
幂等性
问题的产生
在过去的单机应用系统环境里,功能调用的结果只有两种状态,要么成功,要么失败。因为所有计算可用的资源,例如CPU、内存和磁盘,要么在同一台计算机中,要么在同一个物理上狭小且集中的局域网内。
但将应用部署到互联网上,或开发一个互联网应用时,应用系统就出现了第三种状态:超时(又叫Timeout),这是由网络节点运行的不可预测性和故障的突发性所造成的,并且这种状况无法避免。
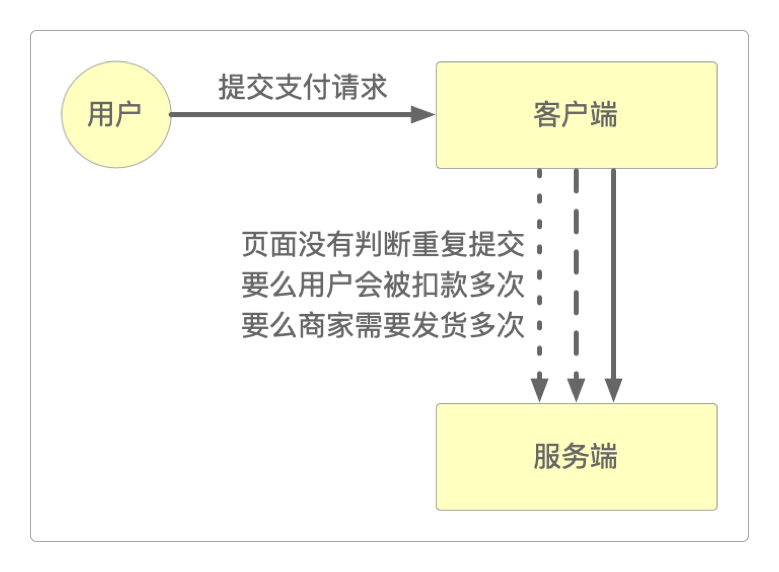
在前后端代码分离和职责分离(接口与实现分离)已成为主流开发模式的前提下,这种超时现象又引起了另一个让工程师们头疼的问题:重复提交。
最典型的重复提交问题是这样产生的。
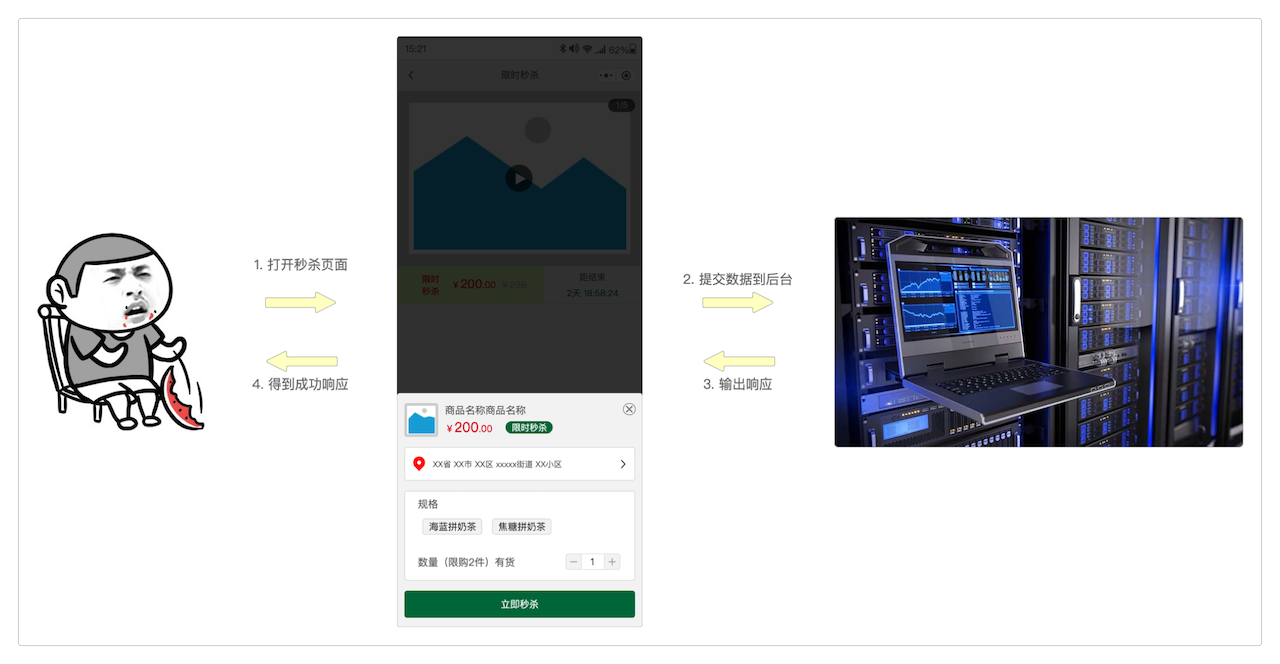
当网络情况良好的时候,每一步都能正常工作:网络没有断掉、后台没有崩溃、功能没有异常,就像上面图片中显示的那样。
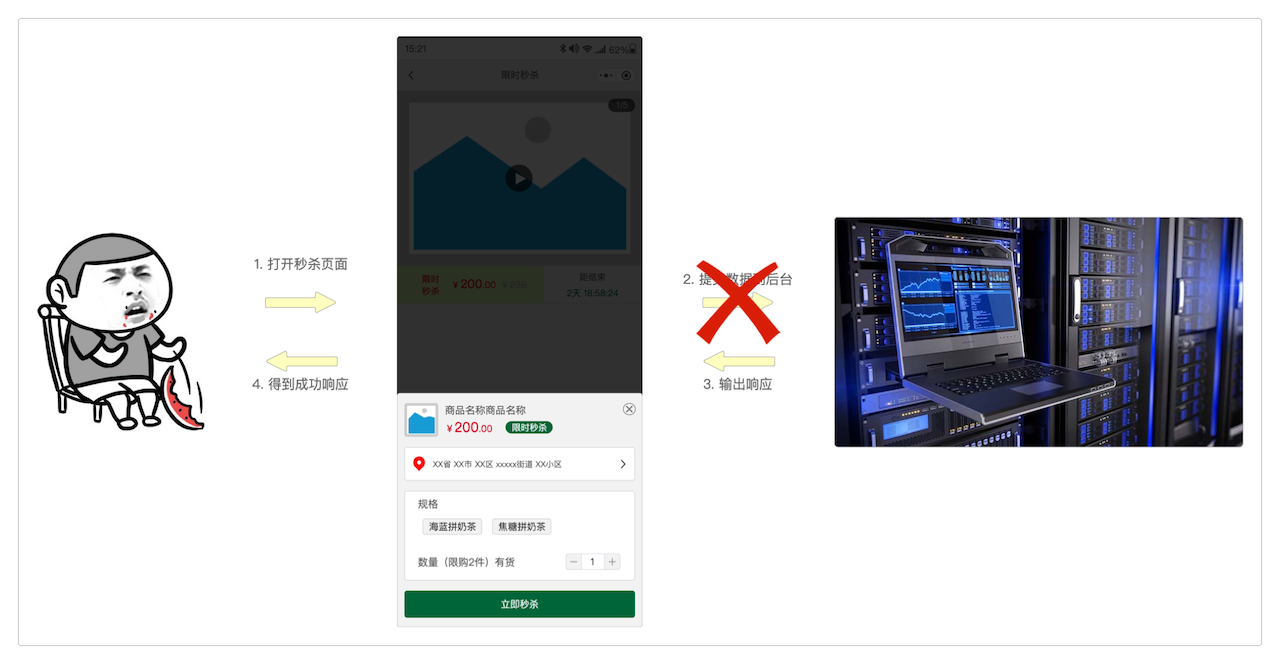
但是很不凑巧,就在提交数据到服务器,或者是服务器输出响应的时候,网断了。
因为客户端既发送不了数据,也收不到服务器的返回的响应,所以整个页面就在这里卡住了。而此情此景下,几乎每个人都会下意识地反复点击秒杀按钮,不断尝试重复发送。
