
爬取应用说明
原创大约 2 分钟
网络爬虫是一种互联网数据的自动化采集程序,主要作用是代替人工对网络中的数据进行自动采集与整理,以快速地、批量地获取目标数据。
从技术手段来说,网络爬虫有多种实现方案,如PHP、Python(Urllib、Scrapy、Selenium)等。
但网络爬虫的难点并不在于编程语言和程序代码,而在于网页的分析与反爬问题的处理。
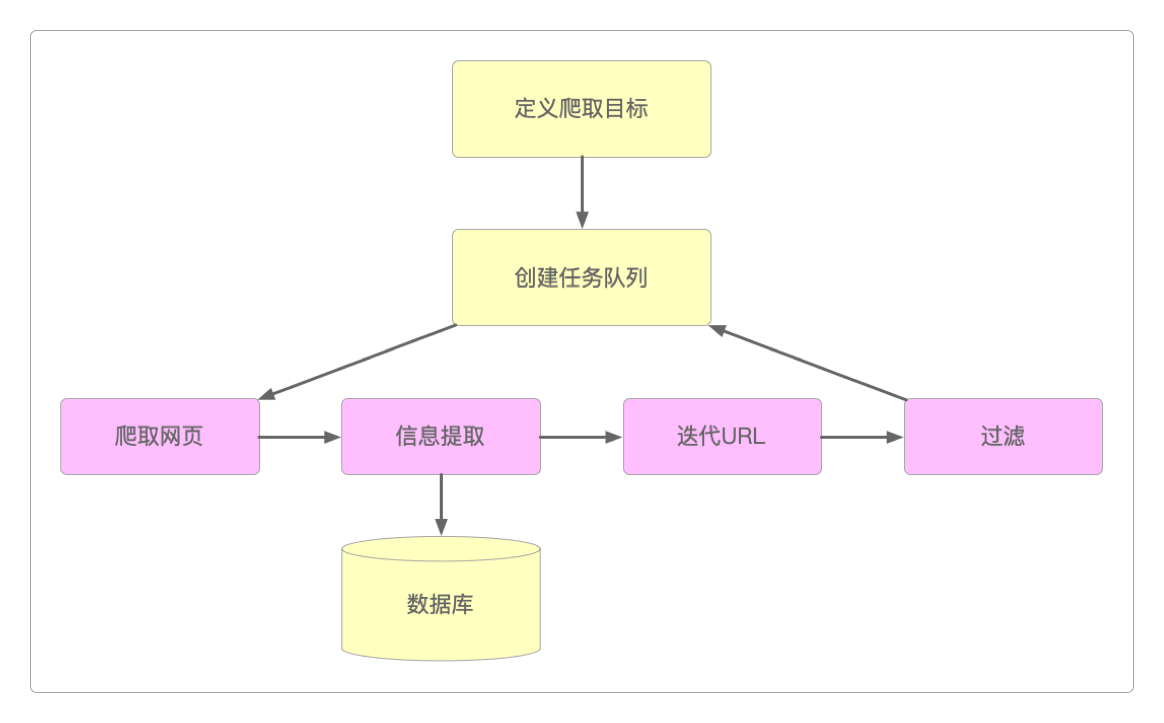
网络爬虫应用一般分为下面几类。
定向爬虫:专门针对某个网站进行的数据爬取,需要根据目标网站制定专门的爬取策略。通用爬虫:针对某个行业的数据进行爬取,例如,所有电商网站的商品数据。深层爬虫:具有一定的交互能力,能绕过大多数的反爬机制,爬取深层数据。
除了对基本工具(urllib、requests、beautifulsoup)和技巧的使用,要想克服诸多反爬的限制,还需要更多高级的方法。
通过网络爬虫抓取数据的总体流程思路不外乎下面几步。
明确需求
目标网址
目标数据
存储格式
抓包分析
代码实现
发送请求:常用的有urllib、requests和beautifulsoup模块,一般还需要配合各种
用户池、IP池、请求头等手段,或者模拟浏览器的点击、滑动等用户行为。获取数据:可以将返回的响应数据解析成文本、JSON格式或二进制数据。
解析数据:按照抓包分析中确定有效的关键字进行正则匹配来提取数据。
保存数据:一般都会保存到
csv文件或数据库中。
这里就分别展示这些高级方法和几种不同类型的爬虫应用程序。
关注公众号后回复 爬虫 即可获得Python分布式爬虫栏目剩余文章的访问密码。
