
变声
软件变声
要说到音视频方面的应用,不得不提起老牌的ffmpeg——这绝对是多媒体领域泰山北斗一般的存在,几乎所有和音视频处理相关的软件都离不开它的支持。
大多数的音视频播放、处理软件其实都是对它的功能的封装。
# 抽取音频命令
ffmpeg -i test.mp4 -vn -y -acodec copy result.aac
ffmpeg -i test.mp4 -vn -y -acodec copy result.m4a
# 提取视频 (Extract Video)
ffmpeg -i test.mkv -vcodec copy –an test.mp4
# 音视频合成命令
ffmpeg -i video.avi -i audio.mp3 -vcodec copy -acodec copy output.avi
# ffmpeg分离出PCM数据
ffmpeg -i test.mp4 -ar 44100 -ac 2 -f s16le output.pcm
# ffmpeg去除视频水印
# -vf delogo 表示使用ffmpeg中去水印的滤镜
# x=?:y=?:w=?:h=?:show=? 表示delogo滤镜的参数
# x,y 表示去除水印范围在视频中的起始坐标,w,h表示所选的区域的宽高,show表示是否显示矩形框,0表示不显示,1表示显示
ffmpeg -i test.mp4 -vf delogo=x=?:y=?:w=?:h=?:show=? out.mp4在AI流行之前,音频方面的应用就已经出现了,有些是专业的音轨提取工具,但对非专业人士有着不小的门槛。
其中对普通人比较友好而且开源免费的当属spleeter,它也对ffmpeg做了封装,但实现了更多功能的扩展。
按照官方的步骤,安装好之后,通过命令行实现人声分离。
spleeter separate -p spleeter:2stems -o D:/vocals/output D:/vocals/01.mp3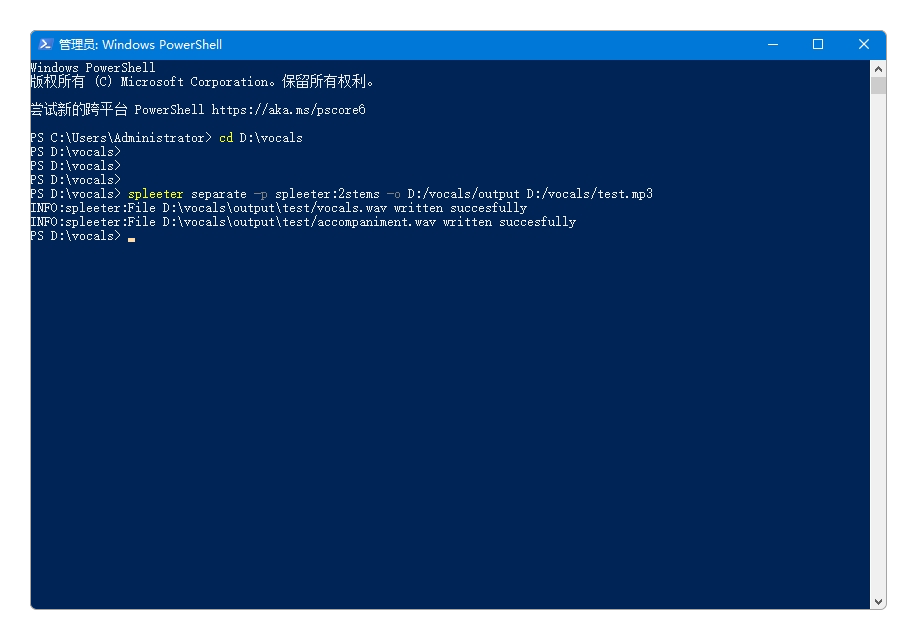
