
指标采样设计思路
动态时间片
类似近1小时内用户的登录次数多于3次这样的风控指标,本质上是一种风控关系表达式,它由左变量、关系运算符和右变量(或阈值)组成,如果把它用另外一种方式展现出来就是这样。
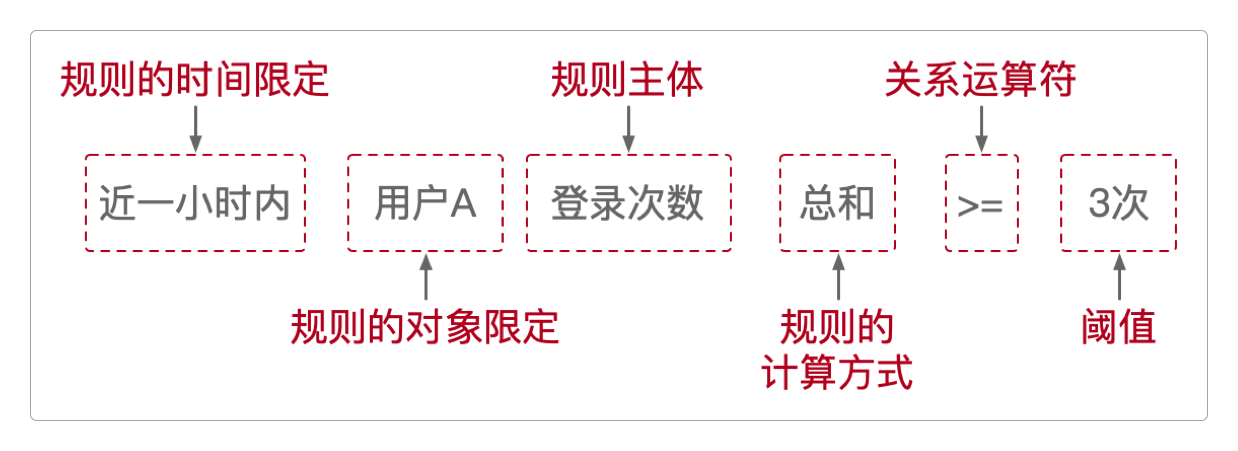
对于这种风控指标的计算来说,真正的难点不在于计算本身,而在于 如何快速且准确地取得指定时间片的数据。
因为很显然,条件中的近1小时内,它绝不是某个固定时间点开始后的1小时,而是从当前时间开始往回倒推的1小时。