可能网络只是卡住了那么一小会儿,但在此期间用户却已经连续点击很多次了。也就是说,用户在这一小段时间内又连续加塞了几个一模一样的请求:提交地址一样,提交数据一样,提交方式也一样——重复提交就此产生。
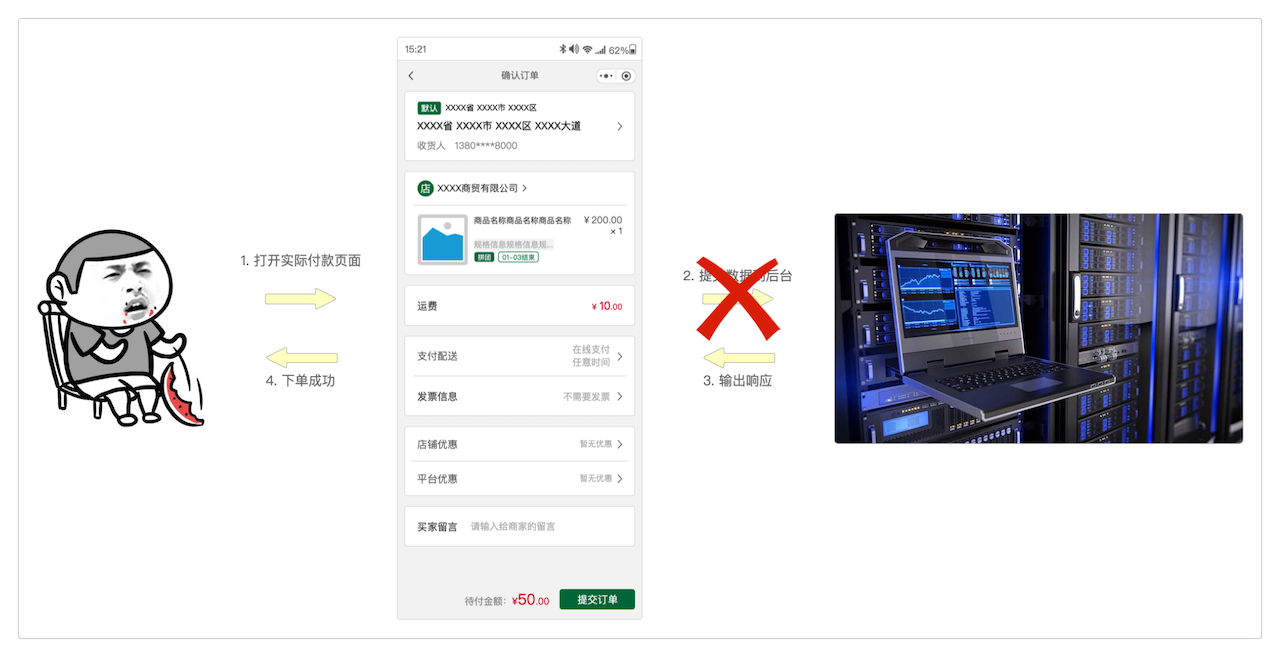
如果只是单纯参与秒杀活动,问题还不大,无非就是暂时多占几个排队名额罢了,用户和商家都不损失什么。
而一旦需要用户付出真金白银,需要商家交付货真价实的商品时,这种重复提交就麻烦了。
可能用户
重复提交了几笔订单,就要为每笔订单都付一次钱,但却只能买到单笔订单所对应的商品。可能用户
重复提交了几笔订单,只付了一笔订单的钱,但商家却不得不寄运每笔订单所对应的商品。
什么是幂等
在数学上,把那些无论执行多少次结果都不会变的函数叫做幂等函数(Idempotence),它具有下面这样的形式。
f(f(x)) = f(x)
而计算机本质上就是进行二进制的数学运算工具,所以在编程中,幂等函数(或幂等方法)用通俗的话来说就是 某个操作不管执行多少次,对资源造成的影响都是一样的,但是允许有不同的返回值。
这里面的客户端可以是浏览器、移动端或小程序,不管哪种,表现出来的结果都是一样的。
但其实幂等和重复提交是两个不同的概念,而且在应用软件开发中的重复提交问题出现之前,幂等这个数学概念就已经存在很多年了。
也就是说,重复提交有可能是幂等的,也有可能不是。而幂等也不意味着没有重复提交,它们之间没有必然关联。
例如,虽然页面上有重复提交,但是不管提交多少次,结果都是一样的(用户只付一次钱,商家只发一次货),那么这个功能就是幂等的。
解决办法
网上有很多种解决重复提交问题的办法,也就是实现幂等的方法,但其核心思想只有一个,那就是在操作前先预设一个标志位,然后再通过这个标志位的状态来判断操作是否发生了重复,从利用Zookeeper或Redis的分布式锁,到数据库锁,再到业务服务的Token校验机制,都是这种思想的体现。
下面是这些方案的伪代码实现。
Zookeeper分布式锁
// 生成唯一订单号,例如:orderId = Hash(商品ID + 金额 + 数量 + 用户ID)
String orderId = orderService.generateId();
String path = "/" + orderId;
try {
// 只需要判断节点是否存在即可,无需做任何操作,因为它只是一个标志位
if (zk.exists(path)) {
// 节点已经存在,说明本次为重复提交,直接返回
return true;
}
} catch (KeeperException.NoNodeException e) {
// 节点不存在
return false;
} catch (Exception e) {
// 其他异常,判定节点可能存在
return true;
}
......
