
战术设计
战略分析完成之后,就到了战术分析阶段。
相对于战略设计的抽象,战术设计就比较具体了,它更多的是将业务需求映射到技术代码的层次结构上,设计上下文里都包含哪些类,这些类之间又该如何配合等。
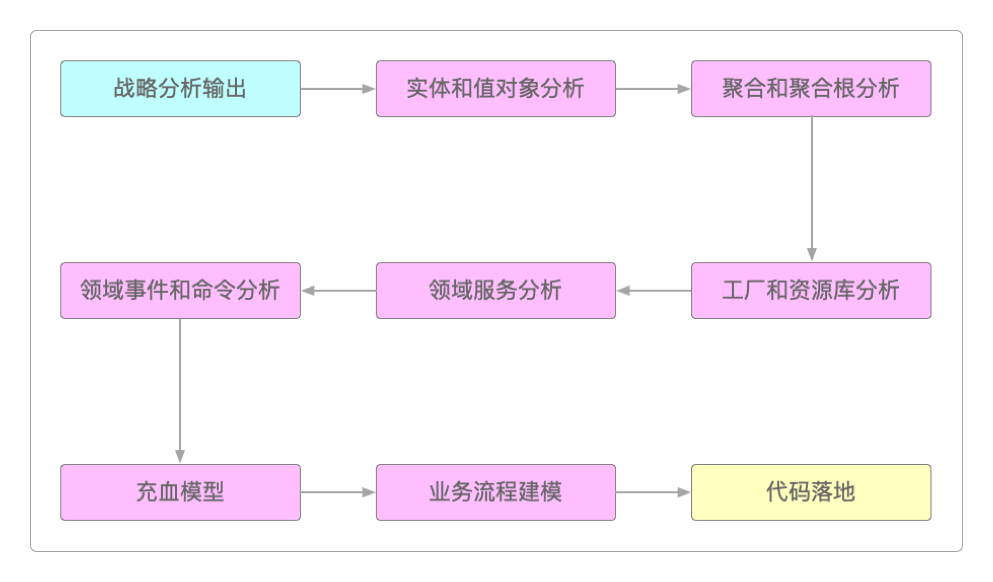
战术设计基本上由实体、值对象、聚合、领域事件和命令、领域服务、工厂和资源库、充血模型这几个主要部分组成。
在战术设计阶段,最好对照着PM给出的纯粹的不含任何技术的业务流程来进行,这个时候千万不要去考虑什么表设计、ORM、微服务框架、缓存、MQ之类的技术内容。
实体和值对象
在DDD中,实体(Entity)和值对象(Value Object)是两个比较核心的概念。
实体(Entity)其实就是MVC中的实体类,它有唯一标识,而且这个唯一标识在整个系统的上下文中都是唯一的。
例如,Order(订单)就是一个实体,它有唯一标识——Id,所有与之相关的业务,都是围绕这这个Id进行的。
除了这个Id,其他的属性都是可以变化的,例如,状态、收件地址或者快照。
在系统的上下文环境里,每一个子域或者限界上下文中都有若干个这种实体,它们撑起了整个项目的业务骨架。
所谓值对象(Value Object),它既可以是实体,也可以是某个单纯的数值,但它和实体有两点不同。
值对象没有唯一标识,这意味着要判断两个值对象是否等同,就要判断它们所有的属性值是否都相同,这里的唯一标识指的并不是数据库中的Id,而是一种业务语义上的Id。值对象基本上是依附于某个实体而存在的,它不会单独出现在某个业务上下文中。例如,不同的Order可以使用相同或者不同的DeliveryAddress(收货地址),或者SKU(库存单元,也叫型号规格),而DeliveryAddress或SKU脱离了Order,在业务上是没有单独存在的意义的。
/**
* Order实体类
*
*/
public class Order {
// 唯一标识
private Long id;
// 下面都是值对象(也可以都是实体)
private DeliveryAddress deliveryAddress;;
private PayType payType;
private PaymentDetail paymentDetail;
private Snapshot orderSnapshot;
private Status orderStatus;
}很多网络上的资料都说值对象跟着实体一起被创建,又一起被销毁。这种说法也是基于业务语义层面,而不是数据库层面的。
聚合与聚合根
所谓的聚合(Aggregate),指的就是数据库中主表与子表的关系,例如,Order(订单)与OrderItem(子订单)。
这种关系和实体-值对象之间的关系稍稍有些不同:OrderItem(子订单)也是一个实体(Entity),也有自己的唯一标识,它是有业务语义的,甚至是可以独立存在的。另一个例子就是风控中的风控规则和与之对应的若干条风控规则详情。
/**
* 风控规则实体
