
池构建技术
原创大约 6 分钟
用户代理池
from urllib import request
import re
import random
# 用户代理池
pools = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
# 每次都随机选择一个User-Agent
def agent():
# 随机选择一个User-Agent
ua = random.choice(pools)
ua = ("User-Agent", ua)
opener = request.build_opener()
opener.addheaders = [ua]
request.install_opener(opener)
# print("当前使用的User-Agent:" + str(ua))
for i in range(0, 10):
try:
agent()
url = "http://baike.baidu.com/item/" + str(i + 1)
data = request.urlopen(url).read().decode("utf-8", "ignore")
pat = '<h1 class="lemmaTitle_pFwpd J-lemma-title">(.*?)</h1>'
rst = re.compile(pat, re.S).findall(data)
for j in range(0, len(rst)):
print(rst[j])
print("------------------------")
except Exception as e:
print(e)IP代理池
第一种方案
第一种IP代理池的方案和用户代理类似,只需要将池中的内容换成IP就行了。
# IP代理池(第一种方案:使用固定IP)
from urllib import request
import random
ippools = [
"127.0.0.1:8888",
]
def ip(ippools):
# 随机选择一个ip
ip = random.choice(ippools)
# print("当前使用的IP:" + str(ip))
proxy = request.ProxyHandler({"http": ip})
opener = request.build_opener(proxy, request.HTTPHandler)
request.install_opener(opener)
for i in range(0, 5):
try:
# 随机选择一个ip
ip(ippools)
url = "http://www.baidu.com/"
data = request.urlopen(url).read().decode("utf-8", "ignore")
fh = open("~/" + str(i) + ".html", "wb")
fh.write(data)
fh.close()
except Exception as err:
print(err)第二种方案
这种方案是通过购买IP服务商提供的动态IP接口来实现的。
# IP代理池(第二种方案:使用IP代理)
from urllib import request
import time
# 调用动态IP接口
# ip_pools:动态IP池
# target_url:要爬取的目标网页地址
# api_url:动态IP接口地址
def use_ip(ip_pools, target_url, api_url):
# 调用动态IP接口
def api(api_url):
print("调用了接口")
request.urlcleanup()
result = request.urlopen(api_url).read().decode("utf-8", "ignore")
return result
# 将IP添加到IP池
def ip(ip_pools):
print("当前用的IP是:" + ip_pools)
proxy = request.ProxyHandler({"http": ip_pools})
opener = request.build_opener(proxy, request.HTTPHandler)
request.install_opener(opener)
# 如果IP池为空,则调用动态IP接口
if ip_pools == 0:
# 验证IP是否有效
while True:
ip_pools = api(api_url)
print("提取IP完成")
ip(ip_pools)
print("正在验证IP有效性")
data = request.urlopen("http://www.baidu.com").read().decode("utf-8", "ignore")
if len(data) > 5000:
print("当前IP有效")
break
else:
print("当前IP无效,重新切换......")
time.sleep(15)
else:
# 将生成的IP添加到IP池
ip(ip_pools)
# 爬取网页
data = request.urlopen(target_url).read().decode("utf-8", "ignore")
return ip_pools, data
# 统计爬取网页的次数
count = 0
# 动态IP接口
api = 'http://api.xxx.com/...'
for i in range(0, 35):
try:
url = "http://www.baidu.com"
# 每爬取2次就换一次IP
if i % 2 == 0 and i == 0:
ips, data = use_ip(0, url, api)
elif i % 2 == 0:
print("正在延时中...")
