
AI提示词极简指北
如果没有鼠标键盘,人们就无法输入需要计算机处理的数据,也就与计算机进行快速有效地交互。对于AI来说,Prompt(提示词)就是它的鼠标和键盘,是一种用于和人工智能进行有效交互的指导性文本。通过Prompt,可以让那些绘画的大模型按照我们的想法生成图像。
现在网络上关于AI的资料不是太少,而是太多了,多到让人分不清到底哪些有用,哪些没用。而且大部分晦涩难懂,都是一大堆资料直接丢过来,让人发懵。
既然叫提示词,那就说明它只能起到 提示 作用,而且即使用完全相同的提示词生成1000张图片,这1000张图片也可能都完全不一样。想把一个根本上就很模糊笼统的东西搞成精确的操作,纯属做无用功——更别说它本身还在不断进化中!
我自己根据网络上诸多资料,经过整理并实测后形成了一份极简学习参考(仅供参考),力图去掉一切不必要的干扰杂质,力求 精和干。
友情提醒
所有可学习的开源AI知识都无需付费!

自造提示词
要用提示词念咒语,最直接的方法就是自己造。
宏观大类
从宏观的角度来看,提示词按照不同维度,分为如下众多大类(并且大类的数量和更细节的小类还在不断增加)。
- 风格
- 影游
- 大师
- 灯光
- 材质
- 色系
- 视角
- 场景
- 人像
- 时尚
- 布局
- 建筑
- 国风
以大师举例,那么与之相关的部分提示词的效果如下。

这些提示词的英文完全可以自己在翻译软件上生成,例如莫奈,换成提示词就是Claude Monet style,其余类似。
再比如以灯光效果为例,与之相关的部分提示词的效果如下。
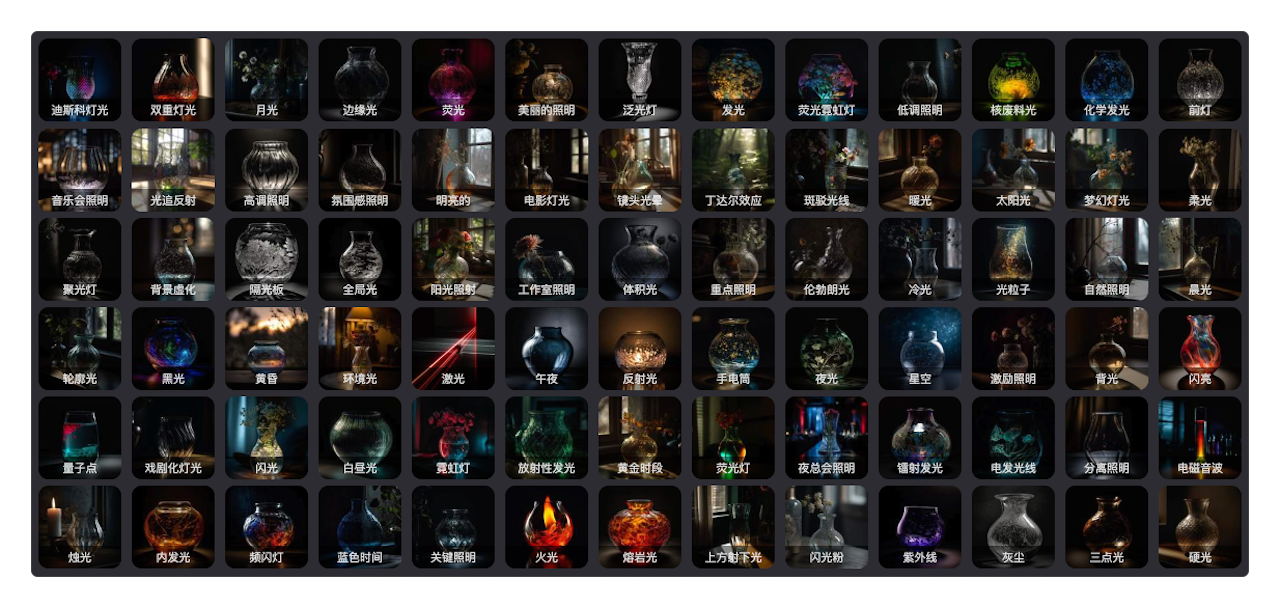
将它与其他众多提示词组合到一起,就会生成自己想要的图片,但生成的图片不是精确的,而是笼统的。
微观小类
在确定了大方向上的风格之后,接下来调整细节。这些细节数量极其之多,我个人的感觉基本上就是把英文字典给拷贝了一遍。
不过尽管如此,还是可以借助工具来提高效率,推荐下面这几个网站。一是因为比较全面,简单易用。二是比较正向,没有那么多乱七八糟的东西。
使用这些工具,然后点点鼠标,就可以得到大量关于细节描述的提示词。
不管是Midjourney还是Stable Diffusion,所有的提示词默认权重都是1,但它们在权重的处理方式上是不同的。
Midjourney权重
所有单词的默认权重均为1,但开头的单词比结尾的单词对结果的影响更大。
,逗号是软中断,::是硬中断。逗号分隔符表示这些是不同的概念,而::则表示注意这些是不同的概念,将符号分隔之间的所有内容都视为一个概念集合,且它不必具有语法意义。可以单独使用
::,也可以在它后添加一个数字,例如::2或::10。还可以添加负图像权重,例如
::-1,Midjourney将尝试消除负权重的任何内容。--no命令与以::-0.5权重分配的效果相同。
为了直观地对比效果,只需要看看这几个例子就行了。
| 提示词 | 图像 | 说明 |
|---|---|---|
| wood:: teapot |  | 如果不在::之后指定权重,则默认为1 |
| wood::2 teapot::1 |  | 实际上不需要在teapot后面加上::1,因为默认权重是1,把它包括在内只是为了对比更明显 |
| wood::3 teapot::1 |  | |
| wood::4 teapot::1 |  | |
| wood::5 teapot::1 |  |
这样对比来看,效果就非常直观了。
Stable Diffusion权重
Stable Diffusion有两种方式处理提示词的权重。
用英文括号表示:每一层[]表示权重×0.9(减少),而{}表示×1.05,()表示×1.1。所以(((wood)))表示木头的权重为1.331。英文括号 + 数字表示:(wood:1.5)表示木头的权重是1.5。
Stable Diffusion提示词权重的安全范围一般在1±0.5左右,太高容易扭曲画面的内容。

