
文图互生
虽然有一些图像生成应用很早就出现了,例如2015年谷歌发布DeepDream,同年出现的Neural Style Transfer,2016年出现的DCGAN,以及加州大学伯克利分校在2017年发布的Pix2Pix和CycleGAN等。
但目前影响力最大的却并不是这些先行者,而后起之秀Midjourney、Stable Diffusion和DALL·E。
实话说,有了Midjourney、Stable Diffusion,其实DALL·E可以无视了。
诸多的应用
文生图类的AI应用也像前面的文生文那样,有一大堆的产品。
这些应用有的可以做插画,有的可以移除背景、抠图,有的可以做无损放大、优化修复,而有的则专门用于电商的商品图生成。
- 插画类。
- 移除背景、抠图类。

- 无损放大、优化修复类。
- 商品图生成类。

作为老牌文生图应用,虽然Midjourney不像ChatGPT那样发布了众多的预训练模型,但从5.2开始,它也能做预训练了,只是效果未经验证。
这里是官方文档。
关于Midjourney的使用,在《AI提示词极简指北》部分已经有了说明。
Stable Diffusion
而Stable Diffusion则是借助Checkpoint、Lora、embedding、VAE等手段,可以自由地训练出自己想要的图像风格。
我本地安装的Stable Diffusion,文生图界面。
