
操作库和表
原创大约 7 分钟
数据库的常见操作
Hive针对库的操作比针对表的操作要少,但操作表之前得先建库。
> cd /home/work/hive-3.1.3
> ./bin/hive
# 查看数据库列表
hive (default)> show databases;
# 创建数据库
hive (default)> create database testdb;
# 在指定位置创建数据库
hive (default)> create database testlocal location '/home/work/volumes/hive/testlocal'
# 选择数据库
hive (default)> use testdb;
# 删除数据库(默认数据库是无法删除的)
hive (default)> drop database testdb;所有的数据库个数据表默认都存储在${HIVE_HOME}/conf/hive-site.xml的参数值hive.metastore.warehouse.dir中,也就是/user/hive/warehouse中,可以在Web UI中输入/user/hive/warehouse看到。
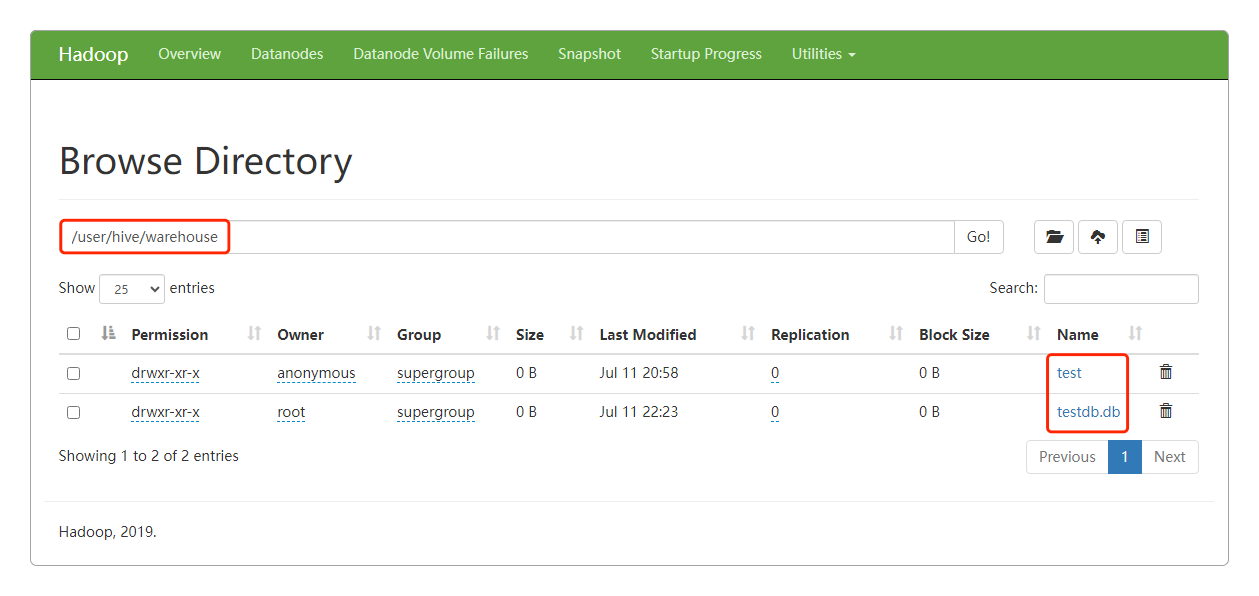
而且通过查看MySQL,也就是安装Hive时指定的Metastore外置存储库,也能看到保存的数据库和数据表。

数据表的常见操作
> cd /home/work/hive-3.1.3
> ./bin/hive
# 创建数据表
hive (default)> create table test(id int);
# 查看表信息
hive (default)> desc test;
OK
id int
Time taken: 0.578 seconds, Fetched: 1 row(s)
# 查看建表语句
hive (default)> show create table test;
OK
CREATE TABLE `test`(
`id` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoop:9000/user/hive/warehouse/test'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1679232163')
Time taken: 0.318 seconds, Fetched: 14 row(s)
# 修改表名
hive (default)> alter table test rename to testbak;
OK
Time taken: 0.725 seconds
# 加载数据
hive (default)> load data local inpath '/home/work/volumes/hive/data/testbak.data' into table testbak;
OK
Time taken: 0.648 seconds
# 查询数据
hive (default)> select * from testbak;
OK
1
2
3
4
5
Time taken: 0.284 seconds, Fetched: 5 row(s)
# 可以直接上传数据到表所在的hdfs目录,效果是一样的
> hdfs dfs -put /home/work/volumes/hive/data/testbak.data /user/hive/warehouse/testbak/testbak2.data
# 再次执行查询
hive (default)> select * from testbak;
OK
1
2
3
4
5
1
2
3
4
5
Time taken: 0.298 seconds, Fetched: 10 row(s)
# 清空表数据
hive (default)> truncate table testbak;
OK
Time taken: 0.343 seconds
# 表增加字段(只有表的序列化方式为native xxxSerDe(DynamicSerDe, MetadataTypedColumnsetSerDe, LazySimpleSerDe和ColumnarSerDe)才能删除字段,否则会报错)
hive (default)> alter table testbak add columns (age int);
OK
Time taken: 0.263 seconds
# 查询数据
hive (default)> select * from testbak;
OK
1 NULL
2 NULL
3 NULL
4 NULL
5 NULL
1 NULL
2 NULL
3 NULL
4 NULL
5 NULL
Time taken: 0.298 seconds, Fetched: 10 row(s)
# 删除表并重新创建
hive (default)> drop table testbak;
hive (default)> create table test(
id int comment "id",
name string comment "姓名"
) comment "测试表";
OK
Time taken: 0.244 seconds
# 查看表信息(注释乱码,解决乱码问题可以将Metastore中存储的相应的数据表的编码改成utf8)
hive (default)> desc test;
OK
id int id
name string ??