权重的混合、迁移和迭代。
white | black wood:表示混合生成黑白相间的木头。[white | black] wood:表示先生成白色的木头,再生成黑色的木头。white wood:bush:0.8:表示在生成进程达到80%之前先创建白色的木头,在达到80%之后将生成木头改为生成灌木(bush)。
另外一些补充规则。
只有Stable Diffusion才有Negative Prompt(负向提示词),而Midjourney是没有这些的。
Midjourney相关参数
基本参数
“尺寸”参数
--aspect
或
--ar表示宽高比,这两个参数可以改变生成图片的宽和高,默认值:1:1。例如,在提示词的末尾添加 --ar 2:3 或 --aspect 16:9
“混乱”参数
--chaos <0 ~ 100>
或
--c <0 ~ 100>表示“混乱”值,该参数会影响初始图像网格的变化,较高的混乱值将产生更多不寻常和意想不到的结果和成分。较低的值具有更可靠、可重复的结果,取值范围:0~100,默认为0。

“异样”参数
--weird <0 ~ 3000>
或
--w <0 ~ 3000>表示另类值,此参数为生成的图像引入了古怪和另类的品质,从而产生独特和意想不到的结果,取值范围:0~3000,默认值为0。
该参数适用于5、5.1、5.2、6、niji 5和niji 6。下面是该参数的效果展示。


“质量”参数
--quality <.25, .5, 1>
或
--q <.25, .5, 1>表示图片质量,更高质量的设置需要更长的时间来处理和产生更多细节,适用于模型版本1、2、3、4、5和niji,v5、v5.1和v5.2模型版本下,其默认值为1。