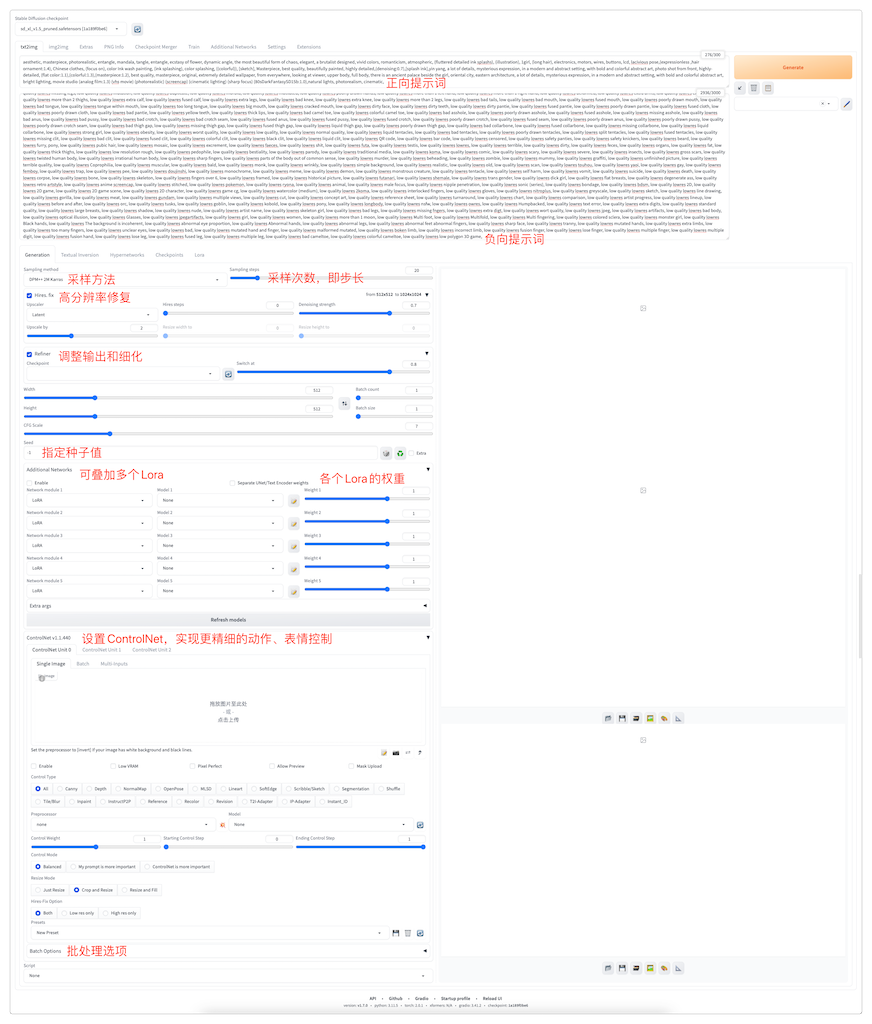
我本地安装的CheckPoint(为什么都是女生模型?因为现在能下载到的,且处理的比较好的基本上都是女生模型😢)。
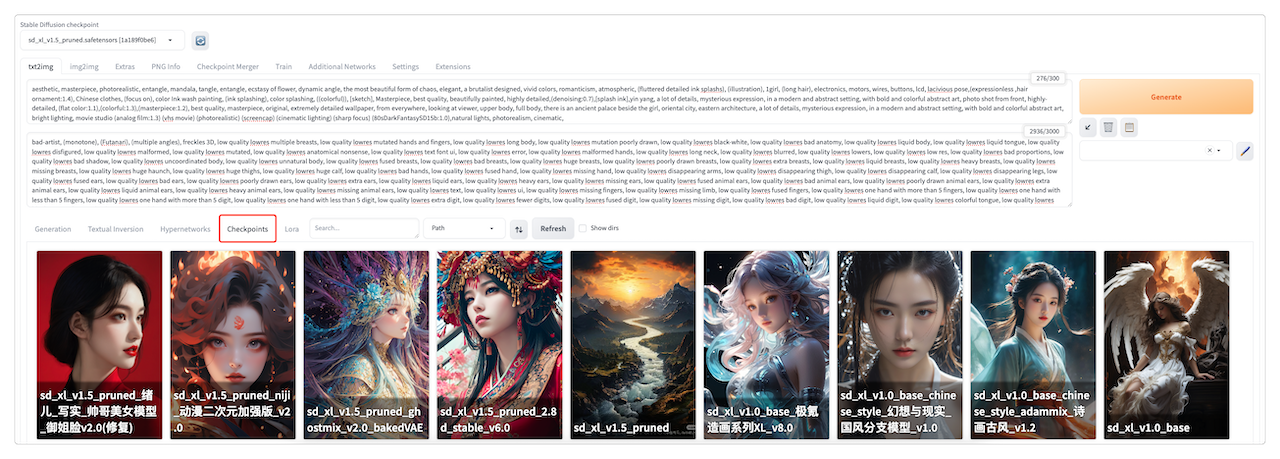
我本地下载的Lora。
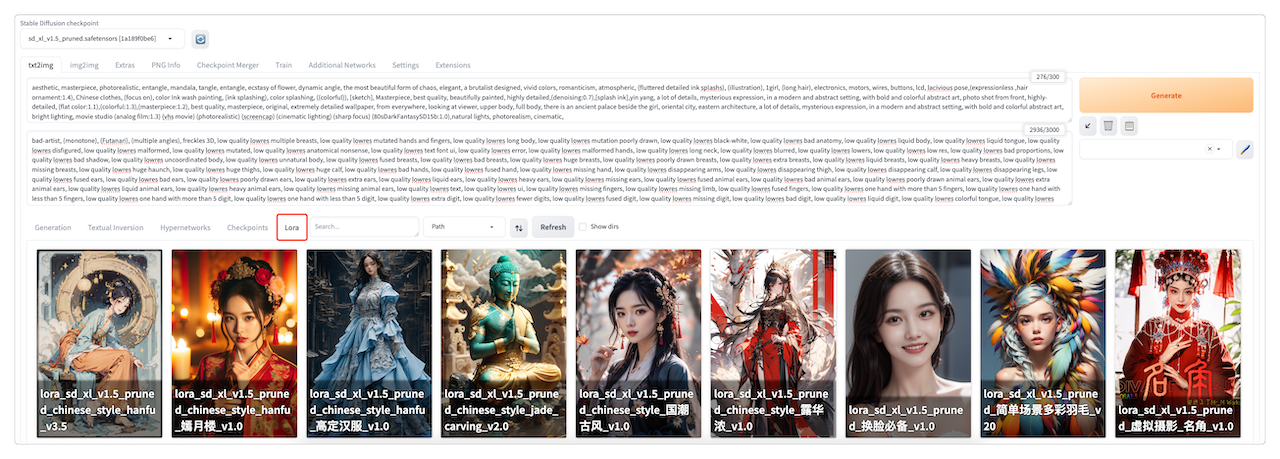
各种Stable Diffusion资源。

要使用DALL·E,就必须付费——暂时没那个需求😢,Stable Diffusion已经很好了😄。
ComfyUI