注意
执行spleeter命令时,需要在预训练模型所在的同级目录中执行。上图中的预训练模型 文件夹 D:\vocals\pretrained_models就在目录D:\vocals中,否则会提示执行失败。
这也是我踩过的一个坑,官方没有提到这一点😢,让人折腾了好久。
除了命令行的方式,spleeter还有图形化的界面,下载地址在文末。
AI模型
除了人声分离,另外的一个需求就是创造出独特的音色,或者将一种音色变成另外一种音色。例如,将我说的话变成小岳岳的声音,或者夹子音,或者琵琶音。
对这类需求,spleeter就无能为力了。
可以借助Retrieval-based-Voice-Conversion-WebUI这款开源AI变声器来实现。
它上手还是比较容易的,非常傻瓜化。按照官方的提示先做一下声音的训练。
这里我用的也是谭雅的音效,文末有下载。
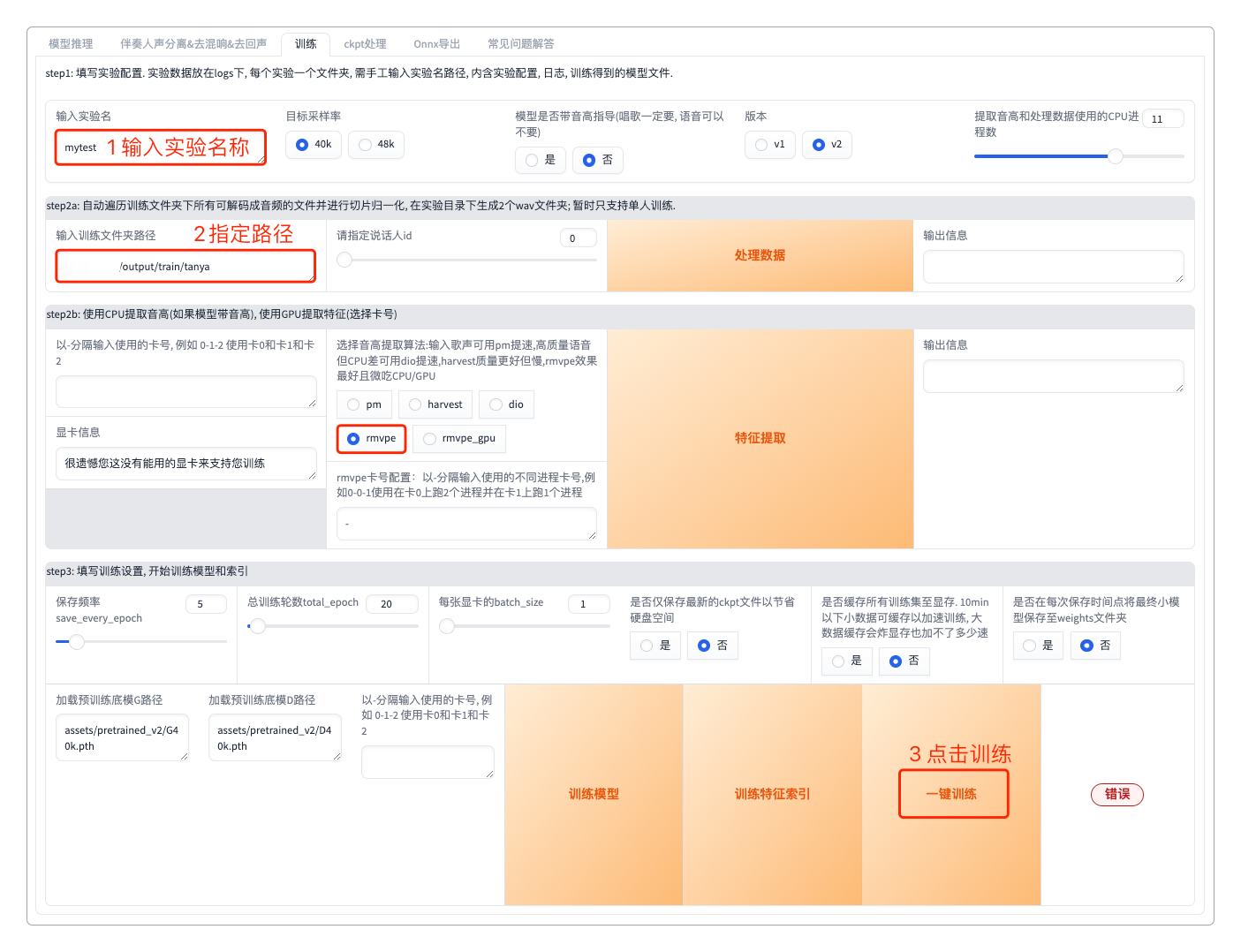
但奈何硬件已经跟不上软件的步伐了,主要是GPU不给力😢。

没办法,只好尝试做一下人声分离,这个倒是成功了。它的分离效果和spleeter几乎完全一样。
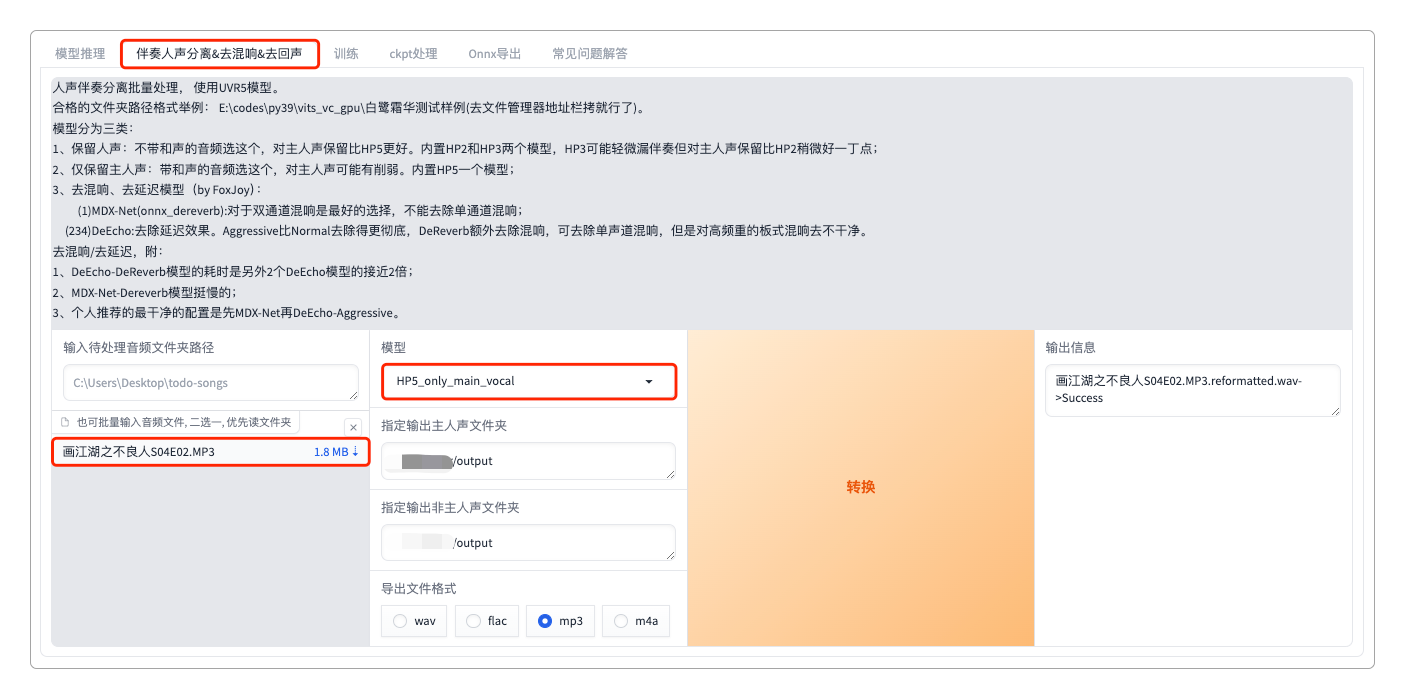
人声分离后的效果。
剪辑工具
之前在文生音频中提到过剪映有声音克隆的功能,这个也算是一种声音工具吧。
只需要录制10秒钟,就能生成自己专属的语音包(例句是随机生成的)。
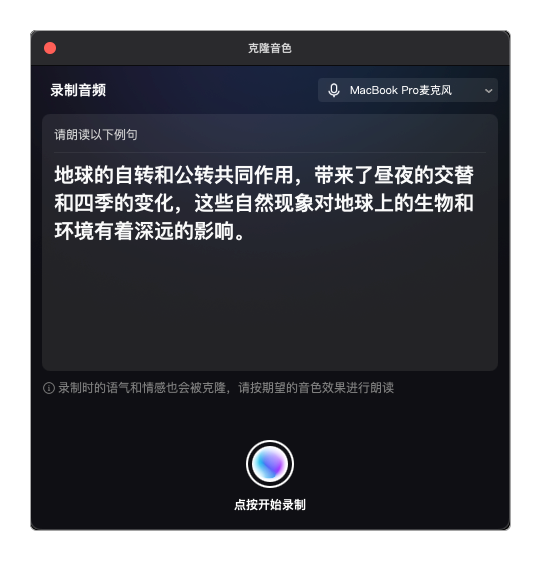
克隆出来的声音,不仅可以说中文,还能说英文。
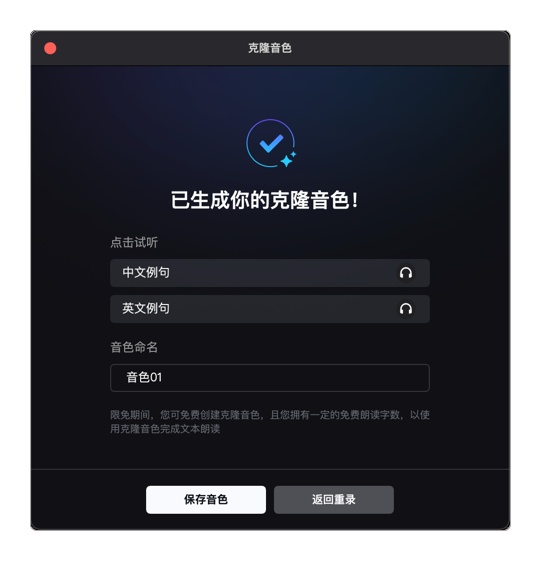
最后就可以用它来生成文本的朗读声音了。
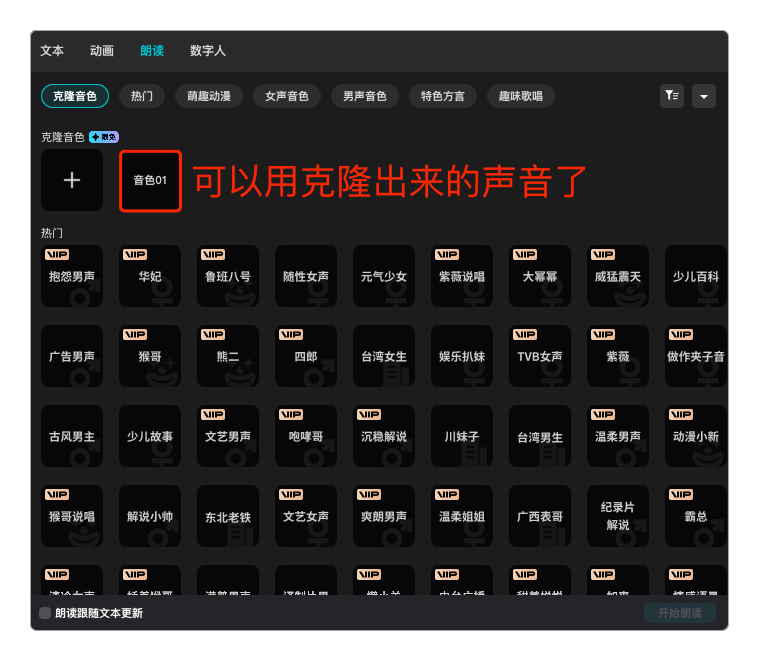
唯一遗憾的是不能实现变音效果。
感谢支持
更多内容,请移步《超级个体》。