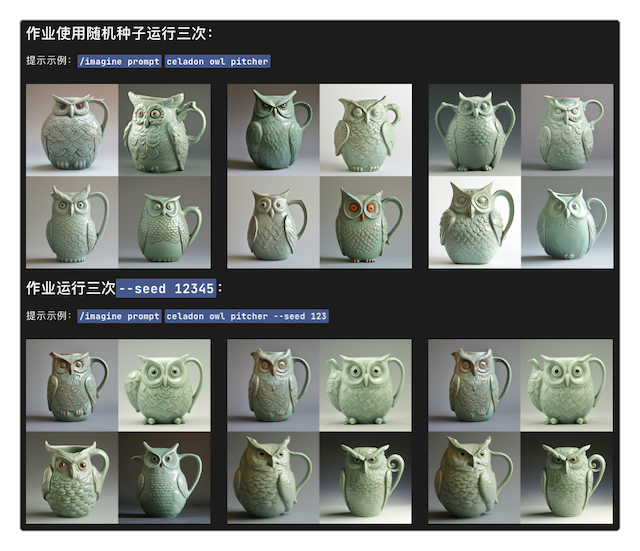
“种子”参数
--seed <0 ~ 4294967295>表示种子值,使用了这个参数,意味着生成图像前所用的初始元素都是类似的,使用相同的种子编号和提示,结果就会产生类似的图片。
使用随机的种子值运行三次,然后再使用相同的种子值运行三次,效果非常明显。
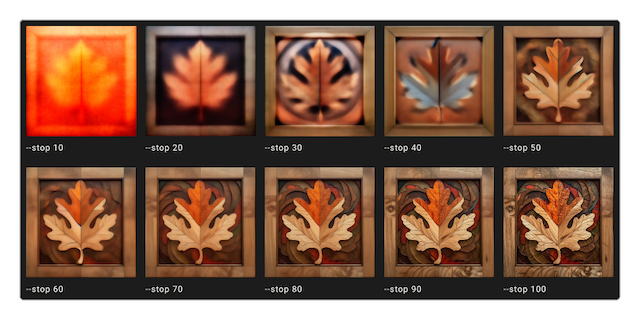
“停止”参数
--stop <10 ~ 100>使用该参数时不会停止作业。较小的值会产生更模糊、不太清晰的图片,该参数默认值100,但用的比较少。
“风格”参数
v4模型为:--style <4a, 4b, or 4c>
v5.2模型或以上为:--style raw
niji v5模型为:--style <original, cute, expressive, scenic>表示切换Model Version 4下的三个版本。
或切换Model Version 5.2以上的写实。
或切换Niji Model Version 5中的四个版本:原始的、可爱的、更具表现力的、更注重场景的。
这几种不同参数的效果,看看官方的示意图就明白了。


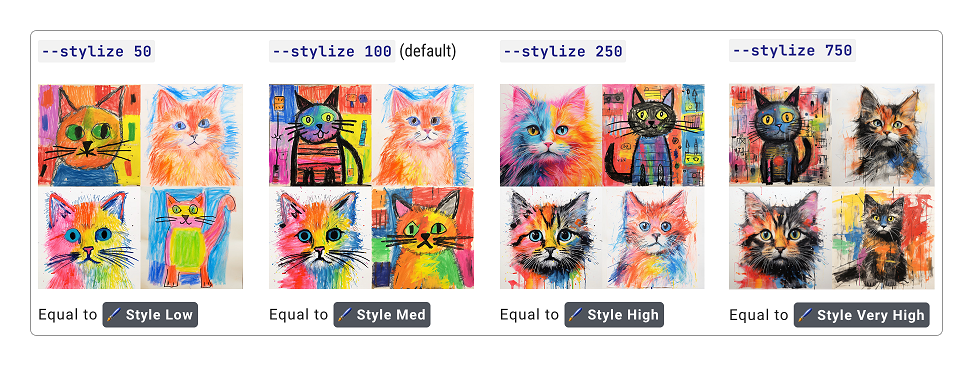
“风格化”参数
--stylize <0 ~ 1000>
或
--s <0 ~ 1000>表示风格化程度,该数值越高,画面表现也会更具丰富性和艺术性,取值范围:0~1000,默认值为100。
Midjourney官方给出的对比也很直观。

“平铺”参数
--tile表示平铺图像,该参数生成可用作重复拼贴的图像,以创建织物、壁纸和纹理的无缝图案,只能用于模型版本1、2、3、5、5.1、5.2和6,默认值100。

风格参考参数
--sref <URL>表示使用指定的图像作为风格参考,借以影响生成的图像风格。

当指定多个URL地址时,也可以给各个样式参考分配不同的权重:--sref URL1::2 URL2::1 URL3::1
该参数还可以指定一个随机值。
--sref random表示从Midjourney知道如何生成的抽象范围中随机选择一种样式。

在生成图像后,随机值将替换为样式参考种子号,例如:--sref random️将被替换为--sref 762351716。
因此可以在将来的提示中使用该样式参考种子来生成相同样式的图像。

风格权重参数
--sw <0 ~ 1000>表示使用样式权重参数来调整样式化的强度,取值范围:0~1000,默认值为100。

风格参考版本参数
--sv 1 原始风格参考算法,更多`vibey`
--sv 2 风格参考的第二次迭代
--sv 3 比`--sv 1`更`vibey`的版本
--sv 4 `--sv 2`的更新版本样式参考功能有四个版本,使用--sv参数在它们之间进行选择,默认为--sv 4。