也就是说,这个时间片是不断动态变化的:每过去1秒,往回推的时间片就要少计算1秒。
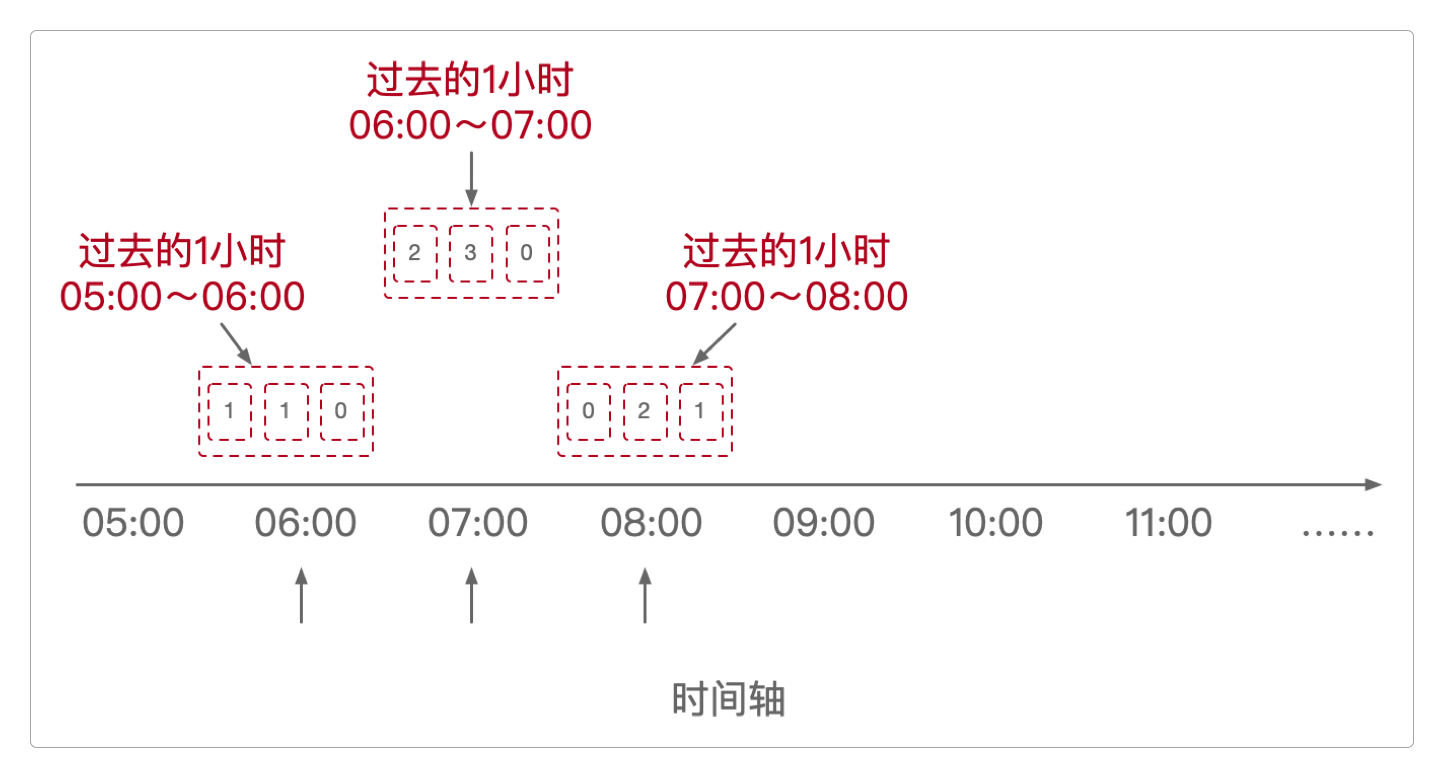
在
06:00时,近1小时指的是05:00 ~ 06:00。在
07:00时,近1小时指的是06:00 ~ 07:00。在
08:00时,近1小时指的是07:00 ~ 08:00。......
对于这种动态变化的时间片,难道针对每一个不同的时间片,都要采集该时间片内的全部数据重新计算一次吗?
要计算
