
Zepplin
原创大约 2 分钟
Zeppelin是一款基于Web的数据可视化中间件,它可以支持多种语言和大数据平台的接入(例如,它默认就支持Spark、Flink和Python 3.9)。
Zeppelin的配置非常简单,几乎就是拆箱即用。
Docker部署
简易版的Docker部署方式。
> docker run -p 8080:8080 --rm --name zeppelin apache/zeppelin:0.10.1复杂版的Docker部署方式:将Spark和Flink集成进来。
> docker run -u $(id -u) -p 8080:8080 \
--rm -v $PWD/logs:/logs -v $PWD/notebook:/notebook \
-v /usr/lib/spark-3.5.1:/opt/spark -v /usr/lib/flink-1.18.1:/opt/flink \
-e FLINK_HOME=/opt/flink -e SPARK_HOME=/opt/spark \
-e ZEPPELIN_LOG_DIR='/logs' -e ZEPPELIN_NOTEBOOK_DIR='/notebook' \
--name zeppelin apache/zeppelin:0.11.1本机部署
可以在这里https://dlcdn.apache.org/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz下载zeppelin-0.10.1-bin-all.tgz的安装包。
# 下载解压
> cd /home/work
> wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz
> tar zxvf zeppelin-0.10.1-bin-all.tgz
> mv zeppelin-0.10.1-bin-all zeppelin-0.10.1
