
W-TinyLFU淘汰算法
淘汰算法
相对于动辄按TB计的硬盘来说,内存要小得多,而且贵得多,所以不能把所有的数据全都放到内存,而只能够在内存中临时保存更加有价值的数据。
查询一个数据,如果这个数据刚好在内存的缓存里,就称之为缓存命中。因此,缓存命中率就是衡量一个缓存好坏的重要指标。
因为内存装不下那么多的数据,而且有些数据过段时间可能就没用了,所以需要定期清理,淘汰掉一些没用的或过期的数据,这就是缓存淘汰算法。
常见的淘汰算法包括如下几种。
FIFO:全称First In First Out,先进先出算法,就是谁先来就淘汰谁,众生平等,只能顺序读写。这是最早使用的淘汰算法,问题在于如果某些数据经常使用,也会被淘汰掉。FIFO的执行过程用下面的表就能说明。4 3 2 1 依次插入123 3 2 1 插入4 4 3 2 1 插入5 5 4 3 2 LRU:全称Least Recently Used,最近最少使用算法,就是谁用得最少就淘汰谁,这是目前主流的缓存淘汰算法。问题在于,如果某些数据隔一段时间就会被频繁使用,也会被淘汰掉。LRU的执行过程用下面的表就能说明。4 3 2 1 依次插入123 3 2 1 插入4 4 3 2 1 插入5,1被淘汰 5 4 3 2 插入2,更新3的位置 5 4 2 3 插入6,2被淘汰 6 5 4 3 LFU:全称Least Frequently Used,最近不经常使用算法,就是淘汰最近用得最少的那些数据,这是对LRU的一种改进。但同样也有问题,就是某个数据如果只是一开始出现的很频繁,但后面再也没出现过,那么仍然可能被缓存着。LFU的执行过程用下面的表就能说明。4 3 2 1 依次插入123 3(1) 2(1) 1(1) 插入4 4(1) 3(1) 2(1) 1(1) 再次插入124 4(2) 3(1) 2(2) 1(2) 插入5,3被淘汰 5(1) 4(2) 2(2) 1(2) 插入1 5(1) 4(2) 2(2) 1(3) 插入2 5(1) 4(2) 2(3) 1(3) 插入2 5(1) 4(2) 2(4) 1(3)
因此,LFU两个很明显的缺点。
需要维护大而复杂的元数据来实现算法,而且每次访问以后都需要更新,开销巨大。
如果访问频率变化,
LFU的频率信息却没有随之变化,就会造成命中率急剧下降。
TinyLFU
TinyLFU利用Count-Min Sketch算法维护近期访问数据的频率信息,可以在具有较大访问量的场景下近似的替代LFU的数据统计部分,其原理有些类似Bloom Filter(布隆过滤器)。
Bloom Filter是一种空间利用效率很高的随机数据结构,它能用bit数组很简洁地表示一个集合。
使用一个大的
bit数组存储所有key,每一个key通过多次不同的Hash计算映射到数组的不同bit位。如果
