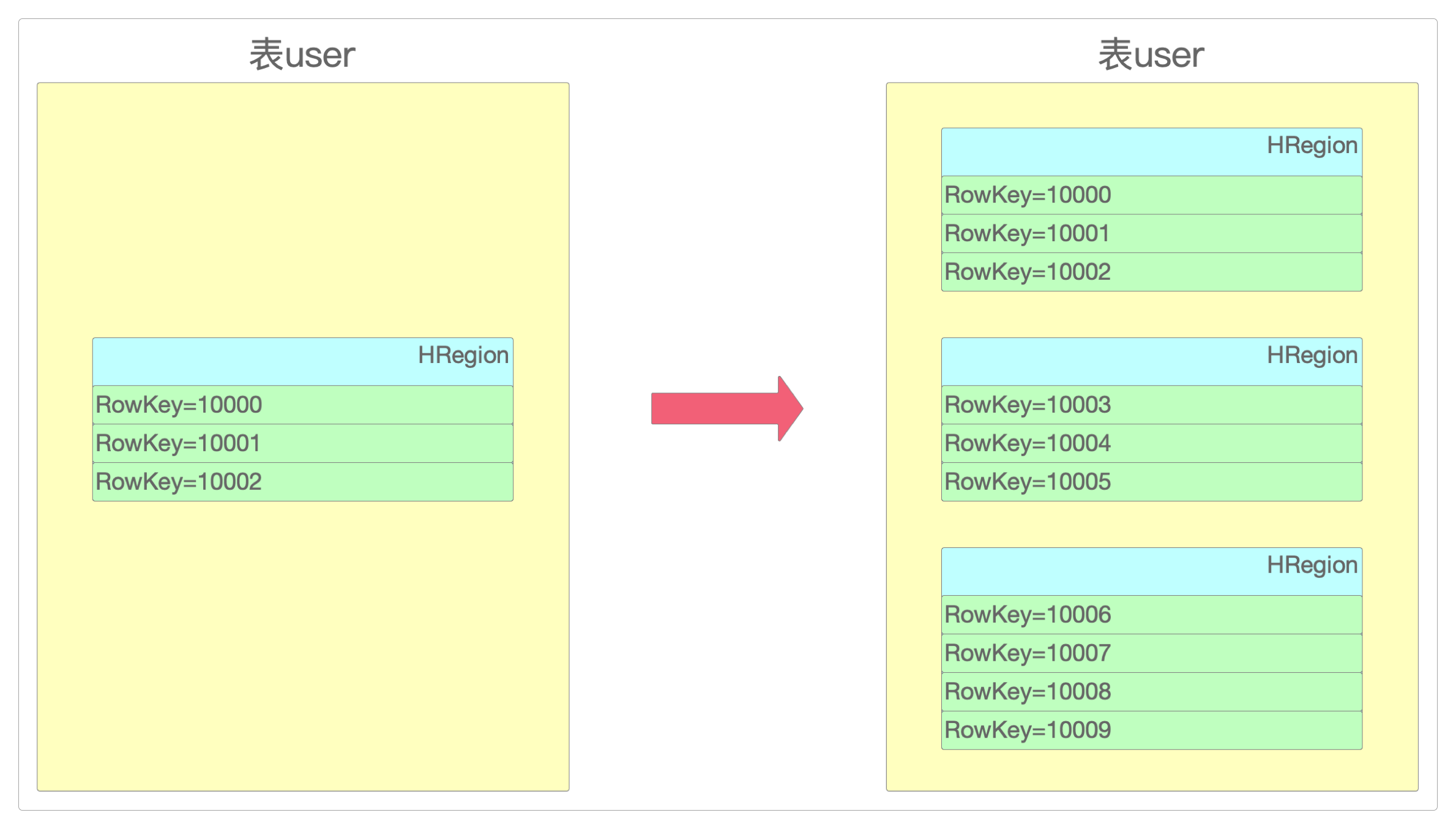
原始的
HRegion会被分裂成两个新的子HRegion,而自己则被清除。触发
HRegion Split的条件是这样的。ConstantSizeRegionSplitPolicy(HBase0.94版本以前的机制):HRegion中最大的HFile大于设置的阈值大小时被触发,阈值默认10GB。IncreasingToUpperBoundRegionSplitPolicy(HBase0.94~2.x版本默认机制):HRegion中最大的HFile大于设置的阈值大小时被触发,但阈值的大小不是固定的,而是会不断调整的,调整公式为:调整后阈值 =HRegion数量的3次方 × flushsize × 2,但这个不固定的值也有一个上限,通过hbase.hregion.max.filesize来指定。这种方式主要是为了让HRegion能够根据表的大小来自动调整数量。
HRegion Balance
当
HRegion分裂之后,就会涉及到HRegion的访问策略了。HMaster会对根据负载均衡策略重新均匀地分配HRegion所属的HRegionServer,最大化发挥分布式系统的优势。HBase目前支持两种
HRegion分配策略。DefaultLoadBalancer:它保证每个HRegionServer中的HRegion数量基本上相等,但如果有的HRegion数据多,有的数据少,就会造成访问不均衡的问题。StochasticLoadBalancer:这种策略比较复杂,因为它对6个方面的因素进行加权计算,算出一个代价值,用这个数值来评估当前HRegion分布是否均衡,越均衡代价值就越低。这个6个因素包括:每台服务器读请求数、每台服务器写请求数、HRegion个数、移动数据的代价、数据Locality和每张表占用HRegion数量的上限。
WAL预写日志
WAL是Write-Ahead-Logging,也就是预写日志的简称。所有只要是有写日志这一环节的存储系统,不管是MySQL、Hadoop还是HBase,日志的最主要作用就是用于
