
Scrapy框架
常用命令
Scrapy是一个高性能速度快的网络爬虫框架,使用相对简单,容易上手。
Scrapy的常用命令包括下面几个。
scrapy startproject mydemo:创建爬虫项目。scrapy genspider -l:查看可用的爬虫模板。scrapy genspider -t basic 爬虫名 xxx.com:创建爬虫。scrapy crawl 爬虫名:开始爬取目标网站。scrapy list:列出正在使用中的爬虫。
XPath
例如,有下面这样的一个页面。
<html>
<head>
<title>首页</title>
</head>
<body>
<p>123</p>
<p>456</p>
<a href="//a.test.com/go/v/pcdetail" target="_top">链接1</a>
<a href="//b.test.com/go/v/pcdetail" target="_top">链接2</a>
<div class="divclazz" data-type="testing">
<div id="test">测试XPath</div>
</div>
</body>
</html>/html/head/title/text():表示提取<title>标签中的文本内容。//p/text():表示提取所有<p>标签中的文本内容。//a:表示提取所有的<a>标签。//div[@id='test']/text():表示提取id为test的<div>标签中的内容,如果是class则写成@class。//a/@href:表示提取所有<a>标签中href属性的内容。
编写爬虫
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MydemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 爬取网页标题
title = scrapy.Field()而爬虫文件名.py则用于解析爬取到的内容。
import scrapy
# 编辑器可能会提示错误,但其实是正确的
from mydemo.items import MydemoItem
class JdsSpider(scrapy.Spider):
# 爬虫项目名
name = "jds"
allowed_domains = ["jd.com"]
start_urls = ["https://jd.com"]
def parse(self, response):
item = MydemoItem()
item['title'] = response.xpath("/html/head/title/text()").extract()
item['url'] = response.url
yield item完成之后就可以执行爬取动作了。
> scrapy crawl <爬虫项目名>pipelines可以对爬取到的数据进行后续处理。
先在settings.py中取消下面的注释,这样才能开启pipelines。
......
ITEM_PIPELINES = {
"mydemo.pipelines.MydemoPipeline": 300,
}
......然后再编写pipelines中的代码。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class MydemoPipeline:
def process_item(self, item, spider):
# 将爬取到的数据保存到本地文件
with open("./jd.txt", "a+", encoding="utf-8") as f:
f.write(item["title"][0] + "\n")
f.close()
return item运行爬虫就能在文本文件中看到写入的内容了。
settings配置说明
# Scrapy settings for mydemo project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "mydemo"
# 调用的spider模块
SPIDER_MODULES = ["mydemo.spiders"]
NEWSPIDER_MODULE = "mydemo.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "mydemo (+http://www.yourdomain.com)"
# 是否遵循目标网站的robots协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# 并发请求数
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# 是否启用Cookie
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# 默认请求头
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# 设置中间件
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "mydemo.middlewares.MydemoSpiderMiddleware": 543,
#}
# 下载中间件
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "mydemo.middlewares.MydemoDownloaderMiddleware": 543,
#}
# 是否启用扩展
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 启用pipelines
ITEM_PIPELINES = {
"mydemo.pipelines.MydemoPipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"下载中间件
如果在爬取数据的过程中需要处理用户池或代理等事项,都可以通过下载中间件完成。
先在settings中添加用户代理池。
......
UA_POOL = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
......