> cd zeppelin-0.10.1
# 修改配置文件
> cp conf/zeppelin-env.sh.template conf/zeppelin-env.sh
> cp conf/zeppelin-site.xml.template conf/zeppelin-site.xml
> vi conf/zeppelin-site.xml
<property>
<name>zeppelin.server.addr</name>
<!-- 将这里的 127.0.0.1 改为任意机器都能访问 -->
<value>0.0.0.0</value>
<description>Server binding address</description>
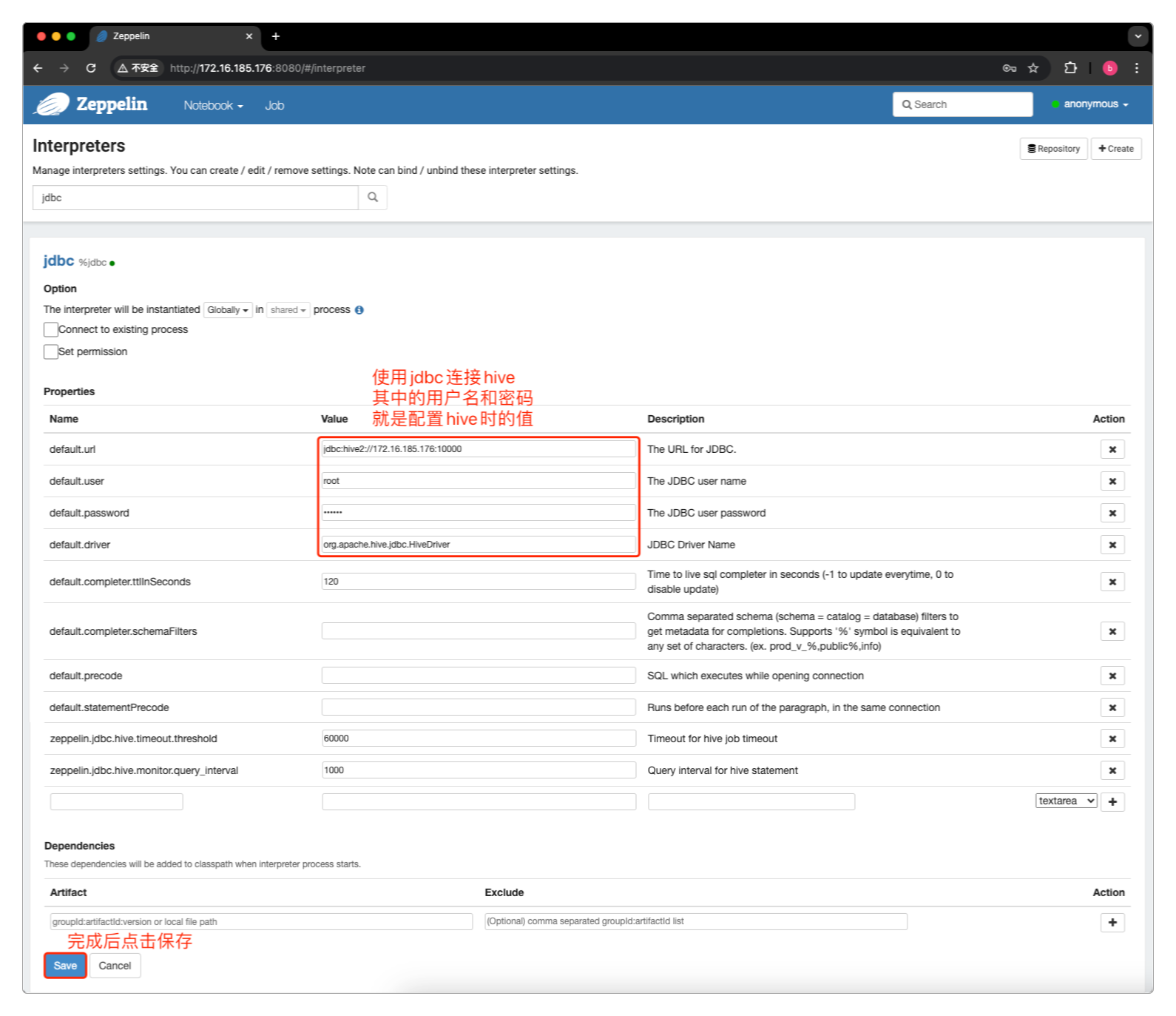
</property>因为需要通过Zeppelin来操作Hive,所以要把Hive相关的依赖包拷贝进来。