最近ComfyUI也比较火,通俗地说,ComfyUI是一个流程化的Stable Diffusion,因此,一切Stable Diffusion可以用的资源,它也都可以用,包括CheckPoint、Lora等。
这两个站点可以在线体验ComfyUI。
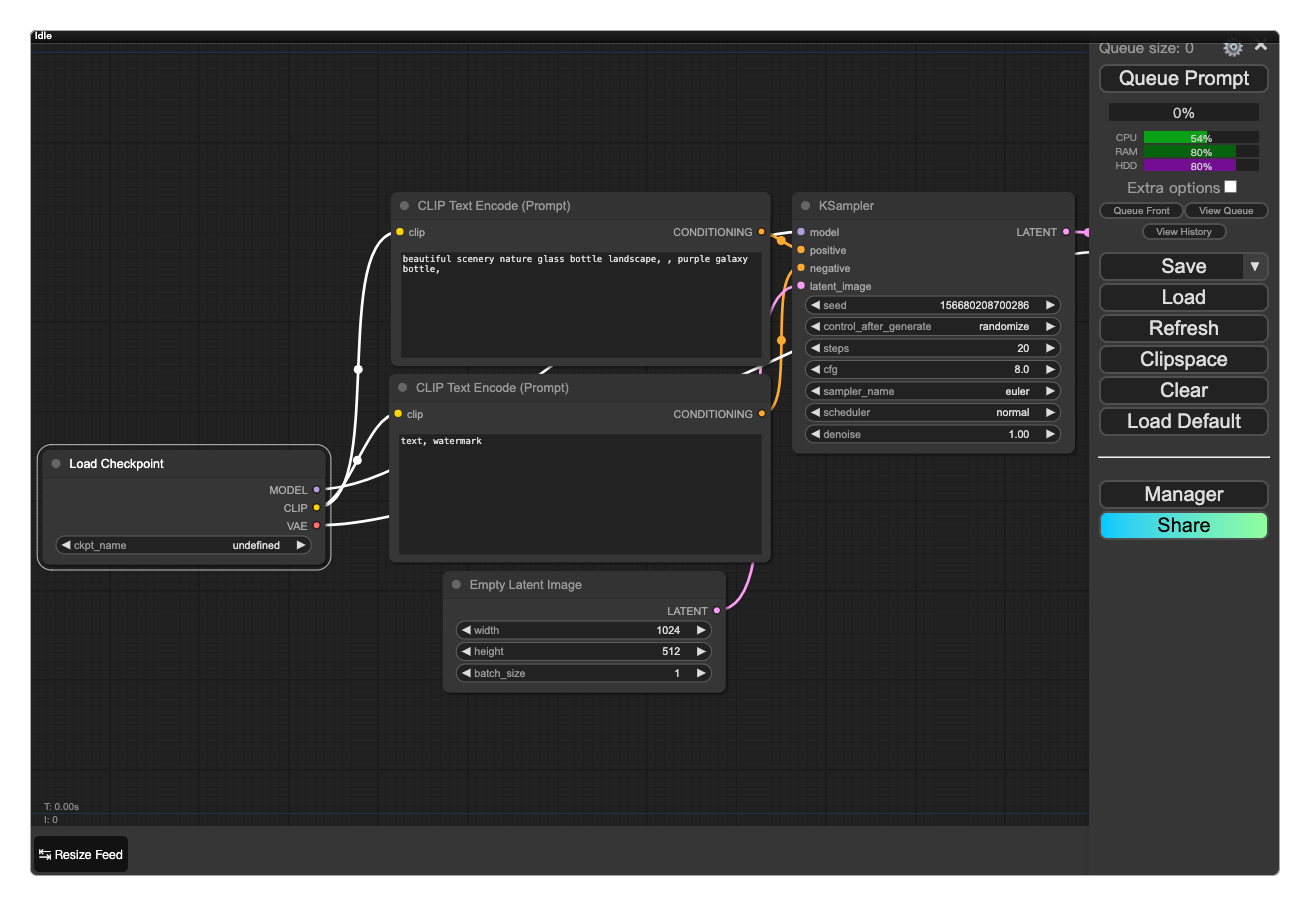
当然,也可以通过下面两种方式搭建自己的ComfyUI服务。
下载ComfyUI源代码,然后在本地搭建,安装过程源代码中有详细说明;
如果机器性能满足不了要求,也可以租用AutoDL或OneThingAI这类AI服务器,在线搭建ComfyUI服务。