key存在就将对应的bit位加1,这样就可以通过少量的存储空间进行大量的数据过滤。TinyLFU把多个
bit位看做一个整体,用来统计key的使用频率。在读取时,取映射的所有值中的最小的值作为key的使用频率。
比如针对key的Hash计算结果会映射到下面的bit数组中。
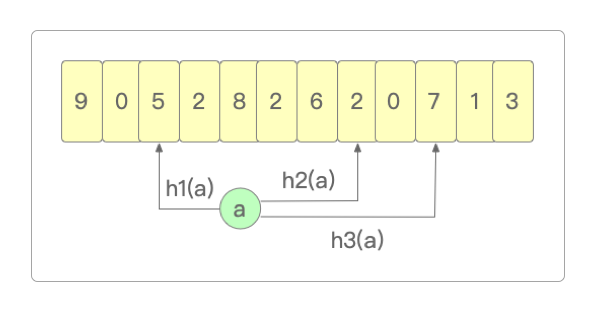
TinyLFU会读取数值最小的h2(a)作为
key的使用频率数据。Caffeine中维护了一个4位的Count-Min Sketch用来记录
key的使用频率,这也意味着统计的key最大使用频率为15。
W-TinyLFU
TinyLFU仍然有LFU的第二个问题:如果访问频率突变,会造成缓存命中率的急剧下降。
例如,微博热点事件,某些词当天被搜索10W次,但是热度过去了,可能就再也不会出现了,然而相关数据却依然还在缓存中没被清理。
W-TinyLFU正是为了解决这类数据过期问题而诞生,它由两部分组成。
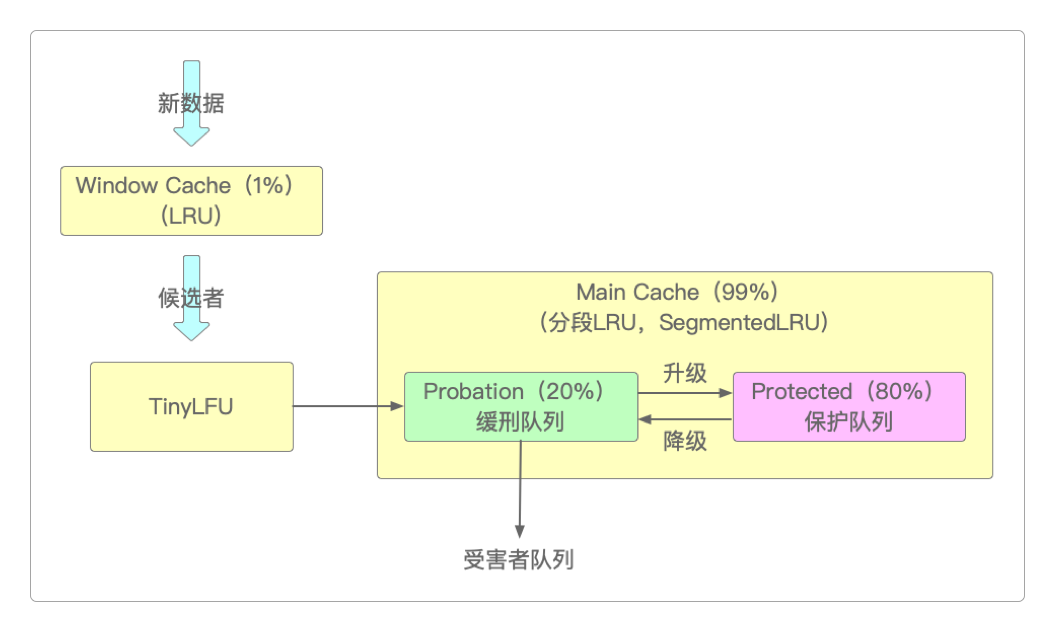
窗口缓存
Window Cache使用没有任何回收策略的LRU,占总缓存大小的1%,用于存储新到来的数据,主要为应对短期流量突发的访问场景。主缓存
Main Cache使用分段SLRU+ TinyLFU,占总缓存大小的99%。其中
SLRU又被分为两个区。Probation区,用于存储比较冷门的数据,占用主缓存20%空间。Protected区,用于存储比较热门的数据,占用主缓存80%空间。
新添加的数据首先放入窗口缓存
Window Cache(LRU)中,同时由TinyLFU完成计数。如果
Window Cache满了,就把Window Cache淘汰的数据转移到主缓存Probation区中。如果
Probation区还未满,并且其中的数据在后续操作中再次被访问时,那么该条数据会进入Protected区。如果
Probation区也满了,就比较从窗口缓存Window Cache转移过来的数据(候选者)和Probation要淘汰的数据(受害者)。首先获取TinyLFU中记录的候选人和受害者的频率。
如果候选者频率 > 受害者频率,则淘汰受害者。
如果候选者频率 <= 5,则淘汰候选者。
其余情况随机处理。
如果
Protected区也满了,那么会按照LRU策略将数据驱逐到Probation区
其实W-TinyLFU算法的淘汰过程和JVM GC过程非常像。
在区域划分上
Window Cache对应S0和S1。Probation区对应Eden区。Protected区对应老年代。
在数据淘汰流程上
先进入
Window Cache(S0和S1)。再进入
Probation区(Eden区)或从Probation区淘汰。再进入
Protected区(老年代)或从Protected区淘汰。
感谢支持
更多内容,请移步《超级个体》。