2024-01-02 00:00:01一天内的登录数据,就把2024-01-01 00:00:01 ~ 2024-01-02 00:00:01时间片内的所有数据全都读取出来计算。要计算
2024-01-02 00:00:02一天内的登录数据,就把2024-01-01 00:00:02 ~ 2024-01-02 00:00:02时间片内的所有数据全都读取出来计算。
Flink在实时计算方面的性能虽然很高,但这种统计方式显然极其低效。
时间窗口机制
Flink中有四种从数据流中读取数据的窗口机制,分别是:滚动窗口、滑动窗口、会话窗口和全局窗口。
尤其是滚动窗口和滑动窗口,完全是为读取动态时间片中的数据而设计的机制。
假设Flink中保存有过去6分钟的登录数据序列。
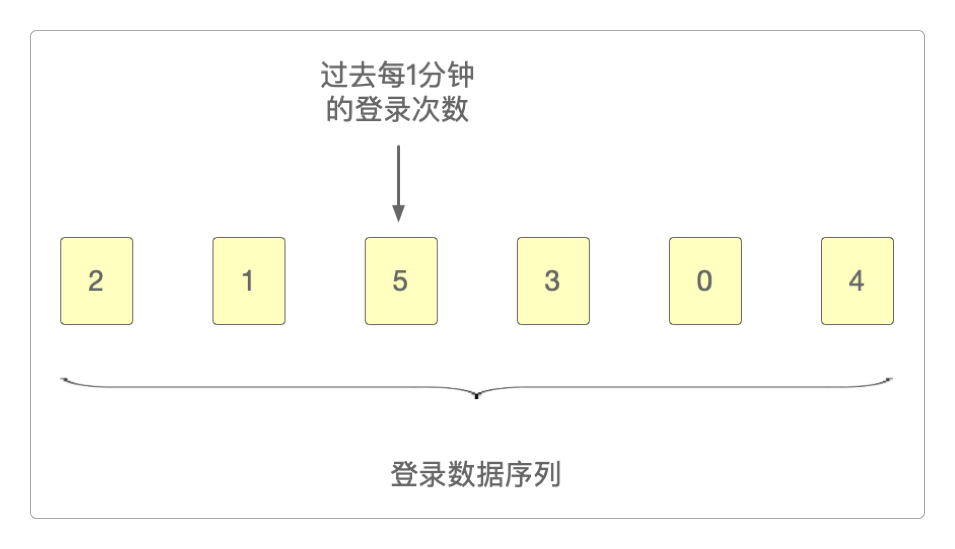
如果现在需要统计过去每2分钟内的登录数据,就可以仿效Flink的滑动窗口机制进行。
它可以是每1分钟统计一次。
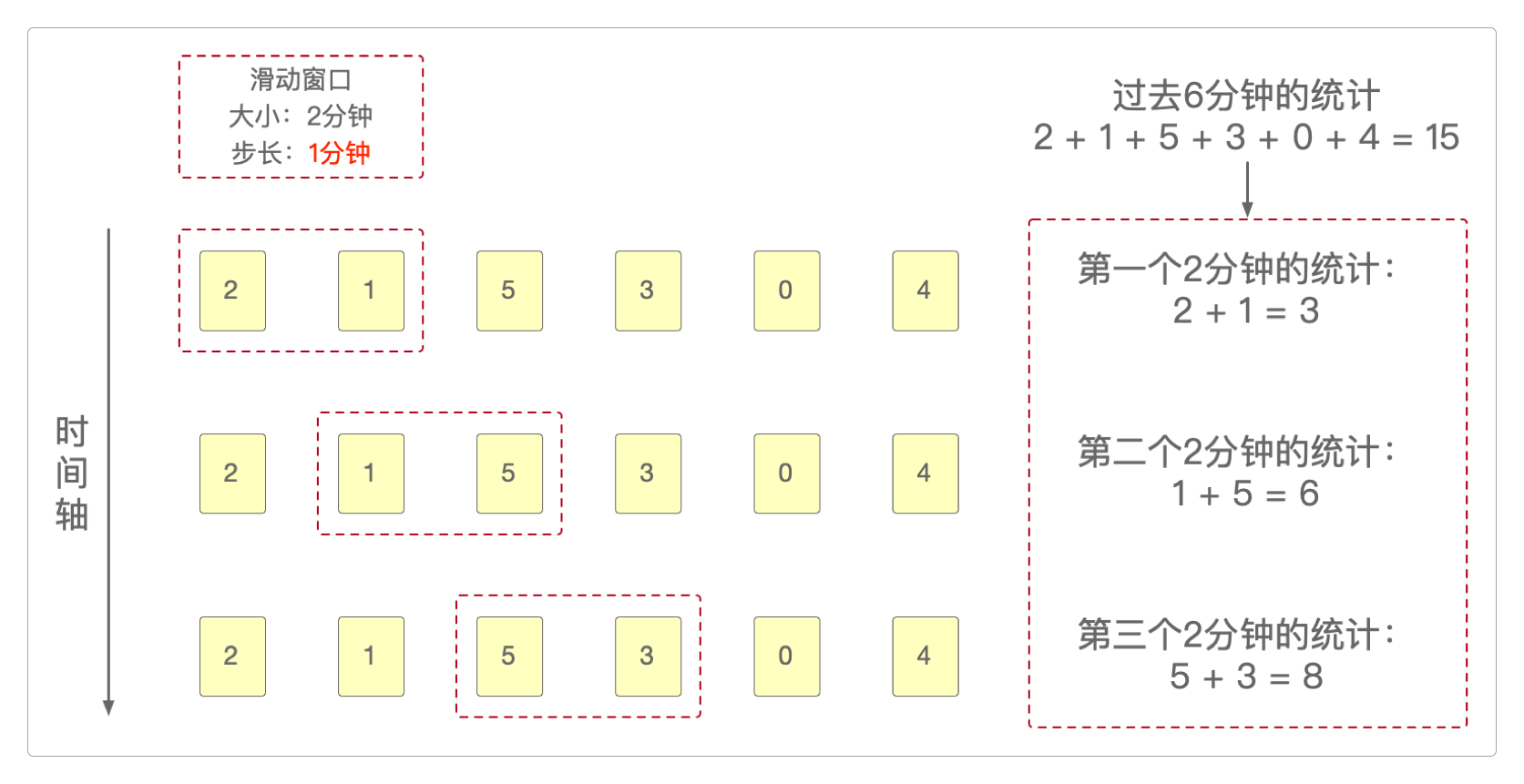
也可以是每2分钟统计一次。
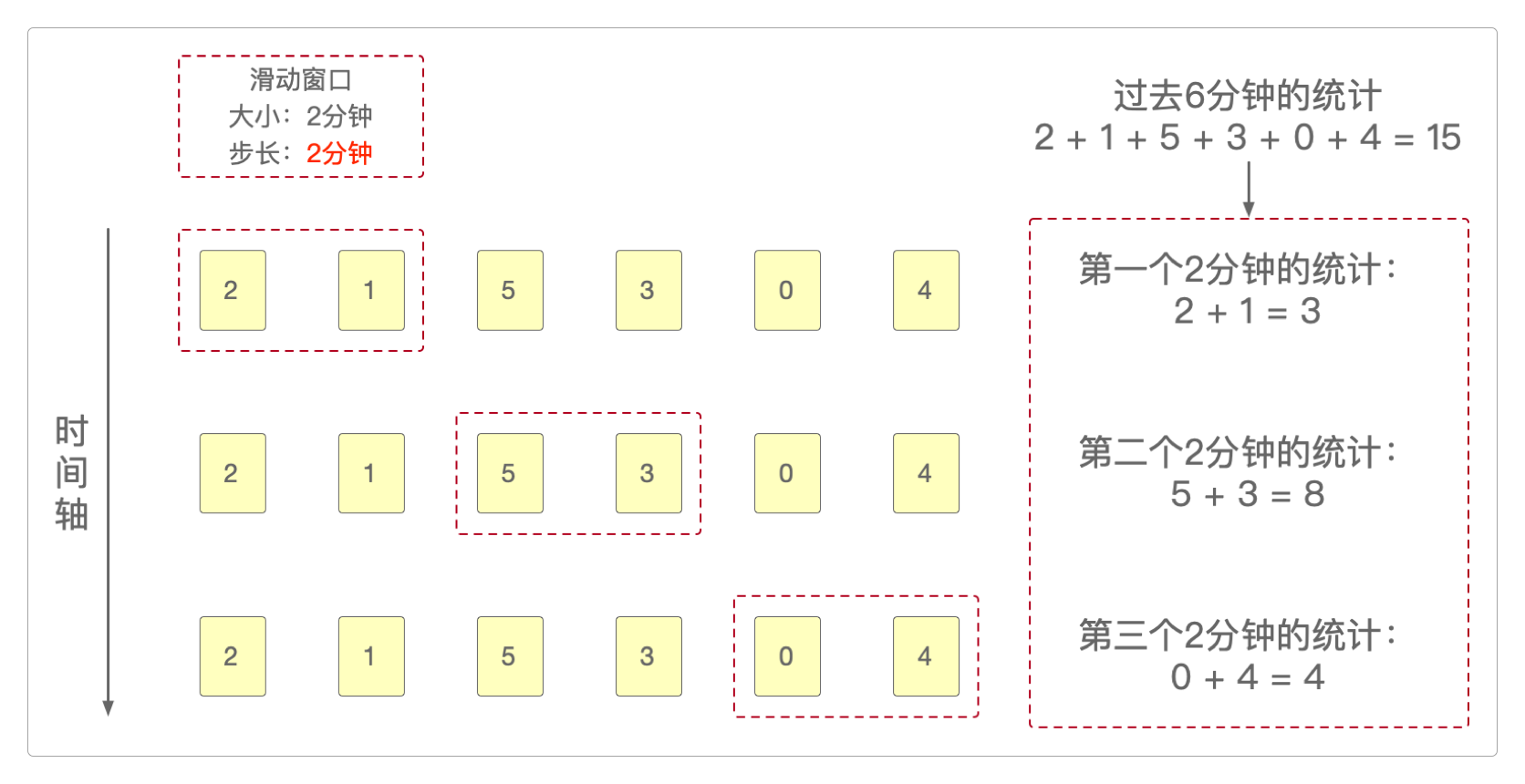
可以看到,统计结果依据窗口步长的不同而不同。