time.sleep(15)
print("延时完成,调取IP")
ips, data = use_ip(0, url, api)
print("IP调取完成")
else:
ips, data = use_ip(ips, url, api)
print(len(data))
count += 1
except Exception as err:
print(err)
count += 1第三种方案
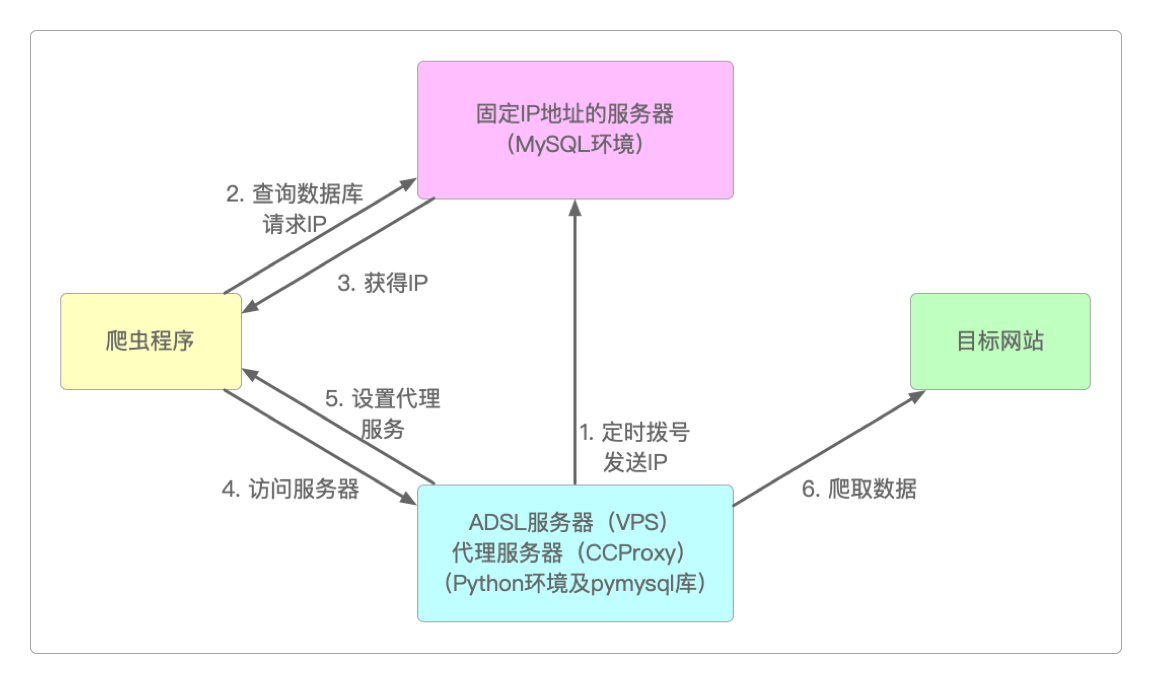
ADSL自动拨号程序代码如下。
'''
ADSL自动拨号程序
'''
import os
import time
from urllib import request
import re
import pymysql
# 自动变换IP
class ChangeIP():
def __init__(self, mysql_inform, adsl_user, adsl_passwd, proxy_port, randid):
self.mysql_inform = mysql_inform
self.adsl_user = adsl_user
self.adsl_passwd = adsl_passwd
self.proxy_port = proxy_port
self.randid = randid
def getip(self):
try:
data = request.urlopen("http://xxx.yyy.com/test").read().decode("utf-8", "ignore")
pat = '您的IP是:\[(.*?)\]'
self.thisip = re.compile(pat, re.S).findall(data)[0]
return self.thisip
except Exception as err:
return 0
def change(self):
while True:
try:
self.myconn = pymysql.connect(host=mysql_server["hostname"],
user=mysql_server["username"],
passwd=mysql_server["password"],
port=mysql_server["port"],
db=mysql_server["db"])
break
except Exception as err:
pass
# 更新数据库,暂时锁住数据库
sql3 = "update iptable set status = '2' where randid = '" + str(randid) + "'"
self.myconn.query(sql3)
self.myconn.close()
os.system("rasdial 宽带连接 /disconnect")
os.system("rasdial 宽带连接 " + str(self.adsl_user) + " " + str(self.adsl_passwd))
def save2db(self):
while True:
try:
self.myconn = pymysql.connect(host=mysql_server["hostname"],
user=mysql_server["username"],
passwd=mysql_server["password"],
port=mysql_server["port"],
db=mysql_server["db"])
break
except Exception as err:
pass
sql = "update iptable set status = '1', port = '" + str(self.proxy_port) + "', ip = '" + str(
self.thisip) + "' where randid = '" + str(self.randid) + "'"
self.myconn.query(sql)
self.myconn.close()
mysql_server = {"hostname": "12.34.56.78", "username": "root", "password": "123456", "port": 3306, "db": "iplib"}
adsl_user = "xxx"
adsl_passwd = "yyy"
proxy_port = "808"
randid = "123456"
# 初始拨号
os.system("rasdial 宽带连接 /disconnect")
os.system("rasdial 宽带连接 " + str(adsl_user) + " " + str(adsl_passwd))
time.sleep(3)
print("初始拨号完成")
# 数据库配置
conn = pymysql.connect(host=mysql_server["hostname"],
user=mysql_server["username"],
passwd=mysql_server["password"],
port=mysql_server["port"],
db=mysql_server["db"])
print("初始连接完成")
sql1 = ("create table iptable(id int(32) auto_increment primary key, "
"ip varchar(32), port varchar(32), status varchar(16), "
"randid varchar(32), unique(randid))")
try:
conn.query(sql1)
except Exception as err:
pass
print("数据库创建完成")
sql2 = ("insert into dynamic_ip(ip, port, status, randid) "
"values('12.34.56.78', '") + str(proxy_port) + "', '0', '" + str(randid) + "')"
try:
conn.query(sql2)
except Exception as err:
pass
conn.close()
# 实例化对象
changeip = ChangeIP(mysql_server, adsl_user, adsl_passwd, proxy_port, randid)
print("实例化对象完成")
while True:
while True:
changeip.change()
thisip = changeip.getip()
if thisip != 0:
break
print(thisip)
changeip.save2db()
# 每5分钟换一次IP
time.sleep(300)运行爬虫的机器上的Python代码如下。
自动从MySQL获取最新的IP。
'''
自动获取最新IP
'''
import time
import pymysql
def getip(mysql_server, randid):
conn = pymysql.connect(host=mysql_server["hostname"],
user=mysql_server["username"],
passwd=mysql_server["password"],
port=mysql_server["port"],
