
TumblingWindow滚动窗口
原创大约 16 分钟
窗口分类
在Flink中,窗口(Window)的作用是将无界流进行拆分,得到有限的数据集,使之变为有界流。
总的来说,Flink将窗口分为两大类。
基于时间驱动的
时间窗口。例如,不管有多少数据,都是每30秒钟创建一个窗口,然后在窗口中执行计算。基于数据驱动的
计数窗口。例如,不管多少时长,都是每10个元素创建一个窗口,然后在窗口中执行计算。
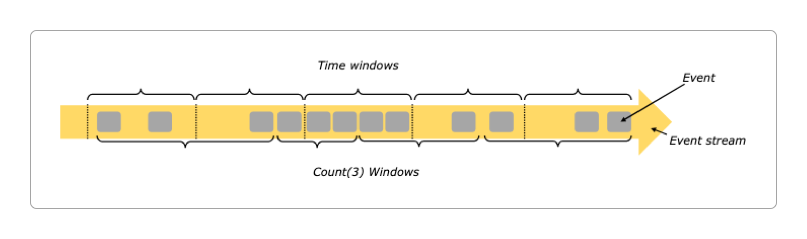
除了按照时间和数据的区分,每个大类按照窗口的工作机制,又分为滚动窗口、滑动窗口、会话窗口和全局窗口这四种。
所以,Flink总共有八种窗口:时间四种,计数四种。
不管是哪种类型的窗口,它们都会涉及到一些通用的概念和算子。
TumblingWindow(滚动窗口)
滚动窗口的大小是固定的,如果同一个计算任务由多个滚动窗口组成,那么这些窗口在时间区间上都是左闭右开的,它们不会重叠。

滚动窗口的代码模式如下。
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
// 滚动的 ProcessingTime 窗口
source
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// 滚动的 EventTime 窗口
source
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// 按天滚动 EventTime 窗口,偏移量为-8小时
source
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>);然后引入依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.1</version>
</dependency>ProcessingTime窗口
使用TumblingProcessingTimeWindowsJob()类实现单词统计,代码如下。
package itechthink.window.tumbling;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* TumblingProcessingTimeWindows 实现单词和最大值统计
* 输入数据格式:单词,次数
*
* window():用于处理流中的数据,区分流中的数据是属于哪个窗口
* 使用window()的方法可以在多个终端中输出结果,但只会在最开始启动的那个终端中输出
* 如果第一个终端关闭,那么会在第二个启动的终端输出,依此类推
* windowAll():用于处理所有数据,不区分流中的数据是属于哪个窗口
* 使用windowAll()的方法只会在一个终端中输出结果
*
*/
public class TumblingProcessingTimeWindowsJob {
private static final FastDateFormat DATE_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
// window(environment);
// windowAll(environment);
// windowReduce(environment);
windowProcess(environment);
// 5. 启动任务 - Execute
try {
environment.execute("TumblingProcessingTimeWindowsJob");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* window(),无偏移量
*
*/
public static void window(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
// 3. 处理数据 - Transform
source.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] split = input.split(",");
return Tuple2.of(split[0].trim(), Integer.parseInt(split[1].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
/*
* 方法可以在多个终端中输出结果,但只会在最开始启动的那个终端中输出
*
* 输入:
* a,1
* a,1
* a,1
* 输出结果:(a,3)
*
* 输入:
* a,1
* a,1
* 输出结果:(a,2)
*/
.sum(1)
// 4. 输出结果 - Sink
.print().setParallelism(1);
}
/**
* windowAll(),无偏移量
*
*/
public static void windowAll(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
// 3. 处理数据 - Transform
source.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] split = input.split(",");
return Tuple2.of(split[0].trim(), Integer.parseInt(split[1].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)))
/*
* 方法只会在某个终端中输出结果
*
* 输入:
* a,1
* a,1
* a,1
* 输出结果:(a,3)
*
* 输入:
* a,1
* a,1
* 输出结果:(a,2)
*/
.sum(1)
// 4. 输出结果 - Sink
.print().setParallelism(1);
}
/**
* window() + 自定义窗口函数ReduceFunction(),无偏移量
*/
public static void windowReduce(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
// 3. 处理数据 - Transform
source.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] split = input.split(",");
return Tuple2.of(split[0].trim(), Integer.parseInt(split[1].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
/*
* 方法可以在多个终端中输出结果,但只会在最开始启动的那个终端中输出
*
* 输入:
* a,1
* a,1
* a,1
* 输出结果:(a,3)
*
* 输入:
* a,1
* a,1
* 输出结果:(a,2)
*/
// 增量聚合方法
.reduce(
// 增量聚合函数
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
}
// // 后面可以接着自定义全量聚合函数
// /*
// * 全量聚合函数:全量统计的时间区间就是窗口的大小
// * Tuple2<String, Integer> IN 待处理的DataStreamSource中每个元素的类型
// * String OUT 结果DataStreamSource中每个元素的类型
// * String KEY keyBy()中指定的key的类型
// * TimeWindow TimeWindow
// */
// new ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
// @Override
// public void process(String input,
// Context context,
// Iterable<Tuple2<String, Integer>> iterable,
// Collector<String> collector) throws Exception {
// for (Tuple2<String, Integer> t : iterable) {
// // 查看Flink当前的Watermark时间,有几个key就算几次