如果数据更多,统计粒度更大(例如,按小时或按天),其结果也是类似的。
这种用来存储风控数据的时间窗口,有一个专门的名称:指标采样窗口。
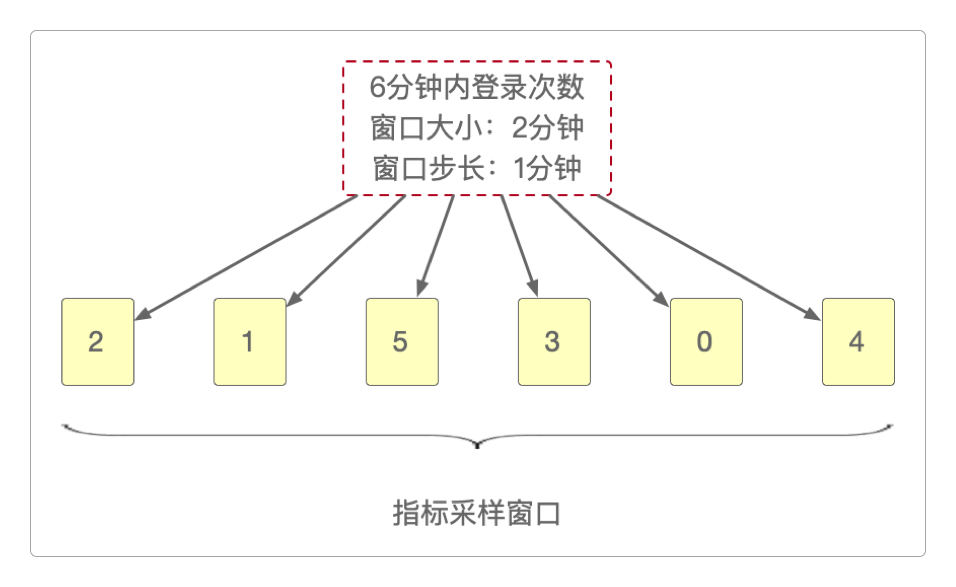
这种窗口的粒度可大可小:可以是分钟,可以是小时,也可以是天,完全根据业务需求而定。一般来说,最小粒度设为分钟已经足够了。
指标数据计算
有了解决动态时间片的时间窗口机制,那该怎样实现它呢?也就是对于任意时间片来说,该如何存储和查询这些数据,以便快速地执行风控指标计算呢?
