
全局唯一ID
ID为什么不唯一
不管是最初的单机系统,还是将业务服务部署在多个节点上的集群系统,对数据库的访问方式始终没有发生根本性的变化,无非是从独立结构变成了主从结构。
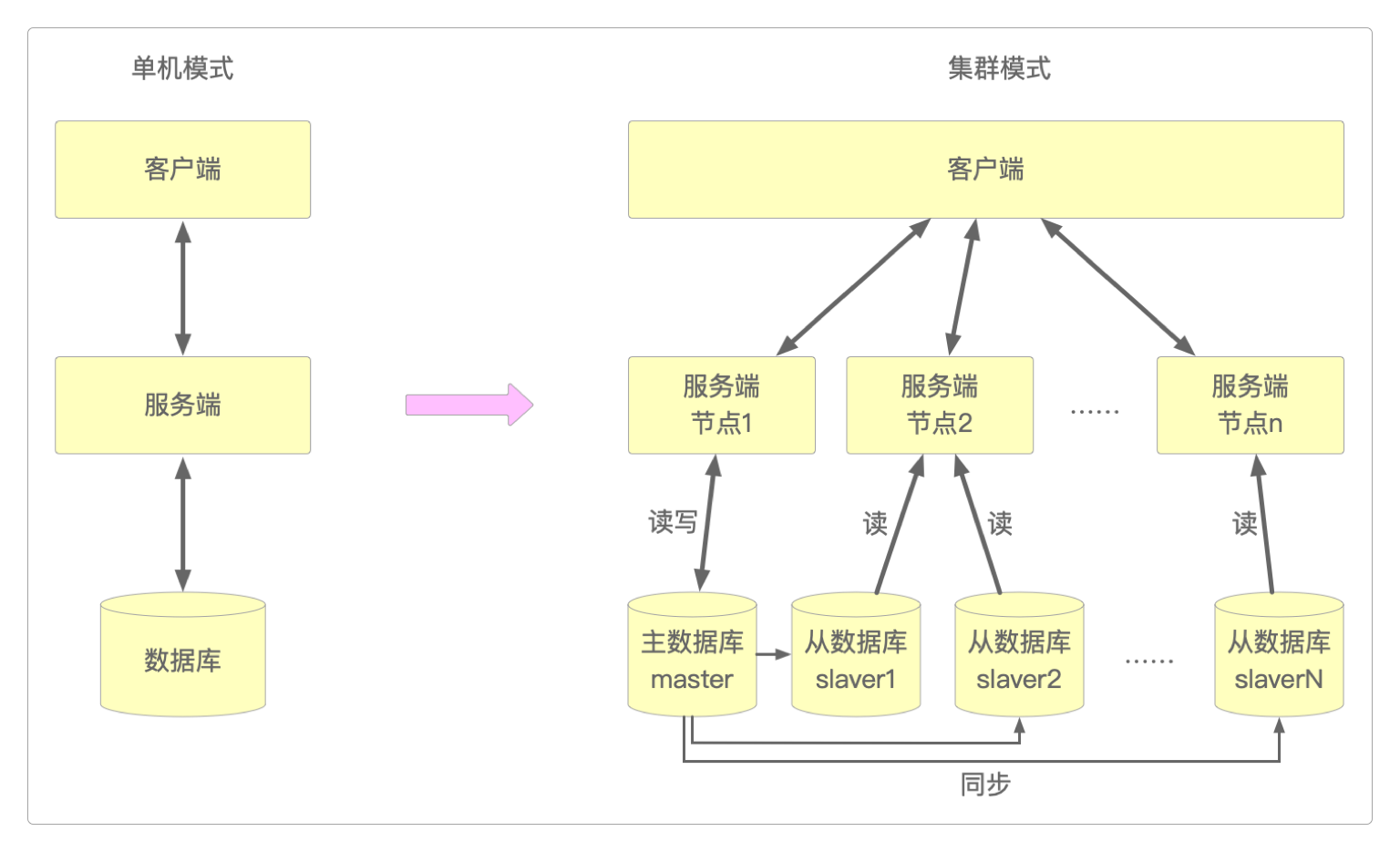
随着分布式概念的不断普及,对数据库进行切分(分库分表)的做法也越来越普遍。