Time taken: 0.218 seconds, Fetched: 2 row(s)
# 指定行和列的分隔符
hive (default)> drop table test;
hive (default)> create table test(
id int comment "id",
name string comment "姓名",
birthday date comment "出生年月日",
online boolean comment "是否在线"
) comment "测试表";
OK
Time taken: 0.192 seconds
# 加载数据
hive (default)> load data local inpath '/home/work/volumes/hive/data/test.data' into table test;
hive (default)> select * from test;
OK
NULL NULL NULL NULL
NULL NULL NULL NULL
NULL NULL NULL NULL
Time taken: 0.275 seconds, Fetched: 3 row(s)
# 查询出来的数据全是NULL,因为没有指定列的分隔符(Hive默认的列分隔符是`\001`)
# 删除重新创建,指定行列分隔符
hive (default)> drop table test;
hive (default)> create table test(
id int comment "id",
name string comment "姓名",
birthday date comment "出生年月日",
online boolean comment "是否在线"
) comment "测试表"
row format delimited
fields terminated by '\t'
lines terminated by '\n';
# 再次加载数据(即使数据类型错误,查询也不会报错,而是给出一个NULL值)
hive (default)> load data local inpath '/home/work/volumes/hive/data/test.data' into table test;
# 查询数据
hive (default)> select * from test;
OK
1 李星云 2023-01-01 true
2 王林 2023-02-01 false
3 萧炎 2023-03-01 NULL另外,关于注释的乱码问题可以这样解决。
-- 进入MySQL,修改Metastore对应表编码的语句
-- 存储Metastore的数据库,这里是hive
use ${database};
-- 如果数据库编码设置为utf8bm4的话,也可以改成utf8bm4
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(5120) character set utf8;
-- 如果表创建了分区还要再执行下面两条命令
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(5120) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(5120) character set utf8;修改之后再重新创建表,注释就能正常显示中文了。
表的数据类型
- 基本数据类型,包括
INT、STRING、BOOLEAN和DOUBLE等。
| 数据类型 | 描述 |
|---|---|
| TINYINT | 1字节有符号整数,范围:-128 ~ 127 |
| SMALLINT | 2字节有符号整数,范围:-32768 ~ 32767 |
| INT/INTEGER | 4字节有符号整数,范围:-2147483648 ~ 2147483647 |
| BIGINT | 8字节有符号整数,范围:-9223372036854775808 ~ 9223372036854775807 |
| FLOAT | 4字节单精度浮点数 |
| DOUBLE | 8字节双精度浮点数 |
| DECIMAL | 任意精度带符号小数 |
| TIMESTAMP | 时间戳,纳秒精度 |
| DATE | 日期,格式为yyyy-mm-dd |
| STRING | 字符串,字符串长度只能为1~65355 |
| VARCHAR | 字符串,长度不定,有上限 |
| CHAR | 字符串,固定长度 |
| BOOLEAN | true/false |
| BINARY | 变长的二进制数据 |
- 复合数据类型,包括
ARRAY、MAPS和STRUCT等。
| 数据类型 | 描述 |
|---|---|
| ARRAY | 存储同类型数据,ARRAY<data_type> |
| MAP | key-value,key必须为原始类型,value可以是任意类型,MAP<key, value> |
| STRUCT | 类型可以不同,STRUCT<col_name:data_type[COMMENT col_comment], ...> |
使用ARRAY类型
> cd /home/work/hive-3.1.3
> ./bin/hive
# 通过ARRAY来存储用户的兴趣爱好
hive (default)> create table t_array(
id int comment "id",
name string comment "姓名",
hobby array<string> comment "爱好"
) comment "复合数据类型"
row format delimited
fields terminated by '\t'
collection items terminated by ','
lines terminated by '\n';
# 加载数据
hive (default)> load data local inpath '/home/work/volumes/hive/data/user.data' into table t_array;
# 查询数据
hive (default)> select * from t_array;
OK
1 lixingyun ["swing","sing","traveling"]
2 wanglin ["music","football"]
Time taken: 0.291 seconds, Fetched: 2 row(s)
# 查询数据
hive (default)> select id, name, hobby[2] from t_array;
OK
1 lixingyun traveling
2 wanglin NULL
Time taken: 0.269 seconds, Fetched: 2 row(s)使用MAP类型
> cd /home/work/hive-3.1.3
> ./bin/hive
# 通过MAP来存储用户账户价值
hive (default)> create table t_map(