db=mysql_server["db"])
sql = "select ip, port, status from iptable where randid = '" + str(randid) + "'"
while True:
cur = conn.cursor()
cur.execute(sql)
result = [i for i in cur]
if (result[0][2] == "2"):
time.sleep(3)
elif (result[0][2] == "0"):
time.sleep(5)
else:
break
conn.close()
return result[0]
# MySQL服务器地址
mysql_server={"host":"12.34.56.78", "username":"root", "password":"123456", "port":3306, "db":"iplib"}
randid="123456"
print(getip(mysql_server, randid))最终爬取数据的代码如下。
'''
爬取微信文章
'''
from urllib import request
import re
import LatestIP
mysql_server = {"hostname": "12.34.56.78", "username": "root", "password": "123456", "port": 3306, "db": "iplib"}
randid = "123456"
key = "python爬虫"
key = request.quote(key)
name = "微信文章_" + str(key)
def use_proxy(ip_info):
ip_host = ip_info[0]
ip_port = ip_info[1]
# 通过代理服务器访问
proxy = request.ProxyHandler({"http": ip_host + ":" + ip_port})
opener = request.build_opener(proxy, request.HTTPHandler)
request.install_opener(opener)
# 循环爬取100篇文章
for i in range(0, 100):
# 从代理服务器获取IP
ip_info = LatestIP.getip(mysql_server, randid)
use_proxy(ip_info)
url = "http://weixin.sogou.com/weixin?oq=&query=" + key + "&type=2&page=" + str(i + 1) + "&ie=utf8"
data = request.urlopen(url).read().decode("utf-8", "ignore")
print(url)
print(len(data))
pat1 = '解析正则表达式'
rst1 = re.compile(pat1, re.S).findall(data)
if len(rst1) == 0:
print("当前页爬取失败")
continue
for j in range(0, len(rst1)):
this_url = rst1[j]
pat2 = 'amp;'
this_url = this_url.replace(pat2, "")
print(this_url)
try:
request.urlretrieve(this_url, filename="~/微信文章数据/" + str(i) + str(j) + ".html")
except Exception as err:
pass两种池共存
可以同时使用用户池和IP池技术来共同完成数据爬取。
'''
同时使用用户代理池和IP代理池
'''
from urllib import request
import time
import random
# 调用动态IP接口
# ip_pools:动态IP池
# target_url:要爬取的目标网页地址
# api_url:动态IP接口地址
def agent_ip(ip_pools, target_url, api_url):
# 调用动态IP接口
pools = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
# 将IP添加到IP池
def api(api_url):
print("调用了接口")
request.urlcleanup()
result = request.urlopen(api_url).read().decode("utf-8", "ignore")
return result
# 如果IP池为空,则调用动态IP接口
def ip(ippools, pools):
thisua = random.choice(pools)
print(thisua)
headers = ("User-Agent", thisua)
thisip = ippools
print("当前用的IP是:" + thisip)
proxy = request.ProxyHandler({"http": thisip})
opener = request.build_opener(proxy, request.HTTPHandler)
opener.addheaders = [headers]
request.install_opener(opener)
if (ip_pools == 0):
while True:
ippools = api(api_url)
print("提取IP完成")
ip(ippools, pools)
print("正在验证IP有效性")
data = request.urlopen("http://www.baidu.com").read().decode("utf-8", "ignore")
if (len(data) > 5000):
print("当前IP有效")
break
else:
print("当前IP无效,重新切换......")
time.sleep(15)
else:
ip(ip_pools, pools)
data = request.urlopen(target_url).read().decode("gbk", "ignore")
return ip_pools, data
# 统计爬取网页的次数
count = 0
# 动态IP接口
api = 'http://api.xxx.com/...'
for i in range(0, 35):
try:
url = "http://www.baidu.com"
if (i % 2 == 0 and i == 0):
ippools, data = agent_ip(0, url, api)
elif (i % 2 == 0):
print("正在延时中...")
time.sleep(15)
print("延时完成,调取IP")
ippools, data = agent_ip(0, url, api)
print("IP调取完成")
else:
ippools, data = agent_ip(ippools, url, api)
print(len(data))
count += 1
except Exception as err:
print(err)
count += 1感谢支持
更多内容,请移步《超级个体》。