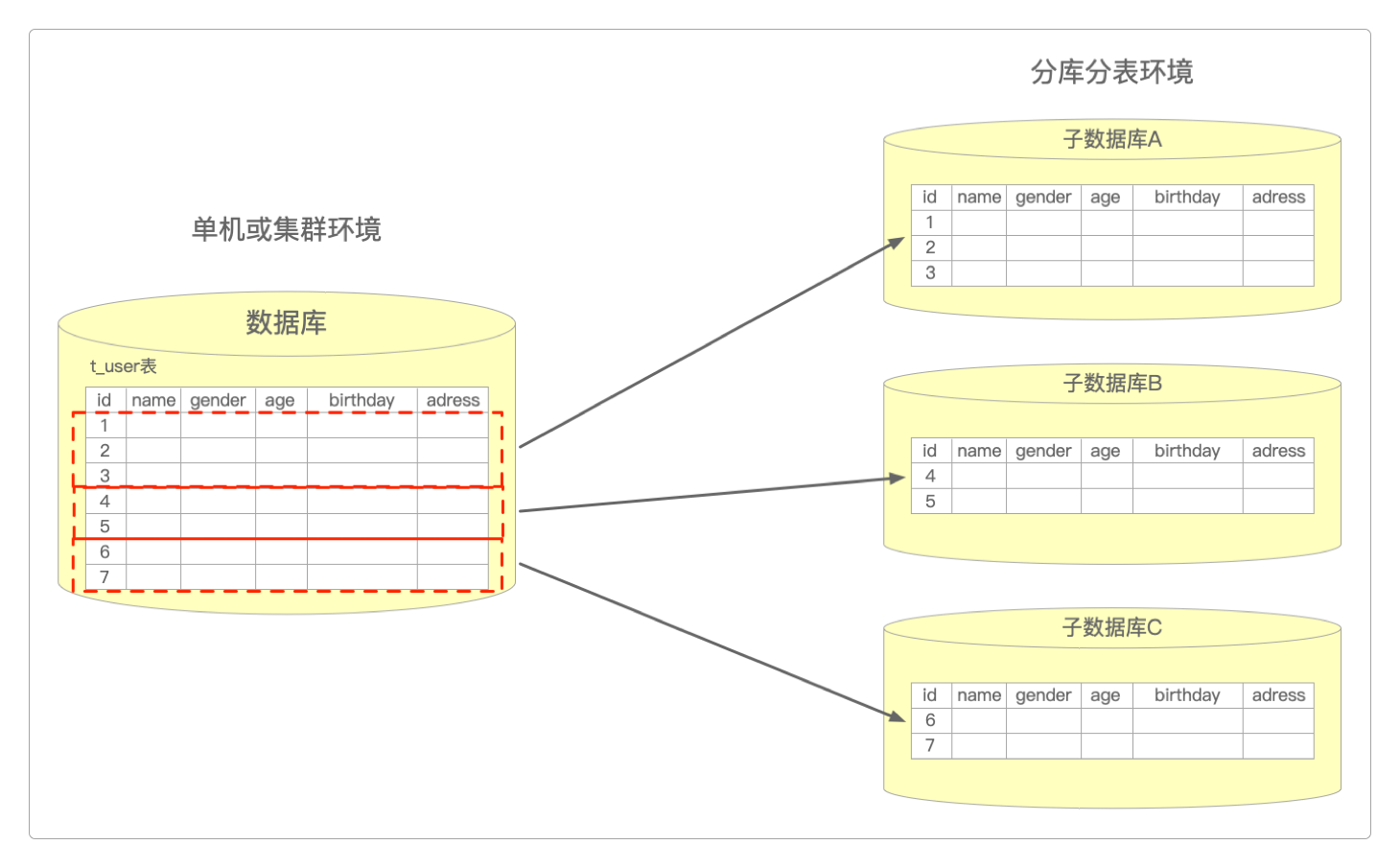
通过对数据表的切分,现在可以将同一张表(t_user)存放在三个不同的数据库中了。
如果此时用数据库自带的自增主键,那么当查询id=10的记录时,可能三张表里都会存在,而且是三个不同的值,这就造成了数据冲突,到底该读取哪张表中的值呢?