*
*/
public class RiskRule {
// 唯一标识
private String id;
// 每个规则详情也是一个实体,也有自己的唯一标识,通过组合不同的规则详情,可以组合出不同的规则
private List<RuleDetails> ruleDetails;
}如果说聚合指的是一个整体,那么这个整体中起主导作用就被称为聚合根(Aggregate Root)。
在上面的例子中,Order和RiskRule都是聚合根。
如果主-子之间的从属关系是聚合,那么当值对象是一个实体的时候,实体-值对象之间也算是聚合关系。
说通俗点就是,一个聚合代表了多个类绑定在一起,而在这些聚合在一起的类中,放在最外面的,就是聚合根。
另外,很多资料都说聚合有生命周期:必须在创建的时候一起创建,更新的时候一起更新,删除的时候一起删除。
但我不这么认为,因为有几个明显的反例(这里的操作都是基于业务语义层面而非数据库层面)。
订单创建了,订单项和订单快照也会被一同创建,但订单更新和删除的时候却未必是这样。风控策略创建了,不一定要马上就创建风控规则,对于更新和删除也是这样(实际上,应该是先有风控规则,然后再来组装风控策略)。
只是说,如果它们在生命周期上保持一致,对于业务的实现来说就会显得更完整而已,但实际上,处理方式是根据业务需要而定的,并不是完全照搬理论。
显然,一个聚合里可以包含实体,也可以再包含其他聚合——它可以是多个层次的。
另外,实体-值对象和实体-实体这种关系其实并没有本质上的区别,在实际开发中如何划分,基本上是取决于DDD和业务语义对设计者的双重影响的结果。
例如,既可以将DeliveryAddress、PayType、Snapshot等指定为值对象,也可以将它们指定为实体,是哪一种都无所谓,只要这种划分能准确地匹配业务语义并且团队一致认可就好了。
领域事件和命令
DDD认为,业务系统中的动作和行为,应该是由用户主动触发的,例如,用户括点击网页、小程序或APP中的按钮和链接。
这些由用户触发的系统行为,DDD称之为命令(Command)。
一般来说,这些命令对应的都是创建、更新或者删除数据的动作,而查询的动作,则称为Query——这也是CQRS为什么会叫CQ的原因(C代表Command,而Q则代表Query)。
相对于命令(Command),领域事件(Domain Event)则是由系统触发的,包括某些定时的任务调度,例如,30分钟后删除未支付的失效订单、处理秒杀时队列中的请求、每日自动执行的异构数据同步等动作。
/**
* 订单相关的命令和领域事件
*
*/
public class OrderServiceEvent {
/**
* 创建订单
* 在这里执行需要完成的订单创建流程
* 这套流程的逻辑必须符合业务语义和流程的定义
*
*/
public void createOrder(CreateOrderCommand command) {
}
/**
* 其中某个业务动作,就是要删除那些超时未支付的订单
*
*/