人物参考参数
--cref <URL>表示使用指定的图像作为风格参考,以在不同情况下创建同一角色的图像。
当生成包含单个角色的图像时,角色参考效果最佳。
--cref不适用于真人照片,并且会扭曲它们。诸如特定雀斑或
T恤徽标之类的精确细节不太可能被复制。--cref可以用于Niji Version 6版本,并可以与--sref一起使用。可以在单个提示中使用多个字符引用。
任何常规图像提示都必须位于
--cref之前。

人物权重参数
--cw <0 ~ 1000>表示设置表征的强度,取值范围:0~100,--cw 0仅关注角色的脸部。较高的值使用角色的脸部、头发和服装,默认值为100。

可以结合风格参考和人物参考来创建更丰富的样式,例如:

重复参数
--repeat <value>
或
--r <value>表示多次运行同一个任务,与其他参数(例如--chaos)结合使用,可以加快视觉探索的速度,该参数只能使用在Fast和Turbo GPU模式下。
Basic版本接受2~4之间的值。Standard版本接受2~10之间的值。Pro和Mega版本接受2~40之间的值。
版本参数
--v <1, 2, 3, 4, 5, 5.1, 5.2, 6>表示用于生成图像的模型版本号。例如,在提示词的末尾添加--v 5.1或--version 5.1,当前最新版本是什么,那默认值就是什么。
“动漫风”参数
--niji表示生成的图像更偏动漫风格(可参考--style效果)。
以上就是常见的参数,更多的可以参考官方的参数表。
尽管Midjourney属于傻瓜式工具,除了提示词外,不再需要操心其他的东西,而Stable Diffusion属于专家级,除了提示词外还需要设定迭代步数、采样方法、CheckPoint/Lora、ControlNet、VAE等。但这两类工具在创作的图片质量和效果上,从整体上来看区别并不大,甚至可以说没有区别。所以它们没有优劣之分,只有使用习惯上的不同。
下面两张图片,左边是Midjourney生成的,右边是Stable Diffusion生成的,如果不明说的话,很难分得清。


下面这两张你觉得是用什么生成的?