因为对于一个统一的数据库来说,每一条不同的数据,其对应的主键(ID)应该是唯一的。
但现在出现了不唯一:因为不同的分库会自增产生自己的ID,它在局部上是唯一的,但是全局不唯一。
解决方案
UUID
可以使用MySQL自带的UUID()函数。
-- 带连字符的
> SELECT UUID();
-- 不带连字符的
> SELECT REPLACE(UUID(), '-', '');也可以通过代码来生成。
// 带连字符的
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
// 不带连字符的
uuid = uuid.replaceAll("-", "");
System.out.println(uuid);单库自增
这里用的数据库自增和前面的数据表中的自增不是一回事,这里的自增是一个单独的表,专门用来为系统中所有的切分的表提供自增的ID。
-- 创建一个独立的用于生成自增ID的数据库
> CREATE DATABASE `AUTO_INCREMENT_ID`;
-- 专门用户t_user表的自增ID,如果还有其他表需要,也可以如法炮制
> CREATE TABLE T_USER_ID (
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
value TINYINT(1) NOT NULL DEFAULT '1',
PRIMARY KEY (id),
) ENGINE = MyISAM;
-- 插入数据时就会生成新的ID
> INSERT INTO T_USER_ID(value) VALUES(1);集群自增
为了防止单点故障,可以通过集群的方式来生成自增ID。但需要给每个数据库设置单独的起始值和步长,而且这两个值都与集群中的节点数量有关。
-- 节点1配置
> set @@auto_increment_offset = 1; -- 起始值
> set @@auto_increment_increment = n; -- 步长
-- 节点2配置
> set @@auto_increment_offset = 2; -- 起始值
> set @@auto_increment_increment = n; -- 步长
-- 节点3配置
> set @@auto_increment_offset = 3; -- 起始值
> set @@auto_increment_increment = n; -- 步长
......
-- 节点n配置
> set @@auto_increment_offset = n; -- 起始值
> set @@auto_increment_increment = n; -- 步长从设置可以清楚看出节点数量和起始值、步长的关系:节点数量 = 起始值 = 步长。
以3节点为例,它们生成的自增ID就是这样的。
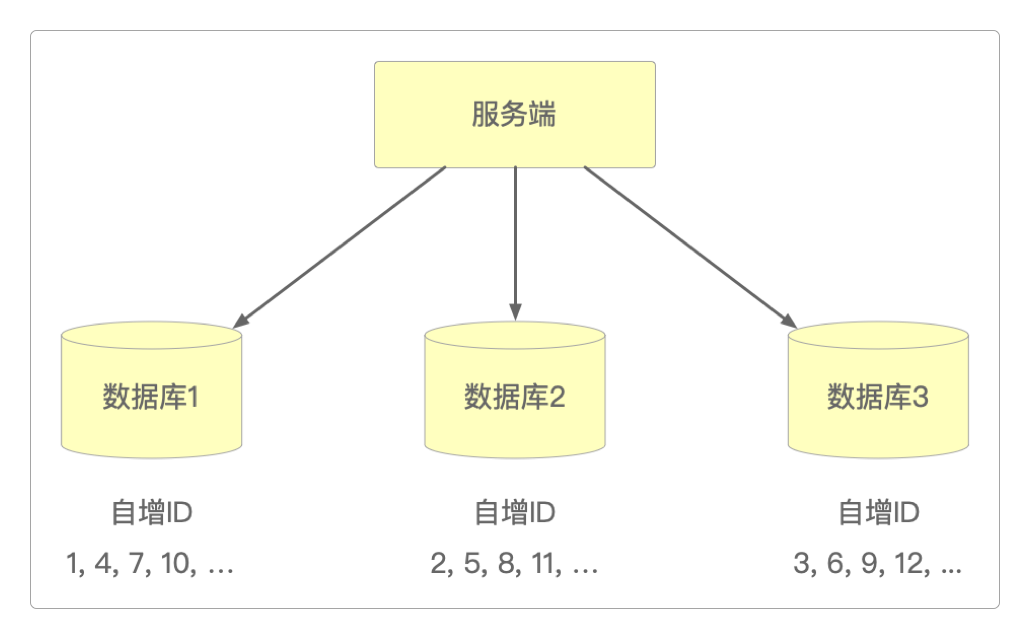
Flickr采用的就是这种实现方式,它启用了两台数据库服务器来生成Globally Unique Identifier(简写GUID),通过区分auto_increment的起始值和步长来生成奇偶数的。
它的数据库建表语句如下。
> DROP TABLE IF EXISTS sys_sequence;
> CREATE TABLE sys_sequence (
id int(11) NOT NULL AUTO_INCREMENT,
stub char(1) CHARACTER SET utf8 NOT NULL DEFAULT '1',
PRIMARY KEY (id),
UNIQUE KEY sys_sequence_stub (stub) USING HASH
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
-- 在每次需要生成GUID时,在一个事务会话中执行下面的SQL语句
> REPLACE INTO sys_sequence(stub) VALUES('1');
> SELECT LAST_INSERT_ID();下面是这种实现方式的核心代码。
package com.longbei.appservice.dao;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import org.springframework.stereotype.Repository;
import com.longbei.appservice.common.persistence.BaseDao;