如果Stable Diffusion用得比较熟练的话,上手ComfyUI也不难,感兴趣的可以自己玩玩。
下面的几个站点可以下载更多的ComfyUI工作流。
这里有非常详细的在线入门教程。
图生文
在图生文领域,目前可用的应用还寥寥无几,使用最多的应该还是Midjourney。

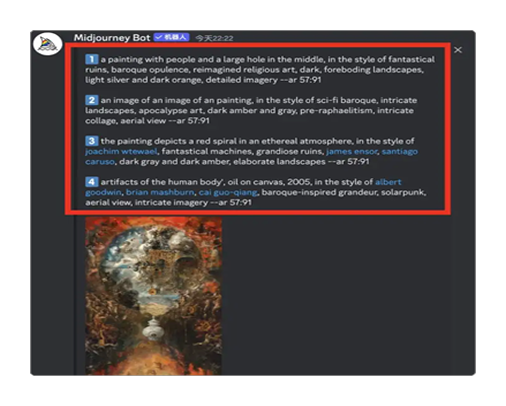
上面右边图中红色方框中的内容,就是通过向Midjourney发送 /describe 命令后得到的。
另一款值得推荐的应用就是SceneXplain,它不仅可以实现图生文,而且也能实现视频生文。
它是一款国外应用,却可以通过微信登录。