最简单直接的方法,就是把${HIVE_HOME}/lib中的jar包全部拷贝到${ZEPPELIN_HOME}/interpreter/jdbc中。
> cp /home/work/hive-3.1.3/lib/*.jar /home/work/zeppelin-0.10.1/interpreter/jdbc/启动服务
> cd /home/work/zeppelin-0.10.1
> bin/zeppelin-daemon.sh start
Log dir doesn't exist, create /home/work/zeppelin-0.10.1/logs
Pid dir doesn't exist, create /home/work/zeppelin-0.10.1/run
Zeppelin start [ OK ]
# 查看启动进程
> jps
420977 ZeppelinServer
421021 Jps然后通过浏览器访问http://IP:8080/,就能看到如下界面。
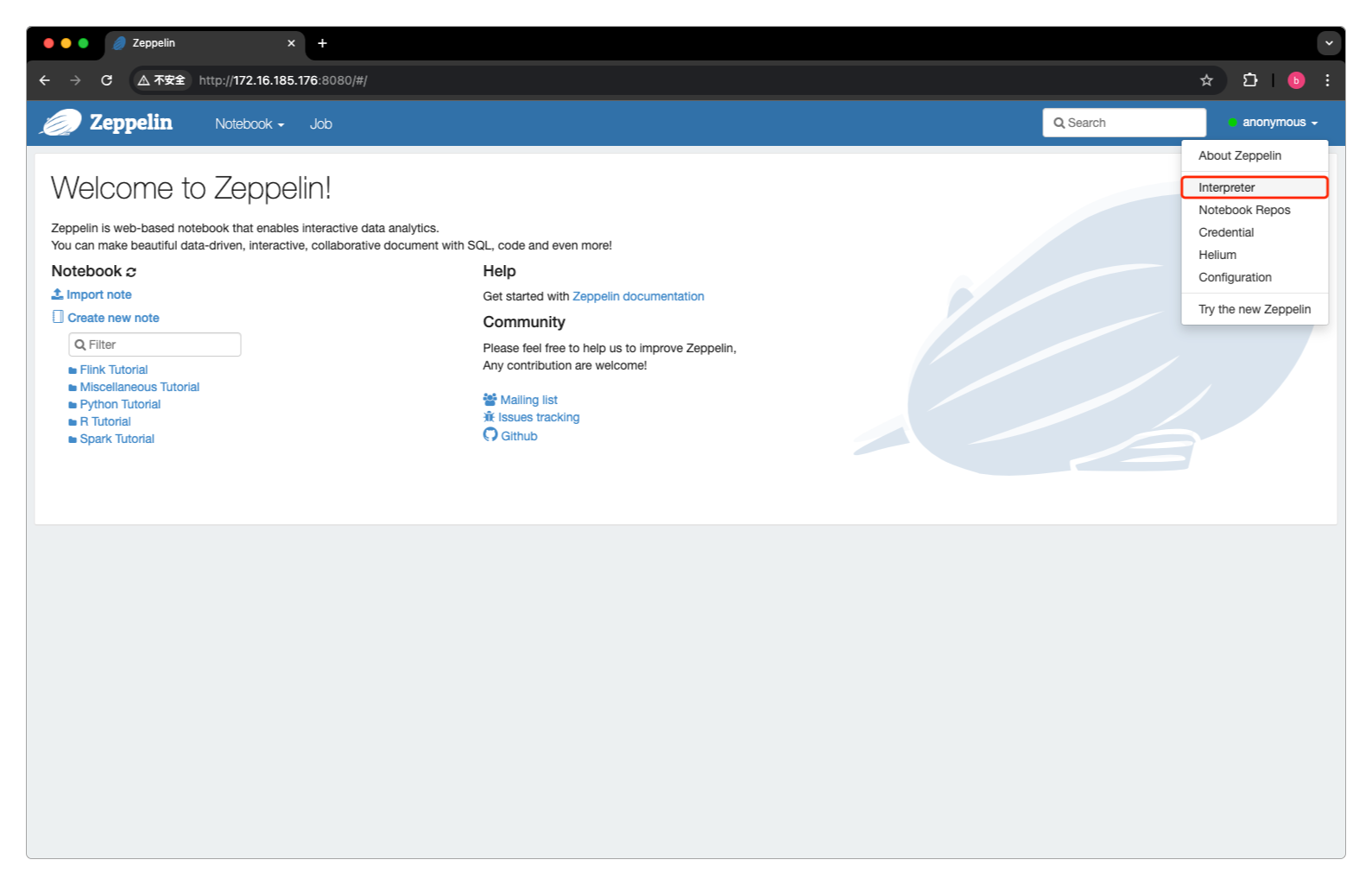
然后点击anonymous -> interpreter,进入到http://172.16.185.176:8080/#/interpreter。
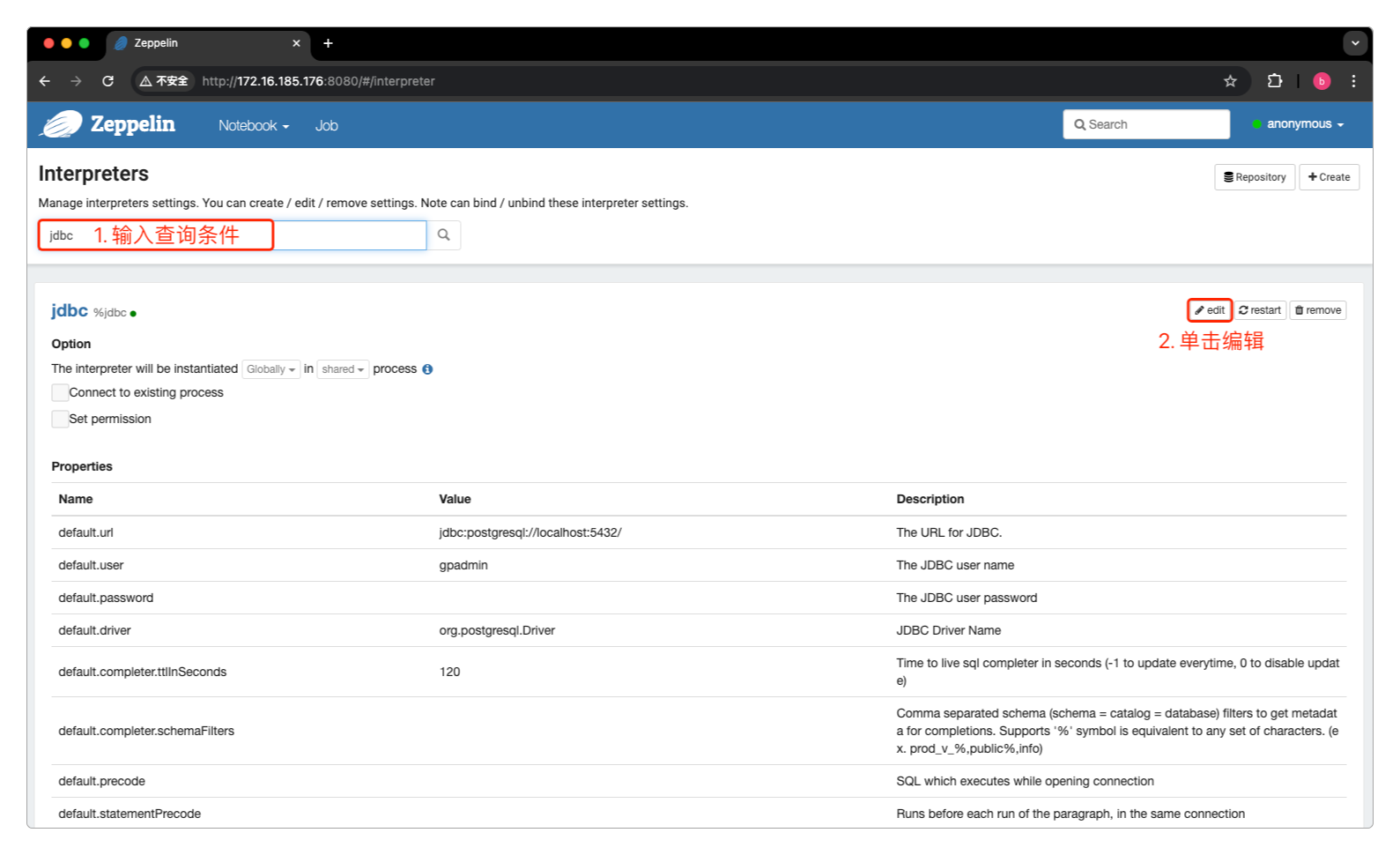
单机edit按钮后开始编辑JDBC的值。
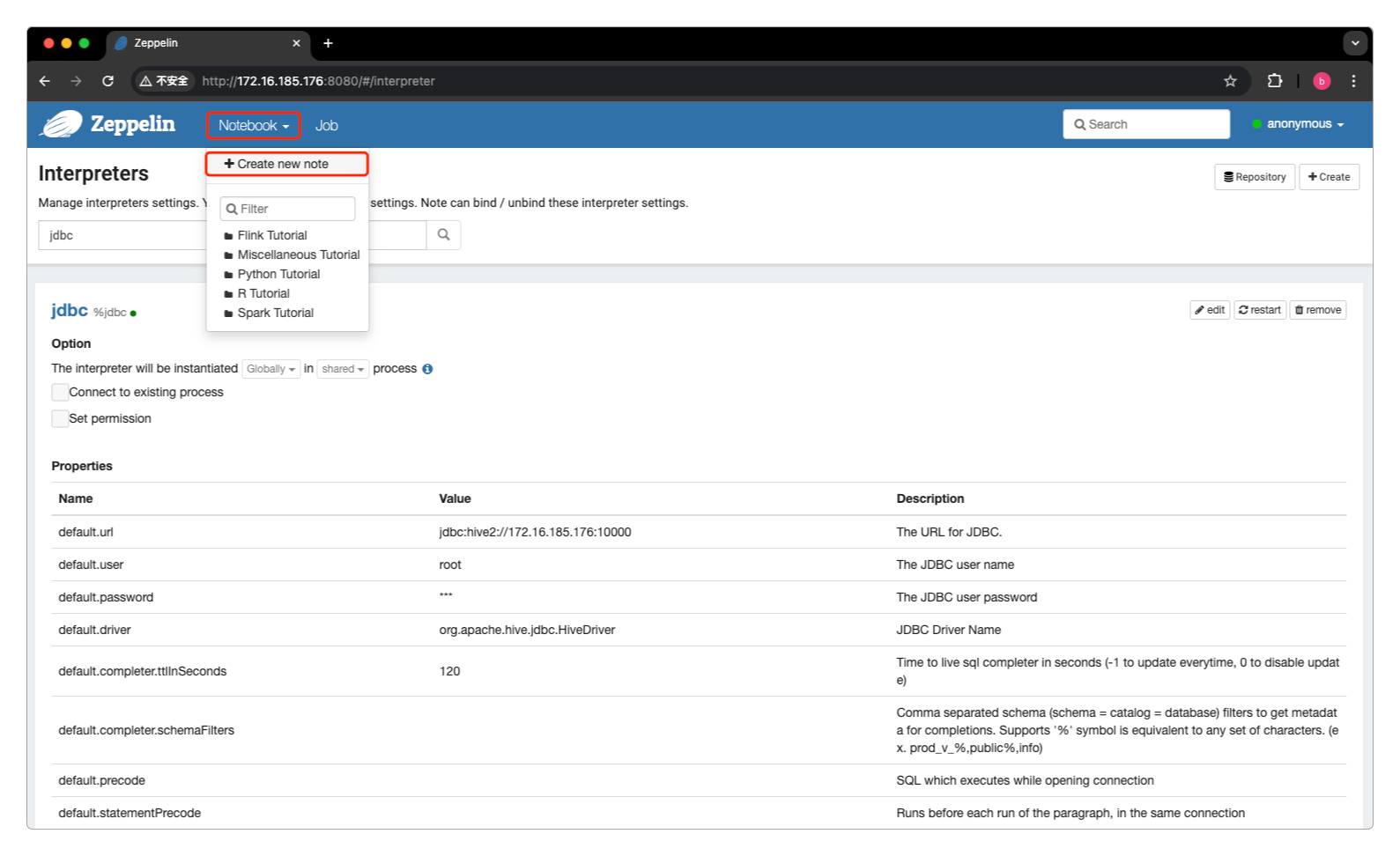
之后就可以通过单机Notebook -> Create New Note生成新的应用控制台了。
创建一个新的节点,也就是用于显示数据的控制台。

数据大屏控制台输入查询语句后再执行就能看到各种统计图表了。
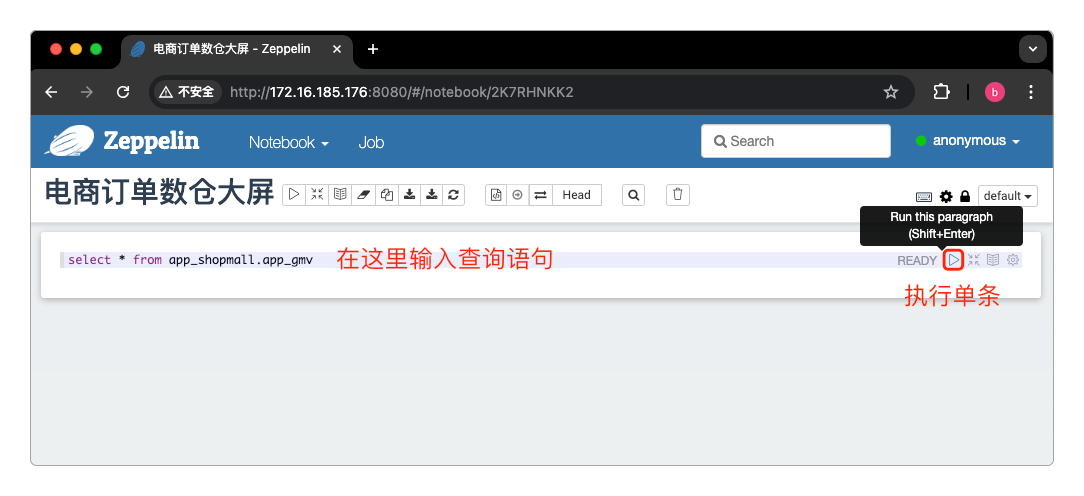
数据大屏控制台因为这里没有创建任何图表,所以看不到输出效果。
感谢支持
更多内容,请移步《超级个体》。