import com.longbei.appservice.common.persistence.BaseEntity;
/**
* 采用Flicker方式生成全局唯一ID
*
*/
@Transactional
@Repository
public class IdGenerateByDBDao extends BaseDao<BaseEntity> {
private volatile static ThreadLocal<Long> ticket = new ThreadLocal<Long>() {
public Long initialValue() {
return 0L;
}
};
public Long counter() {
ticket.set(ticket.get() + 1);
return ticket.get();
}
public long nextGenerateId() throws Exception {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Long odd = counter();
if (0 != odd % 2) {// 奇数id
conn = getOddIdJdbcTemplate().getDataSource().getConnection();
stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_UPDATABLE);
stmt.executeUpdate("REPLACE INTO sys_sequence (stub) values ('1')", Statement.RETURN_GENERATED_KEYS);
} else {// 偶数id
conn = getEvenIdJdbcTemplate().getDataSource().getConnection();
stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_UPDATABLE);
stmt.executeUpdate("REPLACE INTO sys_sequence (stub) values ('0')", Statement.RETURN_GENERATED_KEYS);
}
Long generateId = -1L;
rs = stmt.getGeneratedKeys();
if (rs.next()) {
generateId = rs.getLong(1);
} else {
throw new Exception("generate id failed");
}
rs.close();
rs = null;
stmt.close();
stmt = null;
return generateId;
} catch (SQLException se) {
se.printStackTrace();
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException se) {
se.printStackTrace();
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException se) {
se.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException se) {
se.printStackTrace();
}
}
}
return -1L;
}
}号段自增
这种模式既将ID按业务属性来区分,又可以批量生成ID,而不用像之前那样一次只生成一个。
-- 号段表
> CREATE TABLE NUMBER_SEGMENT_ID (
id BIGINT(20) UNSIGNED NOT NULL, -- ID不再自增,而是由代码生成
max_id BIGINT(20) NOT NULL, -- 当前最大的ID值
step INT(11) NOT NULL, -- 号段的步长
biz_type INT(11) NOT NULL, -- 业务类型
version INT(11) NOT NULL, -- 版本号
PRIMARY KEY (id),
) ENGINE = MyISAM;
-- 对于用户表可以这样生成首批ID
> INSERT INTO NUMBER_SEGMENT_ID VALUES(1, 1000, 1000, 1, 0);然后会有专门的业务代码来读取NUMBER_SEGMENT_ID表,按照其要求生成一批新ID,也就是从2~1000(因为1已经存在了),生成后表中的数据会是这样的。