@Scheduled(initialDelay=1000, fixedDelay=5000)
public Order removeUnpaidOrder(RemoveOrderEvent removeOrderEvent) {
// 删除30分钟超时未支付的订单
if removeOrderEvent.createtime > System.currentTimeMillis() - 1800000) {
// TODO 执行删除逻辑
}
}
}这种领域事件更多的是属于业务流程的一部分,它让流程执行更完整,更符合业务的需要。
业务组件
在开发中有时候需要用到一些类或对象,但这些类或对象可能并不属于当前的限界上下文,或者也不需要保存它们,只是需要用到它们中的业务行为。
例如,在订单限界上下文中可能需要用到User类,但这个User并不属于订单限界上下文,那么此时这个User就是一个业务组件而非实体。
当然,也可把User类作为实体来对待,但一是没必要,二是还可能会造成数据的不一致。
或者,需要调用一些外部接口,如果单独把它们划分到某个限界上下文的话太麻烦,那么可以将它们封装为当前限界上下文的业务组件,方便统一调用。
领域服务
有时候,某些业务行为,既没有办法让用户来触发,也没办法把它放到业务流程中去的。也就是说,它既不是命令(Command),也不是领域事件(Domain Event)。
例如,当用户一次性支付多笔订单时,很可能会需要临时(例如,大促期间)对这笔交易进行一个统一的计算,看看优惠后用户的实付金额应该是多少。又或者,某个商家发起了某个运营活动,参与活动的用户都可以获得一定的支付金额减免,活动完结后订单的支付金额恢复正常——这其实就是电商网站经常搞的满减、满赠和凑单等活动。
此时,上面的这些业务逻辑就不能放在Order里面去执行了。
所以,DDD为此又搞出了一个新的东西,叫领域服务(Domain Service)。
所谓领域服务(Domain Service)就是一些公共服务,用来集中处理多个聚合或实体的共同的业务需求。
领域服务有的地方也被称为业务组件。
/**
* 订单领域服务
*
*/
public class OrderDomainService {
/**
* 计算多个订单时应该享受的折扣
*
*/
public int calculateDiscount(List<Order> orders) {
// 订单优惠计算
if (orders.size() > 1 && orders.size() <= 3) {
// TODO 优惠计算
return 10;
} else if (orders.size() > 3 && orders.size() <= 5) {
// TODO 优惠计算
return 20;
} else if (orders.size() > 5) {
// TODO 优惠计算
return 30;
}
return 10;
}
}包含一些贴合业务语义的业务组件,在业务场景里,此时可能有一个概念,订单状态机,他不属于聚合、领域服务,他其实是一个业务组件