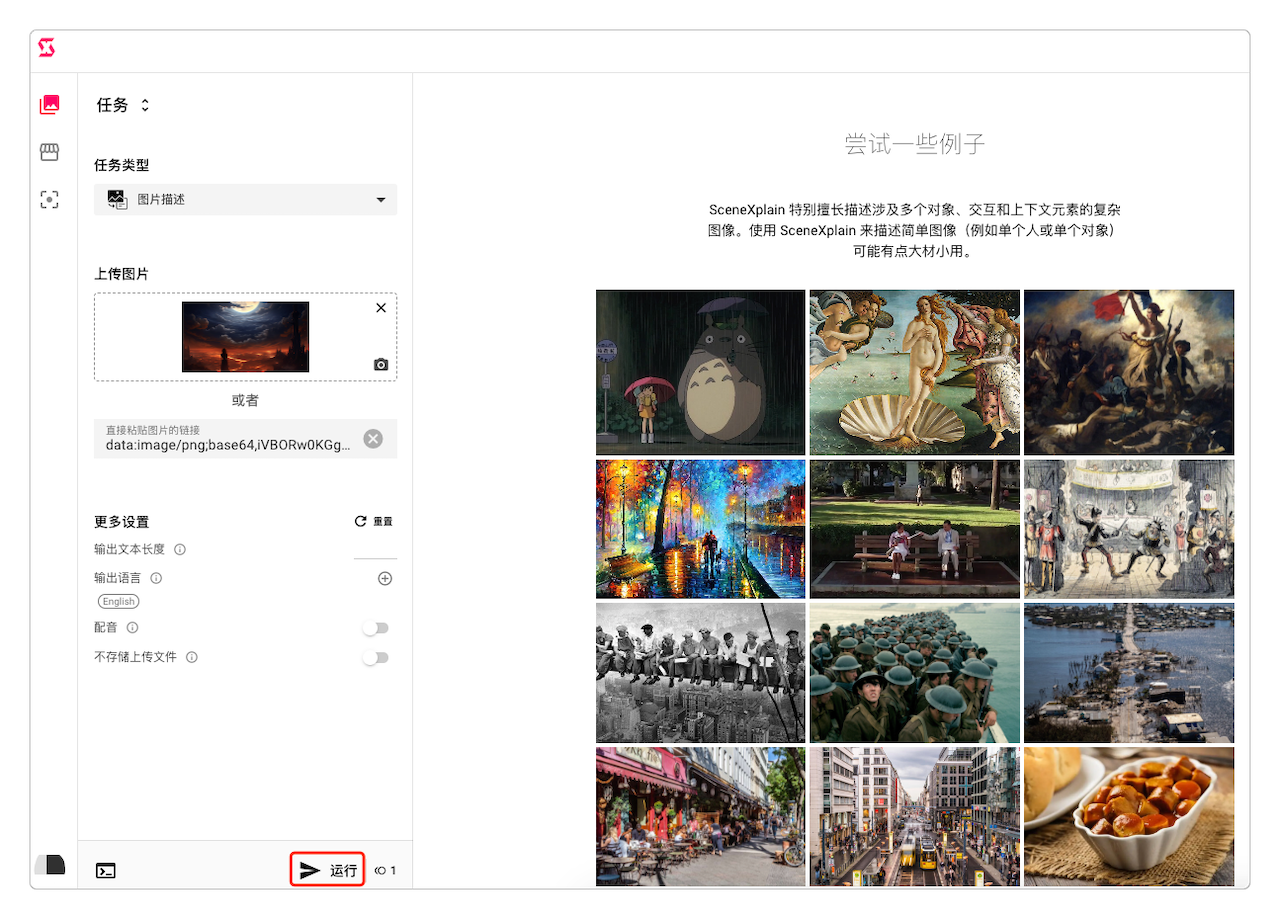
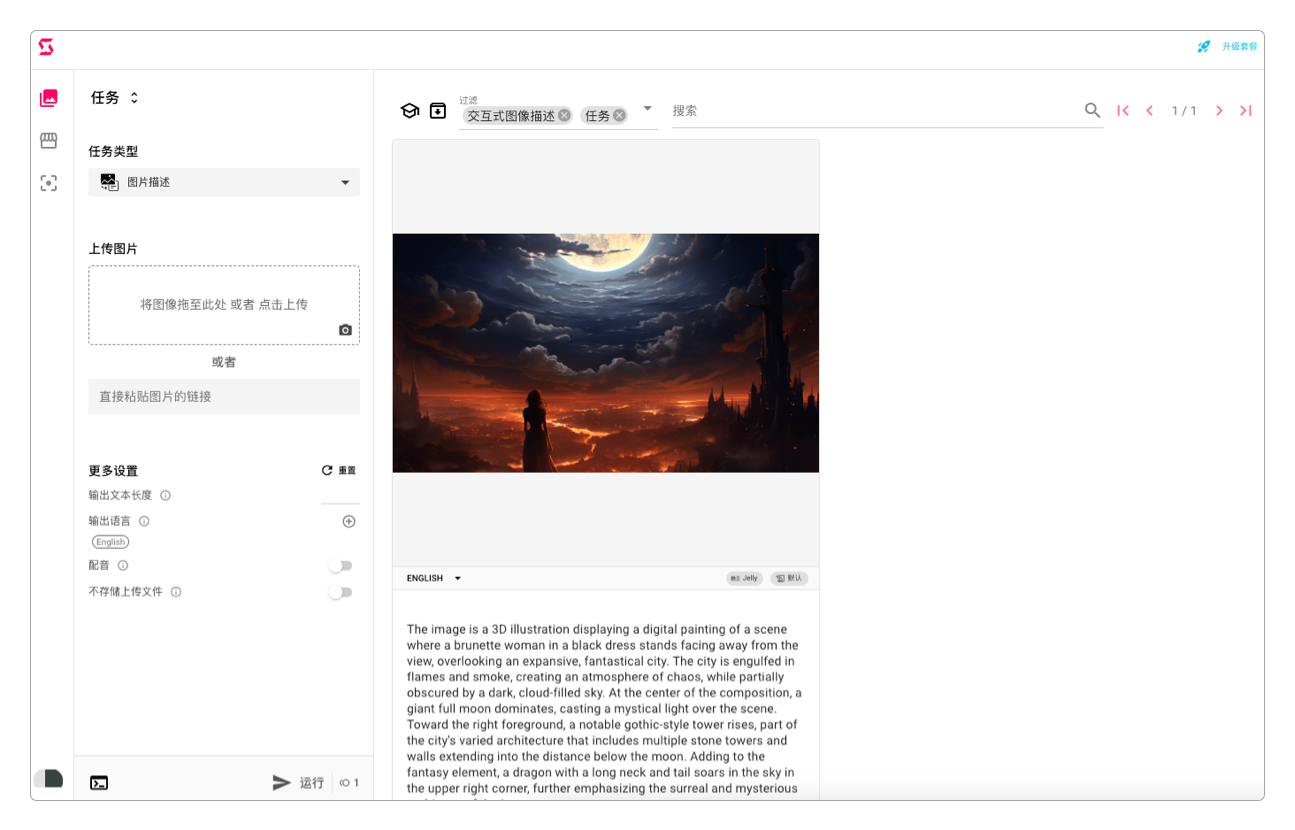
上面就是上传图片到SceneXplain然后被解析成文本的过程。
生成图像的时候也可以选择不同的生成算法。将任务切换为算法即可选择。
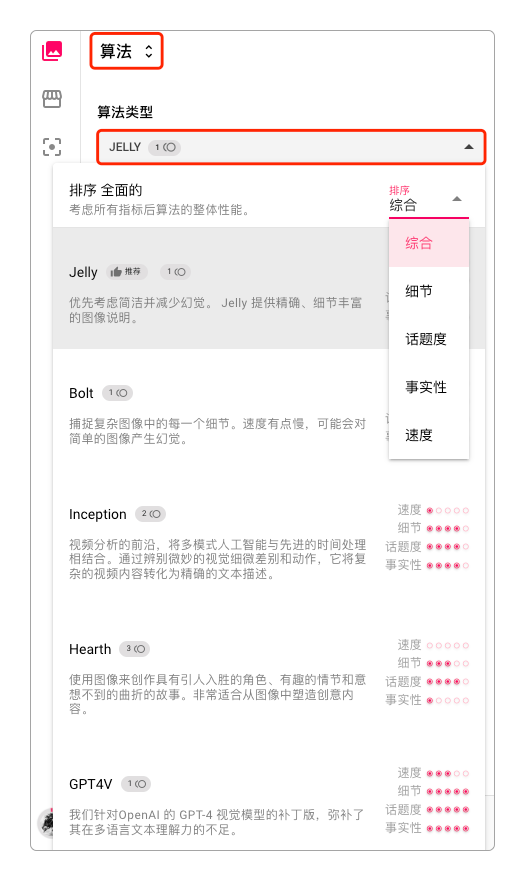
SceneXplain提供了几种不同的算法选择。Jelly、Bolt、Inception、Hearth和GPT4V。
图生图
图生图的方法目前不外乎Midjourney和Stable Diffusion。
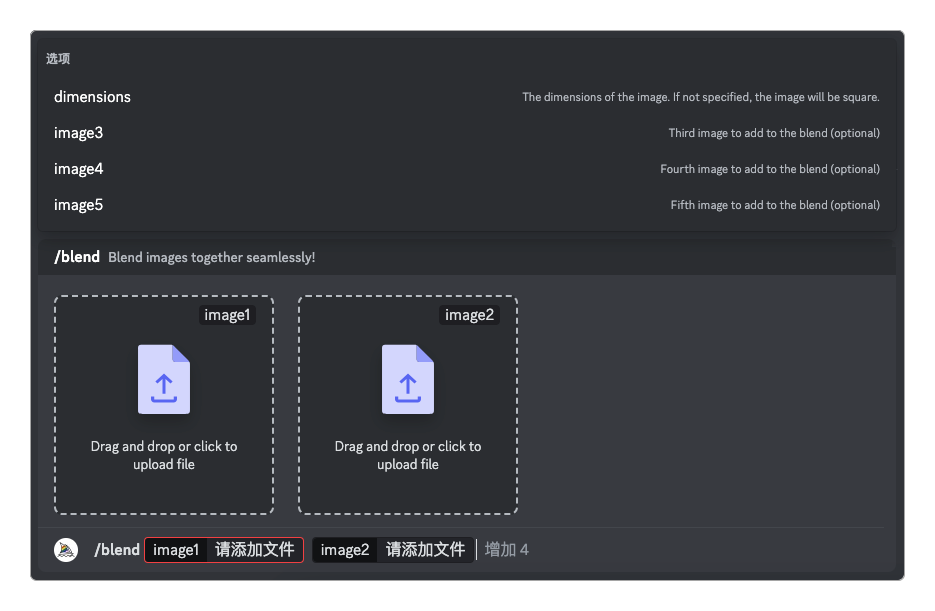