| id | max_id | step | biz_type | version |
|---|---|---|---|---|
| 1 | 1000 | 1000 | 1 | 0 |
| 2 | 1000 | 1000 | 1 | 0 |
| 3 | 1000 | 1000 | 1 | 0 |
| ...... | 1000 | 1000 | 1 | 0 |
| 1000 | 1000 | 1000 | 1 | 0 |
当这一批号段用完,可以继续申请下一批。
> UPDATE NUMBER_SEGMENT_ID SET max_id = #{max_id + step}, version = version + 1 WHERE version = # {version} AND biz_type = 1;例如,如果每次批量生成1000个ID的话,那么表中的数据就全都变成了这样。
| id | max_id | step | biz_type | version |
|---|---|---|---|---|
| 1 | 2000 | 1000 | 1 | 1 |
| 2 | 2000 | 1000 | 1 | 1 |
| 3 | 2000 | 1000 | 1 | 1 |
| ...... | 1000 | 1000 | 1 | 1 |
| 1000 | 2000 | 1000 | 1 | 1 |
可以看到,如果只有一张NUMBER_SEGMENT_ID表,有两个很大的弊端。
数据表的空间利用上存在巨大浪费,除了
id,其他几列中每一行存储的都是完全相同的内容。随着
ID的不断自增,每次需要UPDATE的行数越来越多。如果一次需要更新几千万行,那数据库的效率会大打折扣。
所以,可以将单库自增或集群自增的模式和号段自增的模式结合起来。
-- 增加一个专门生成ID的表
> CREATE TABLE NUMBER_SEGMENT_AUTO_INCREMENT_ID (
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
value TINYINT(1) NOT NULL DEFAULT '1',
PRIMARY KEY (id),
) ENGINE = MyISAM;这样的话,每次只需要更新NUMBER_SEGMENT_ID表表中的一行数据,剩下的操作由数据库自己来完成,在效率和在空间利用率上也高得多。
Redis自增
除了数据库自增ID,还可以使用第三方中间件实现ID的数值自增,例如Redis。

下面是实现这一过程的伪代码。
jedis.set("userId", "1");
long userId = jedis.incr("userId");
User user = new User(userId);
mysqlDao.save(user);雪花算法
SnowFlake算法应该是世界上最早用代码来实现分布式全局唯一ID的算法了,它最初是用Scala实现的。
迄今为止,各种语言都有它的实现版本了。
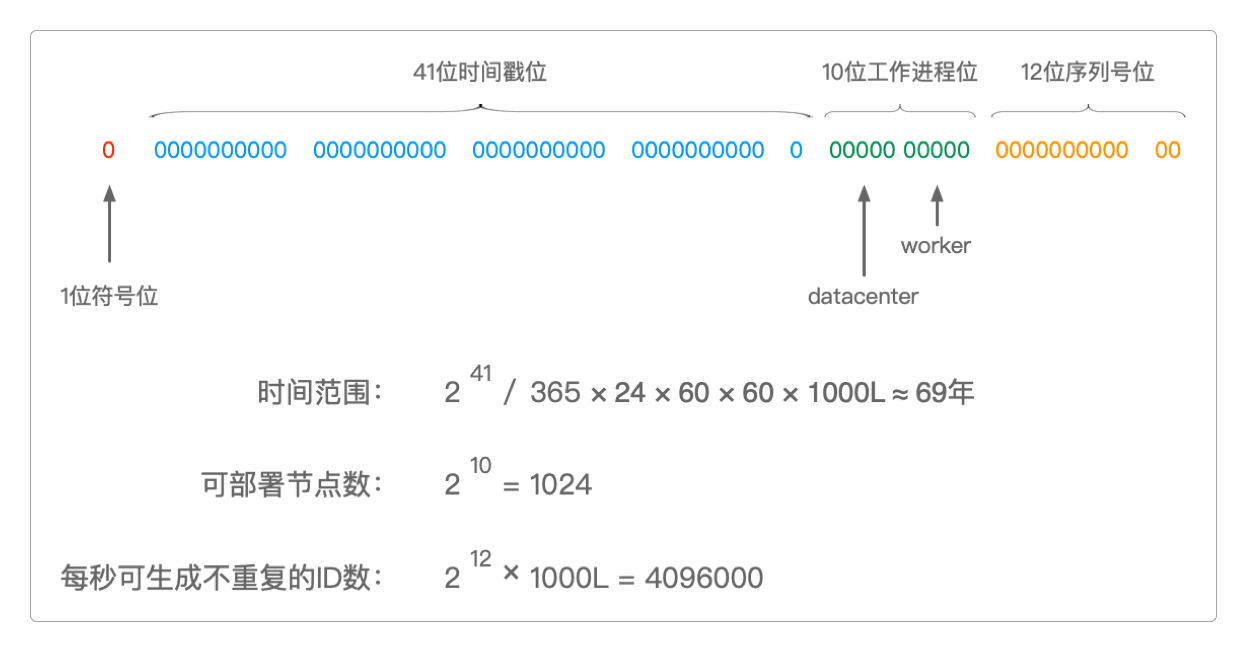
有图、有文档、有代码,就不用废话了。
国内开源算法
百度UidGenerator:对SnowFlake算法的一种改造,集成也比较简单。
美团Leaf:基于
号段模式实现。滴滴Tinyid:基于
号段模式实现。
这三种国内开源的全局唯一ID生成算法中,除了百度UidGenerator的集成较为简单外,其他的都需要独立部署服务,相对要麻烦一些。
算法的比较
| 算法名称 | 生成方 | 优点 | 缺点 | 说明 |
|---|---|---|---|---|
| UUID | 业务代码或数据库 | 简单灵活 | 无序字符串无业务含义,存储及查询对索引性能消耗较大 | 不建议采用 |
| 单库自增 | 数据库 | 实现简单,查询快 | 存在单点故障问题,无法满足高并发和高吞吐量的要求 | 不建议采用 |
| 集群自增 | 数据库 | 解决单点故障问题,能适应一定的高并发场景 | 不利于后续扩容,部署过多又容易浪费 | |
| 号段自增 | 数据库 | 可以在一定程度上满足高吞吐量和高并发访问需求 | 单纯的号段自增在空间利用上存在巨大浪费且数据量越大,更新效率越低 | 需要改良的号段自增模式 |
| Redis自增 | 数据库 | 简单灵活 | 对网络环境依赖较大 | 也分为单机模式和集群模式 |
| 雪花算法 | 业务代码 | 简单灵活 | 高并发场景下会有ID重复导致冲突的可能 | |
| 国内开源 | 业务代码或数据库 | 是对已有方案的整合与改进 | 已有方案的缺点它都有 |
感谢支持
更多内容,请移步《超级个体》。