id int comment "id",
name string comment "姓名",
value map<string, int> comment "价值"
) comment "复合数据类型"
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
# 加载数据
hive (default)> load data local inpath '/home/work/volumes/hive/data/uservalue.data' into table t_map;
# 查询数据
hive (default)> select * from t_map;
OK
1 lixingyun {"balance":188,"redpack":5,"point":10086}
2 wanglin {"balance":1379,"redpack":27,"point":4000}
Time taken: 0.259 seconds, Fetched: 2 row(s)
# 查询数据
hive (default)> select id, name, value["balance"] AS balance, value["redpack"] AS redpack from t_map;
OK
1 lixingyun 188 5
2 wanglin 1379 27
Time taken: 0.272 seconds, Fetched: 2 row(s)使用STRUCT类型
> cd /home/work/hive-3.1.3
> ./bin/hive
# 通过STRUCT来存储用户地址信息
hive (default)> create table t_struct(
id int comment "id",
name string comment "姓名",
addr struct<live:string, work:string> comment "地址"
) comment "复合数据类型"
row format delimited
fields terminated by '\t'
collection items terminated by ','
lines terminated by '\n';
# 加载数据
hive (default)> load data local inpath '/home/work/volumes/hive/data/useraddr.data' into table t_struct;
# 查询数据
hive (default)> select * from t_struct;
OK
1 lixingyun {"live":"北京","work":"上海"}
2 wanglin {"live":"武汉","work":"深圳"}
Time taken: 0.279 seconds, Fetched: 2 row(s)
# 查询数据
hive (default)> select id, name, addr.live AS live from t_struct;
OK
1 lixingyun 北京
2 wanglin 武汉
Time taken: 0.154 seconds, Fetched: 2 row(s)综合使用复合类型
> cd /home/work/hive-3.1.3
> ./bin/hive
# 通过STRUCT来存储用户地址信息
hive (default)> create table t_multiple(
id int comment "id",
name string comment "姓名",
hobby array<string> comment "爱好",
value map<string, int> comment "价值",
addr struct<live:string, work:string> comment "地址"
) comment "复合数据类型"
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
# 加载数据
hive (default)> load data local inpath '/home/work/volumes/hive/data/usermultiple.data' into table t_multiple;
# 查询数据
hive (default)> select * from t_multiple;
OK
1 lixingyun ["traveling","sing","swing"] {"balance":80,"point":90,"redpack":100} {"live":"北京","work":"上海"}
2 wanglin ["games","swming"] {"balance":89,"redpack":70,"point":88} {"live":"武汉","work":"深圳"}
Time taken: 0.308 seconds, Fetched: 2 row(s)从MySQL迁移到Hive
有这样的三张MySQL数据表。
> create table user (
id int primary key,
username varchar(32)
);
> create table address (
id int primary key,
userid int,
province varchar(64),
city varchar(64)
);
> create table contact (
id int primary key,
userid int,
father varchar(64),
mother varchar(64)
);将它们迁移到Hive有两种方式。
直接通过建表和插入数据的
SQL语句将三张表同步复制到Hive。优点是简单易行,但如果表中数据量大且有JOIN连接时,MapReduce的运算会非常慢。把这三张表整合成一张大宽表,将所有数据
关联好之后放到一起。所谓的关联好就是三张表做笛卡尔积(LEFT OUTER JOIN+RIGHT OUTER JOIN+UNION ALL),就像这样。
SELECT u.*, a.*, c.*
FROM user AS u
LEFT OUTER JOIN address AS a
ON u.id = a.userid
LEFT OUTER JOIN contact AS c
ON u.id = c.userid
UNION ALL
SELECT u.*, a.*, c.*
FROM user AS u
RIGHT OUTER JOIN address AS a
ON u.id = a.userid
RIGHT OUTER JOIN contact AS c
ON u.id = c.userid这种方式的优点是后期使用时会比较快,但迁移成本较高,有些业务逻辑也得改(从查三张表变成只查一张表)。
- 第三种方式就是将前两种结合到一起:前期先快速同步复制三张表,后期在此基础之上再执行整合成大宽表的做法。
感谢支持
更多内容,请移步《超级个体》。