存储指标采样
对于存储来说,Clickhouse会在后台不停地计算每个用户每分钟的登录次数,然后作为指标采样数据保存到Redis,这些数据相对于Flink来说是一种预聚合(或轻度聚合)数据,因为它为Flink提供了一些现成的可以直接拿来就用的结果集。
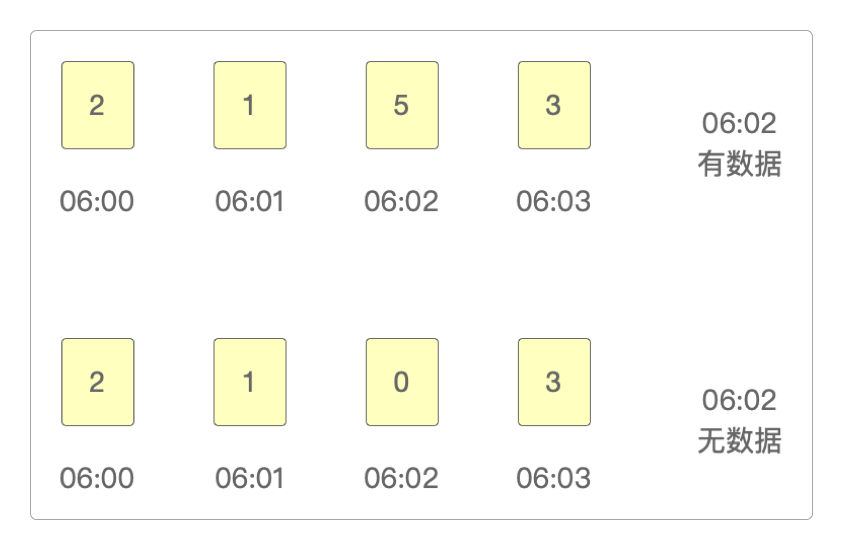
如果在
06:01 ~ 06:02之间有过登录,那么Clickhouse就会把统计出来的数据保存到06:02这个时间点上。如果在
06:01 ~ 06:02之间没有登录,那么06:02这个时间点上登录的次数就是0。
所以,在Redis中保存的登录数据序列有可能是这样的。
为什么用Redis保存数据呢?
Clickhouse会将时间点本身作为key的一部分保存到Redis,所以它的key是这样的。
# Redis Key = 指标ID:分组ID:指标维度:计算方式:时间戳
# 1 : 指标ID
# 0 : 分组ID,值可以是userid
# 5ml : 指标维度,5分钟内的登录次数,也可以是3分钟内的登录次数或别的指标
# sum : 计算方式为求和,也可以是其他方式
# 1704060060000 : 2024-01-01 06:01:00的时间戳,单位毫秒
# 300 : 过期时间300秒
> SETEX 1:0:1ml:sum:1704060060000 300 5通过这种key的组合方式,就把每1分钟内对应的登录数据保存到了Redis。
而且由于存在数据过期机制,Redis中的数据也会随着时间片一同更新。
读取指标采样
假设当前时间是早上10:00,需要获取账号最近5分钟内,也就是09:55 ~ 10:00之间的登录次数,数据如下。

这时候,会发现最接近的10:00时间也只有09:52那一时间点的采样数据,而这个时间点并没有≥ 09:55,所以得到最近5分钟内的登录次数为0——这是一种情况。
第二种情况是在09:55 ~ 10:00之间有登录数据。
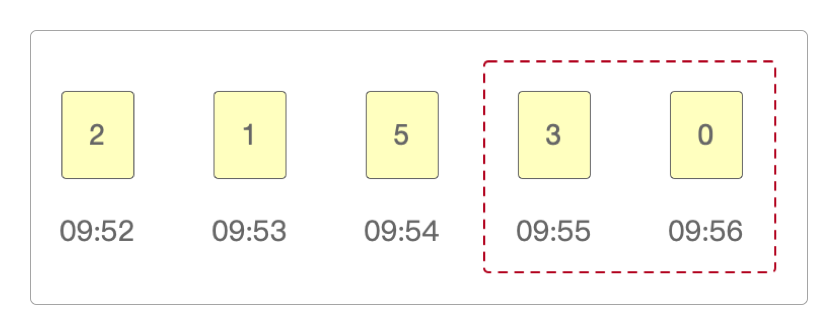
可以看到,有2条数据的存储时间点是≥ 09:55的。
所以,按照Rediskey的生成机制,可以这样读取它们的值。
# 读取2024-01-01 09:55:00的数据
> GET 1:0:1ml:sum:1704074100000
3
# 读取2024-01-01 09:56:00的数据
> GET 1:0:1ml:sum:1704074160000
0至于如何通过时间计算函数来判断和读取Redis中的数据,就完全是Java的事了。
另外,使用Clickhouse将数据保存到Redis时,是用String、List还是HSet,完全可以视情况而定。
感谢支持
更多内容,请移步《超级个体》。