容灾备份或灾难恢复。WAL的作用就类似于MySQL中的Binlog,所以一旦写入WAL失败,就意味着整个写操作是失败的。HLog就是WAL的实现类。WAL保存在HDFS中,其目录为/hbase/WALs,针对集群中的每台机器,它都有一个与之对应的目录。因为
MemStore会定期将数据写入StoreFile,所以WAL并不会保存所有的写操作,而且它自身也有数据失效策略。
HFile
HFile其实就是HDFS中保存的文件,但它有自己特殊的格式。HFile由6个部分组成。Data:由key-value组成的键值对。Meta:元数据块,存储用户自定义的key-value。File Info:记录文件信息的定长元数据。Data Index:数据块索引,记录每个Data的起始索引。Meta Index:元数据索引,记录每个Meta的起始索引。Trailer:一个定长的指向其他数据块的起始点,它类似于一个尾部指针。
当
MemStore写满时,就会持久化生成一个StoreFile,这个StoreFile的底层就是HFile。当
HFile数量达到一定阈值后,HBase会对它们执行合并(Compaction)操作,把多个HFile合并成一个,而执行合并操作时,会产生大量的I/O操作。HFile的合并分为Major(大合并)和Minor(小合并)两种类型,可以把它们理解为JVM的Full GC和Young GC。Minor:只做部分文件的合并,过程较快且I/O相对较低。Major:将HRegion下所有的HFile合并成一个文件,由于涉及到大量的I/O操作,所以对HBase的性能会产生很大影响,生产环境中需要关闭自动触发大合并的功能,改为手动在业务低谷期触发。
BloomFilter
BloomFilter是布隆过滤器,它是一种设计巧妙的概率型数据结构,可以过滤出某样一定不存在或者可能存在的东西。它是HBase中的高级功能,可以减少特定访问模式(
get/scan)下的查询时间,准确判断HFile中是否包含所需数据,提高吞吐量。所以HBase会在生成
HFile时,包含一份BloomFilter结构的数据集合。
感谢支持
更多内容,请移步《超级个体》。