// 如果节点不存在则创建临时节点,并同时提交订单
synchronized("锁") {
zk.create(path, ...);
// TODO:提交订单信息
}
......
// 在另外的定时任务中读取订单ID,然后统一删除所有临时节点
// 一般订单的有效期是30分钟,所以定时任务最好设置在提交订单的31~35分钟后执行
synchronized("锁") {
zk.delete(path, -1);
}这里面唯一的问题在于最后一个catch块中的异常处理:有可能节点不存在,可以继续处理,但此时程序已经返回了。
虽然这会导致订单创建不成功,但至少要比重复提交带来的影响小得多。
当对于Zookeeper这种需要自行手动释放的锁,Redis用起来会更方便,而且也更简单一些。
Redis分布式锁
// 生成唯一订单号的方式同zookeeper
orderId = orderService.generateId();
......
try {
Object value = jedis.get(orderId);
// 锁已经存在,说明本次为重复提交,直接返回
if (null != value) {
return true;
}
} catch (Exception e) {
// 出现异常,判定锁可能存在
return true;
}
// 如果锁不存在则创建锁,并同时提交订单
synchronized("锁") {
// 设置key的过期时间为32分钟
jedis.setex(orderId, 1920, 1);
// TODO:提交订单信息
}至于使用Token的 方式和Redis锁的方式一模一样,只不过存储的是Token而非订单号罢了。
数据库锁
begin transaction;
-- 读取并锁住一行订单记录
SELECT * FROM t_orders WHERE id = 21885896215478332125486 FOR UPDATE;
-- 中间是执行业务逻辑的业务代码同前面类似,存在则返回,不存在则创建
-- 更新订单记录
UPDATE t_orders set amount = amount - 1 where id = 21885896215478332125486;
end transaction;至于乐观锁,侵入性更大,需要添加一个单独的version字段,实际开发中极少应用。
Zookeeper锁、Redis锁、Token本质上同属于一类分布式锁的解决方案。
数据库锁又属于另外一类解决方案,这种方案的弊端在于以下三点。
一是侵入性太高,需要改造
SQL查询,尤其是乐观锁,需要添加与业务无关的字段。二是只适用于
UPDATE更新操作,因为它的名字就是FOR UPDATE而不是FOR INSERT或FOR DELETE。三是它需要事务的加持,如果事务处理的很慢,会严重影响性能。
除此以外,都是它们的衍生方法。
但实际生产环境中,用的最多的还是Redis锁,因为它的侵入性最小、灵活性最高(CRUD都适用),而且实现起来也简单方便。
一些常识
实际上,并不是所有的操作都会有重复提交的问题。例如,普通查询(Normal SELECT)操作,不管SELECT1次,还是100次,还是1亿次,它绝不会对资源造成任何影响。
所以可以说,普通查询(Normal SELECT)操作天然就是幂等的。
类似于普通查询(Normal SELECT)这样天然幂等的操作还包括这些。
删除(DELETE):不管是物理操作还是逻辑操作,无论执行多少次,除了返回值不同,对数据造成的效果是一样的,也是幂等操作。创建(CREATE)。更新(UPDATE)。
前面之所以要强调普通查询(Normal SELECT),是因为还有一类具有半幂等性的计算查询(Calculate SELECT)操作。
> SELECT * FROM table WHERE createtime <= new Date();类似于这种日期范围的查询可以说非常普遍。但如果从计量单位是天的话,那么在1天之内,被认为是幂等的,否则就不是幂等的。
另外,MySQL也提供了三组防止重复提交的语句,可以用来保证幂等。
INSERT IGNORE INTO:若有导致unique key冲突的记录,则该条记录不会被插入到数据库中。REPLACE INTO:若插入时如发现unique key已存在,则替换原记录,即先删除原记录,后INSERT新记录。ON DUPLICATE KEY UPDATE:若插入时如果发现unique key已存在,则执行UPDATE更新操作。
-- 如果已有id = 1的记录则不执行插入且不会报错
> INSERT IGNORE INTO user(id, name, age) VALUES(1, 'lixingyun', 19);
-- 删除id = 1的用户后再插入相同的记录值且更新时间
> REPLACE INTO user(id, updatetime) VALUES(1, now());
> INSERT INTO user(id, name, age) VALUES(1, 'lixingyun', 19) ON DUPLICATE KEY UPDATE age = age + 1;
-- 等同于
> UPDATE user SET age = age + 1 WHERE id = 1;感谢支持
更多内容,请移步《超级个体》。