Midjourney提供了专门的图片融合指令 /blend
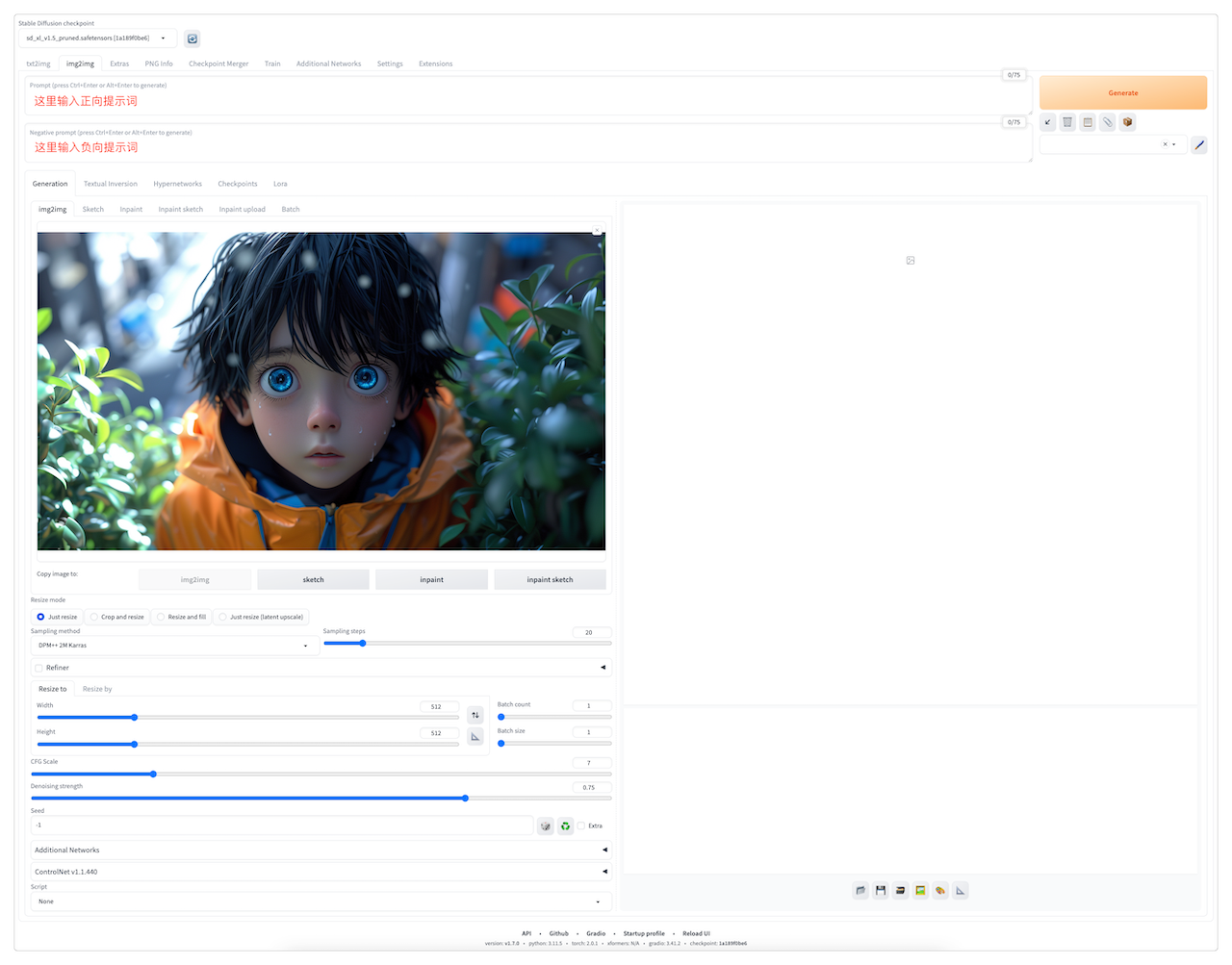
下面是我本地安装的Stable Diffusion,切换到图生图界面。
Midjourney目前可以通过
多张图 + 提示词的方式实现图生图。Stable Diffusion目前只能用
单张图 + 提示词的方式生成新的图片,但可以实现局部重绘。
未来,文图互生的AI应用必将越来越多,也必将越来越精细,因为Midjourney和Stable Diffusion兄弟俩开了个好头!
感谢支持
更多内容,请移步《超级个体》。