抄作业
其实在大多数情况下,我们需要的图像其实已经有人生成过了,而我们要做的只是 抄 - 作 - 业——因为所有的文生图类应用,都会在图像旁边列出生成该图像的提示词。不得不说Midjourney开了个好头😄
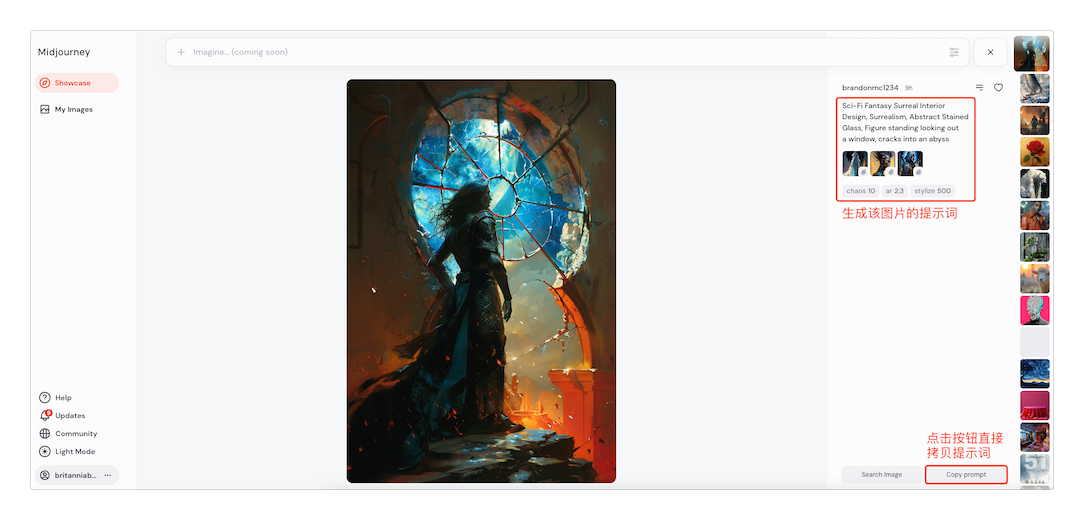
作业比较丰富的除了作为源头的Midjourney之外,去下面这几个站点抄作业还不错:
除了这几个之外,其他的要么是和上面这些差不多,要么是人气惨淡,作品太少。
AI拓词
第三种生成提示词的方法,就是让AI创造AI——也叫 AI拓词。
例如,有下面这样一段文本。
# Midjourney Prompt 助理
你来充当一位有艺术气息的 Midjourney Prompt 助理。
## 任务
我用自然语言告诉你要生成的 Prompt 的主题,你的任务是根据这个主题想象一幅完整的画面,然后转化成一份详细的、高质量的 Prompt,让 Midjourney 可以生成高质量的图像。
## 背景介绍
Midjourney 是一款利用深度学习的文生图模型,支持通过使用 Prompt 来产生新的图像,描述要包含或省略的元素。
## Prompt 概念
- Prompt 用来描述图像,由普通常见的单词构成,使用英文半角 "," 做为分隔符。
- --no 参数用来描述你不想在生成的图像中出现的内容。
- 以 "," 分隔的每个单词或词组称为 tag。所以 Prompt 是由系列由 "," 分隔的 tag 组成的。
## :: 语法
调整关键字权重的方法是使用 ::。 可以在 :: 后面添加数字调整权重值,例如 ::0.5 是将提示词的权重调整为0.5。权重值也可以是负数,例如 ::-0.5 的效果与 --no 参数效果相同。
## Prompt 格式要求
下面我将说明prompt的生成步骤,这里的prompt可用于描述人物、风景、物体或抽象数字艺术图画。你可以根据需要添加合理的、但不少于5处的画面细节。
### 1. Prompt 要求
- 你输出的 Midjourney Prompt 以“Prompt:”开头。
- Prompt 内容包含画面主体、材质、附加细节、图像质量、艺术风格、色彩色调、灯光等部分,但你输出的 Prompt 不能分段,例如类似"medium:"这样的分段描述是不需要的,也不能包含":"和"."。
- 画面主体:不简短的英文描述画面主体, 如 A engineer in office,主体细节概括(主体可以是人、事、物、景)画面核心内容。这部分根据我每次给你的主题来生成。你可以添加更多主题相关的合理的细节。
- 对于人物主题,你必须描述人物的眼睛、鼻子、嘴唇,例如'open detailed eyes, extremely detailed eyes and face, longeyelashes',以免 Midjourney 随机生成变形的面部五官,这点非常重要。你还可以描述人物的外表、情绪、衣服、姿势、视角、动作、背景等。人物属性中,1man表示一个男人,2man表示两个男人。
- 材质:用来制作艺术品的材料。 例如:插图、油画、3D 渲染和摄影。 Medium 有很强的效果,因为一个关键字就可以极大地改变风格。
- 附加细节:画面场景细节,或人物细节,描述画面细节内容,让图像看起来更充实和合理。这部分是可选的,要注意画面的整体和谐,不能与主题冲突。
- 图像质量:这部分内容开头永远要加上“best quality,4k,8k,highres,masterpiece::1.5,ultra-detailed,realistic,photorealistic,photo-realistic:1.37”, 这是高质量的标志。其它常用的提高质量的 tag 还有,你可以根据主题的需求添加:HDR,UHD,studio lighting,ultra-fine painting,sharp focus,physically-based rendering,extreme detail description,professional,vivid colors,bokeh。
- 艺术风格:这部分描述图像的风格。加入恰当的艺术风格,能提升生成的图像效果。常用的艺术风格例如:portraits,landscape,horror,anime,sci-fi,photography,concept artists等。
- 色彩色调:颜色,通过添加颜色来控制画面的整体颜色。
- 灯光:整体画面的光线效果。
### 2. 限制:
- tag 内容用英语单词或短语来描述,并不局限于我给你的单词,注意只能包含关键词或词组。
- 注意不要输出句子,不要有任何解释。
- tag 数量限制40个以内,单词数量限制在60个以内。
- tag 不要带引号("")。
- 使用英文半角 "," 做分隔符。
- tag 按重要性从高到低的顺序排列。
- 我给你的主题可能是用中文描述,你给出的 Prompt 只用英文。
我的第一个主题是: 一个疯狂内卷的中国IT工程师将上面这段内容输入到ChatGPT中,就能让它产生一段我们需要的提示词。
下图为ChatGPT按照要求生成的提示词,尽管它还略显粗糙,但至少它能用了,而且用这种方式一旦将模型训练成功,那就可以批量制造了。

可以看到,所谓AI拓词,其实就是一种适用于ChatGPT这种文生文AI应用的提示词,这也有点类似于临时训练GPT模型。
很多文生文一类的AI公共应用的预训练模型就是这么来的,只不过它们所训练的数据量要大的多而已。
以上的三种方式:自己造、抄作业、AI拓词,基本上就是目前创建提示词的全部了。
感谢支持
更多内容,请移步《超级个体》。