public class OrderStateMachine { // 贴合业务语义的业务组件
}基本上,把实体(Entity)、值对象(Value Object)、聚合(Aggregate)、聚合根(Aggregate Root)、命令(Command)、领域事件(Domain Event)和领域服务(Domain Service)这些东西都搞出来以后,整个基于DDD的战术设计就算是完成了。
但要验证它们做的对不对,是否贴合业务,还得通过实际运行的结果来检验。例如,可以找不懂代码的客户或者PM(产品经理)来通过程序里的英文单词来走读代码。
如果他们通过走读就能理解代码确实符合业务语义,并且运行过程中也确实是符合业务流程和业务需求的话,才能说DDD的设计是成功的(这与是不是符合DDD的理论没有半毛钱的关系)。
工厂和资源库
上面东西都具有明显的业务属性,但为了符合软件设计原则,DDD又从MVC里面搬了两样东西过来。
工厂(Factory):参照Spring中的BeanFactory方式,将复杂对象的创建过程单独封装到一个工厂类中,这样既符合单一职责原则,也不会造成某些类的职责过多,代码冗长。资源库(Repository):很多地方都叫它仓储,不管叫什么,它只做一件事,就是承担MVC中DAO那一层的职责,将实体和值对象等内容持久化到指定的存储介质中,或者从指定的存储介质中读取。这里的存储介质包括但不限于MySQL、Redis、Elasticsearch、Neo4J、Flume,甚至是Hadoop、Spark、Flink和Clickhouse等。
所以,如果看到某个类的命名是这样的OrderFactory或者OrderRepository,就应该知道它们是干嘛的了。
充血模型
在MVC中,所有的Bean(DTO)基本上都是和数据库中的表一一对应的,而且也都只有getter和setter方法,这其实正是MVC被诟病为面向数据库编程的根本问题所在。
DDD把这种方式称为贫血模型。
所以针对这种贫血问题,DDD提出的解决方案是充血模型。
所谓充血模型说的是如果一个实体,既有自己的业务属性(值对象、聚合、聚合根),还有业务行为(命令、领域事件、领域服务),那它就具备了完整的业务语义。
其实就是把以前在MVC中的各种Service层服务都整合进了实体之中,并且以更加自然(业务化)的方式来命名,例如,命令、领域事件和领域服务。
然后再将DAO层的东西封装成资源库(Repository),加上分离出来的工厂(Factory),让模型不但充血,还有骨肉。
只不过这种充血并不是胡乱充的,它需要充分了解业务,而且一定要符合流程和语义。
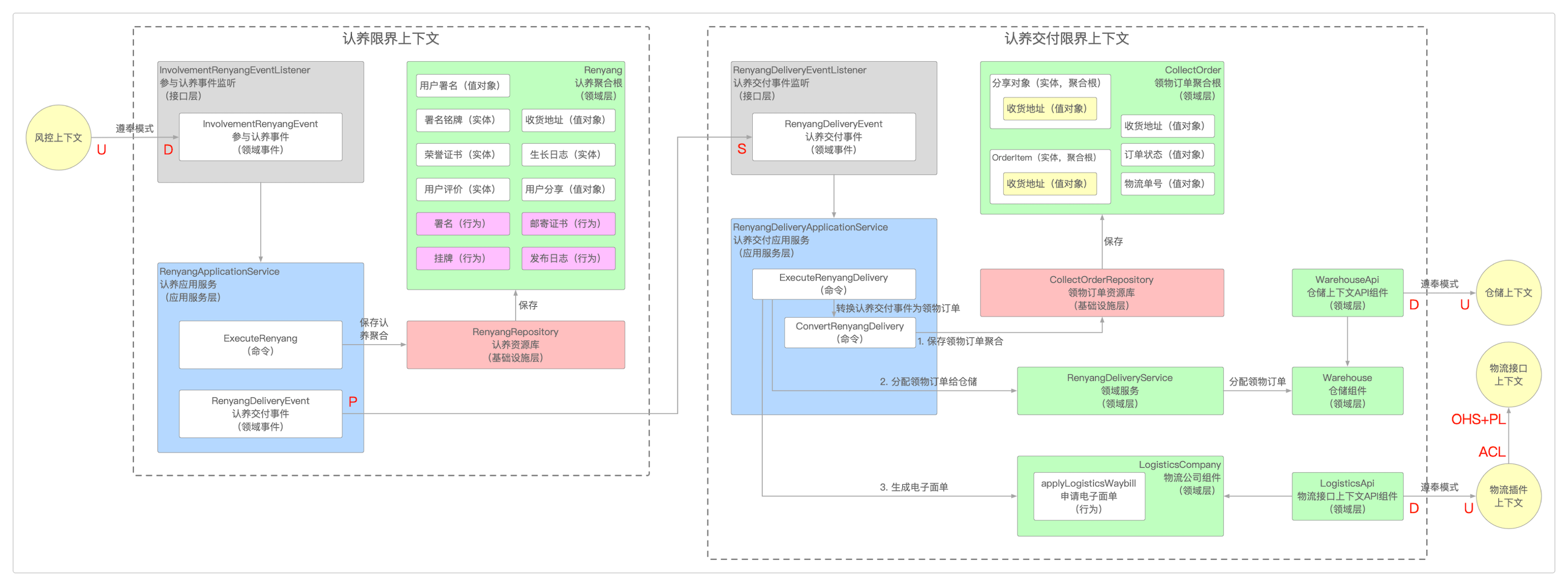
业务流程建模
在搞清楚了战术设计中涉及到的那些诸多概念之后,就可以从业务的角度出发,来将它们整合到一起,形成一个完整的业务闭环了。
下图只展示了部分的认养限界上下文和认养交付限界上下文。
感谢支持
更多内容,请移步《超级个体》。