# 开启下载中间件,中间件文件需要按照指定的设置命名
DOWNLOADER_MIDDLEWARES = {
"mydemo.DownloadMiddler.UserAgentDownloadMiddler": 1,
}然后再编写一个下载中间件。
# 用户代理下载中间件
from mydemo.settings import UA_POOL
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
class UserAgentDownloadMiddler(UserAgentMiddleware):
def __init__(self, user_agent=''):
super().__init__(user_agent)
self.user_agent = user_agent
def process_request(self, request, spider):
user_agent = random.choice(UA_POOL)
request.headers.setdefault('User-Agent', user_agent)爬取当当网
以女装为例,目标网站所要爬取的目标数据的规律如下。
// 分页链接
http://category.dangdang.com/pg1-cid4003844.html
http://category.dangdang.com/cid4003844.html
http://category.dangdang.com/pg2-cid4003844.html
http://category.dangdang.com/pg3-cid4003844.html
// 目标数据所在的标签,包括商品名称、链接、价格和评论数量
<li ddt-pit="1" class="line1" id="xxx" sku="xxx" style="height: 425px;"></li>
<li ddt-pit="2" class="line2" id="yyy" sku="yyy" style="height: 425px;"></li>
<li ddt-pit="3" class="line3" id="zzz" sku="zzz" style="height: 425px;"></li>
……
<li ddt-pit="48" class="line48" id="..." sku="..." style="height: 425px;"></li>可以看到,规律非常明显。
可以直接通过浏览器自带的菜单工具提取页面的XPath。
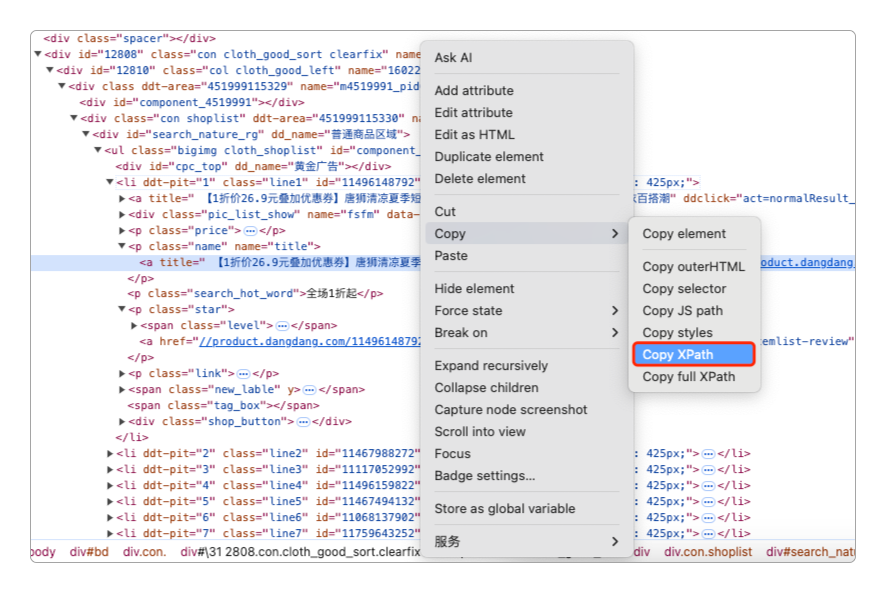
也可以自己写。
<!-- 提取链接中的标题 -->
//a[@name="itemlist-title"]/@title
<!-- 提取链接中的地址 -->
//a[@name="itemlist-title"]/@href
<!-- 提取价格 -->
//span[@class="price_n"]/text()
<!-- 提取评论数 -->
//a[@name="itemlist-review"]/text()通过命令行创建新的爬虫项目。
> scrapy startproject dangdang
> cd dangdang
> scrapy genspider -t basic dd dangdang.com然后依次编写items、pipelines、downloader-middleware(可选),并修改settings中的设置。
'''
items代码
'''
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
comment = scrapy.Field()
link = scrapy.Field()
'''
dd代码
'''
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request
class DdSpider(scrapy.Spider):
name = "dd"
allowed_domains = ["dangdang.com"]
start_urls = ["http://category.dangdang.com/pg1-cid4003844.html"]
file = open("./result.txt", "a+", encoding="utf-8")
file.write("标题\t价格\t评论数\t链接\n")
file.close()
def parse(self, response):
item = DangdangItem()
item['title'] = response.xpath('//a[@name="itemlist-title"]/@title').extract()
item['link'] = response.xpath('//a[@name="itemlist-title"]/@href').extract()
item['price'] = response.xpath('//span[@class="price_n"]/text()').extract()
item['comment'] = response.xpath('//a[@name="itemlist-review"]/text()').extract()
yield item
# 继续提取后续页面
for i in range(2, 41):
next_url = "http://category.dangdang.com/pg" + str(i) + "-cid4003844.html"
yield Request(next_url, callback=self.parse)
'''
pipelines代码
'''
class DangdangPipeline:
def process_item(self, item, spider):
# 在这里处理爬取的内容,例如,可以保存到数据库或本地文件
with open("./result.txt", "a+", encoding="utf-8") as f:
f.write(f"{item['title'][0]}\t{item['price'][0]}\t{item['comment'][0]}\t{item['link'][0]}\n")
f.close()
'''
settings设置
'''
......
UA_POOL = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
......
ROBOTSTXT_OBEY = False
......
ITEM_PIPELINES = {
"dangdang.pipelines.DangdangPipeline": 300,
}然后执行下面的命令运行爬虫。
> scrapy crawl dd感谢支持
更多内容,请移步《超级个体》。