
一般拆分策略
垂直分库
所谓垂直分库,就是将一个大系统按照不同的业务维度切分成不同的子系统,对数据库实施微服务化改造。
例如,前面提到过的纵向分库,解决单一数据库的IO、连接数及资源瓶颈问题,这是相对简单的一种分库方案。
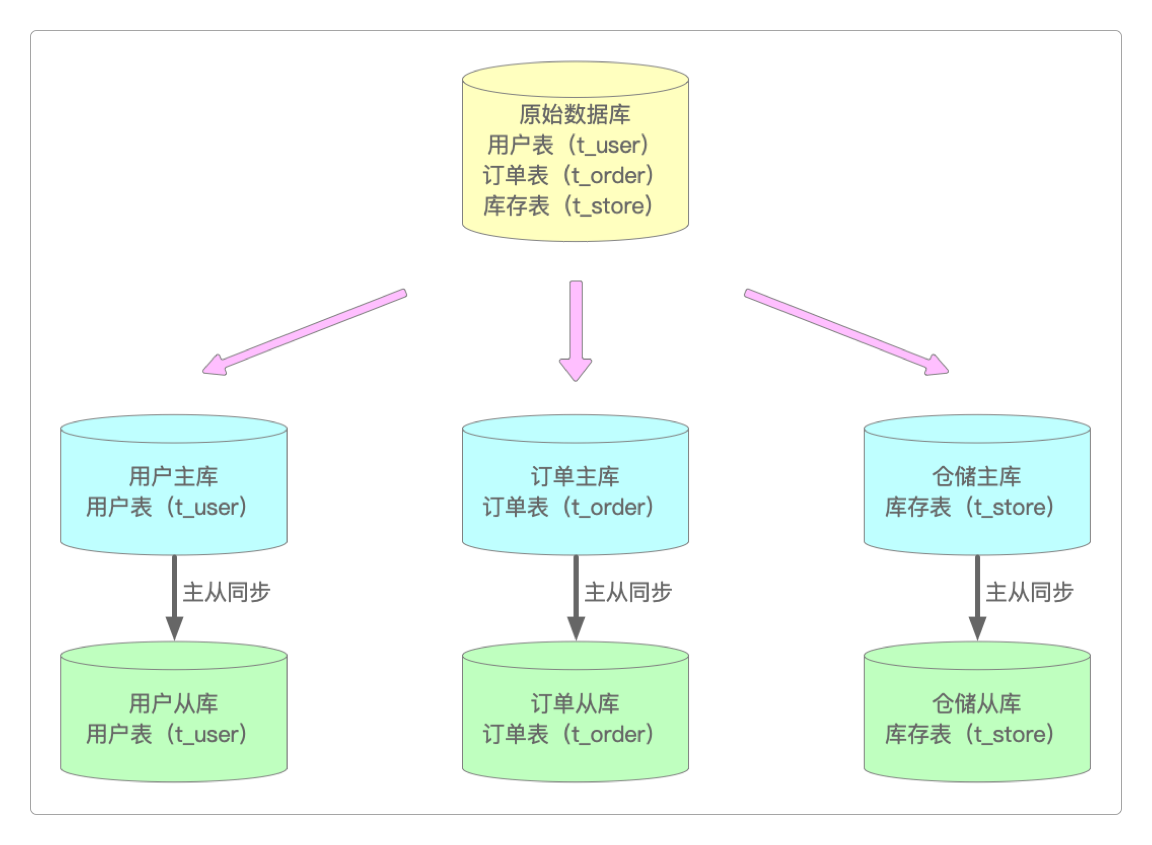
但它依旧没有解决单表数据量过大的问题(例如单表存储超过一亿条数据)。
垂直分表
和直接按照业务维度划分数据表不同,垂直分表是一种粒度更细的操作,它将某张大表中不同的字段按照不同的访问频次进行切分,以达到充分利用IO资源和节约存储空间目的。
例如,可以对数据表按照下面的原则进行拆分。
将不常用的字段单独拆分出来,例如
用户个性签名。将
text、blob这类大字段单独拆分出来(这种数据一般都会存在OSS中)。常在组合查询中出现的字段单独放在一起。
-- 用户表拆分前
> DROP TABLE IF EXISTS t_user;
> CREATE TABLE t_user (
id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '用户编码',
username VARCHAR(32) NOT NULL COMMENT '登录名',
password VARCHAR(32) NOT NULL COMMENT '密码',
salt VARCHAR(32) NOT NULL COMMENT '密码盐',
realname VARCHAR(32) NOT NULL COMMENT '真实姓名',
nickname VARCHAR(32) NOT NULL DEFAULT '佚名' COMMENT '昵称',
identity VARCHAR(18) NOT NULL COMMENT '身份证号',
passport VARCHAR(32) NOT NULL DEFAULT '' COMMENT '护照号',
avatar VARCHAR(256) NOT NULL DEFAULT '' COMMENT '头像',
province VARCHAR(32) NOT NULL DEFAULT '' COMMENT '省份',
city VARCHAR(32) NOT NULL DEFAULT '' COMMENT '城市',
street VARCHAR(128) NOT NULL DEFAULT '' COMMENT '街道',
address VARCHAR(128) NOT NULL DEFAULT '' COMMENT '常住地址',
signature VARCHAR(128) NOT NULL DEFAULT '' COMMENT '个性签名',
cover VARCHAR(256) NOT NULL DEFAULT '' COMMENT '封面地址',
createtime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updatetime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户表';
-- 用户表拆分后
-- 用户表
> DROP TABLE IF EXISTS t_user;
> CREATE TABLE t_user (
id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '用户编码',
username VARCHAR(32) NOT NULL COMMENT '登录名',
password VARCHAR(32) NOT NULL COMMENT '密码',
salt VARCHAR(32) NOT NULL COMMENT '密码盐',
avatar VARCHAR(256) NOT NULL DEFAULT '' COMMENT '头像',
createtime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updatetime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户表';
-- 用户详情表
> DROP TABLE IF EXISTS t_user_info;
> CREATE TABLE t_user_info (
id BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '用户编码',
realname VARCHAR(32) NOT NULL COMMENT '真实姓名',
nickname VARCHAR(32) NOT NULL DEFAULT '佚名' COMMENT '昵称',
identity VARCHAR(18) NOT NULL COMMENT '身份证号',
passport VARCHAR(32) NOT NULL DEFAULT '' COMMENT '护照号',
province VARCHAR(32) NOT NULL DEFAULT '' COMMENT '省份',
city VARCHAR(32) NOT NULL DEFAULT '' COMMENT '城市',
street VARCHAR(128) NOT NULL DEFAULT '' COMMENT '街道',
address VARCHAR(128) NOT NULL DEFAULT '' COMMENT '常住地址',
signature VARCHAR(128) NOT NULL DEFAULT '' COMMENT '个性签名',
cover VARCHAR(256) NOT NULL DEFAULT '' COMMENT '封面地址',
createtime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updatetime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户详情表';水平分表
任何系统所能处理的数据量终归是有限的,当数据表中存储的数据超过千万条的时候,查询一次所花费的时间必然要大于那些仅仅存储百万条记录的表。
水平分表等同于之前提到过的横向分表,就是把一张大表中的数据分割到多张小表中。这些小表的数据字段都是一样的,但是存储的数据不同。
通常对数据进行分割的办法无外乎下面几种。
对指定的某一列(通常是主键列)进行
Hash计算,得到的Hash值的尾数对某个数取模,将结果相同的记录放到一张表中。按照指定的范围(例如主键键值范围,或者日期时间范围,或者地理空间范围,或者业务维度范围)进行区分,将不同的数据保存到不同的数据表中去。
混合以上两种方式对数据进行分割。
这种划分方式尽管解决了单表数据过大的问题,但单库资源瓶颈的问题依然没有解决。
水平分库
为了同时解决单表数据过大和单库资源瓶颈的问题,这种方式将水平分表后的不同子表存储在了不同的数据库中。
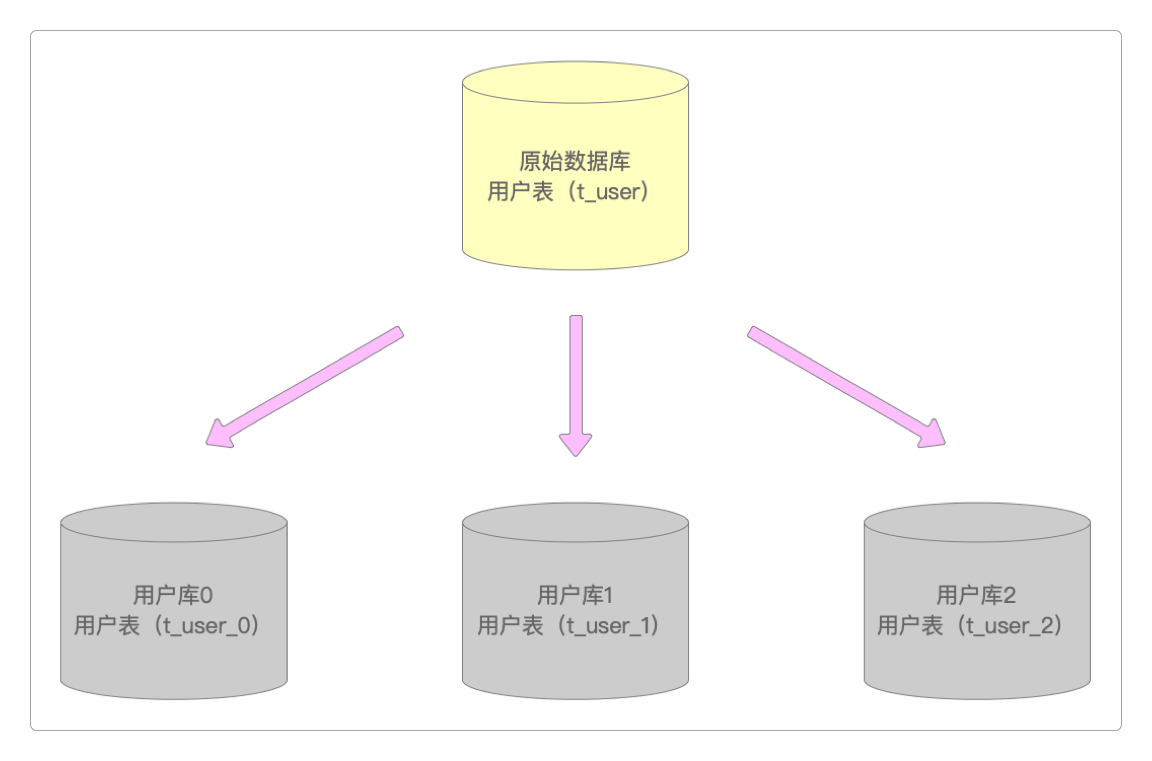
实际上,分库分表就是为了解决单库单表数据量过大的问题而产生的,所以水平分库策略更为常见,在使用它时一定要选择合适的分片键和分片策略,否则会造成数据访问不均匀以及难于扩容等问题。
感谢支持
更多内容,请移步《超级个体》。