// System.out.println("currentWatermark ==> " + DATE_FORMAT.format(context.currentWatermark()));
// collector.collect("[" + DATE_FORMAT.format(context.window().getStart()) +
// ", " + DATE_FORMAT.format(context.window().getEnd()) + ") " +
// t.f0 + " ==> " + t.f1);
// }
// }
// }
)
// 4. 输出结果 - Sink
.print().setParallelism(1);
}
/**
* window() + 自定义窗口函数ProcessWindowFunction(),无偏移量,统计最大值
*
*/
public static void windowProcess(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
// 3. 处理数据 - Transform
source.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
return Tuple2.of("process", Integer.parseInt(input.trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
/*
* 方法可以在多个终端中输出结果,但只会在最开始启动的那个终端中输出
*
* 输入:
* 2
* 4
* 7
* 1
* 9
* 2
* 10
* 输出结果:
* currentWatermark ==> 292269055-12-03 00:47:04
* [2024-03-28 19:26:40, 2024-03-28 19:26:45)
* ProcessWindowFunction ==> 10
*/
.process(
/*
* 全量聚合函数
* Tuple2<String, Integer> IN 待处理的DataStreamSource中每个元素的类型
* String OUT 结果DataStreamSource中每个元素的类型
*
* String KEY keyBy()中指定的key的类型
* TimeWindow TimeWindow
*/
new ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
@Override
public void process(String input,
ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>.Context context,
Iterable<Tuple2<String, Integer>> iterable,
Collector<String> collector) throws Exception {
int maxValue = 0;
for (Tuple2<String, Integer> element : iterable) {
maxValue = Math.max(maxValue, element.f1);
}
// 打印Flink的当前水印
System.out.println("currentWatermark ==> " + DATE_FORMAT.format(context.currentWatermark()));
collector.collect("[" + DATE_FORMAT.format(context.window().getStart()) + ", " + DATE_FORMAT.format(context.window().getEnd()) + ") ");
collector.collect("ProcessWindowFunction ==> " + maxValue);
}
}
)
// 4. 输出结果 - Sink
.print().setParallelism(1);
}
}这里面所有的方法都没有加偏移量,感兴趣的可以自己加一下试试。
EventTime窗口
使用TumblingEventTimeWindowsJob()类实现单词统计,代码如下。
package itechthink.window.tumbling;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.Date;
/**
* TumblingEventTimeWindows + Watermark 实现单词统计
* 输入数据格式:时间,单词,次数
* 使用了增量聚合函数 + 全量聚合函数组合的方式,可以把Flink的工作机制看得更清楚
*
*/
public class TumblingEventTimeWindowsJob {
private static final FastDateFormat DATE_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
// simpleSum(environment);
// apply(environment);
// reduce(environment);
reduceOffset(environment);
// reduceWithDelayNoSide(environment);
// reduceWithDelayHaveSide(environment);
// 5. 启动任务 - Execute
try {
environment.execute("TumblingEventTimeWindowsJob");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 简单的sum()方法,统计每个单词出现的次数
*
*/
private static void simpleSum(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
environment.socketTextStream("localhost", 9528)
.filter(StringUtils::isNoneBlank)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
// 抽取时间戳字段
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(",")[0]);
}
})
)
// 3. 处理数据 - Transform
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] value = input.split(",");
return Tuple2.of(value[1], Integer.valueOf(value[2]));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 直接使用sum()函数统计,虽然抽取了时间戳,但没有任何用处
.sum(1)
// 4. 输出结果 - Sink
.print().setParallelism(1);
}
/**
* 自定义apply()方法,不允许数据延迟
*
*/
public static void apply(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
// 3. 处理数据 - Transform
source.filter(StringUtils::isNoneBlank)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
// 抽取时间戳字段
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(",")[0]);
}
})
)
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] value = input.split(",");
return Tuple2.of(value[1].trim(), Integer.valueOf(value[2].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 全量聚合方法
.apply(
// // 在全量聚合方法中使用增量聚合函数的方式已经被废弃
// // 增量聚合函数
// new ReduceFunction<Tuple2<String, Integer>>() {
// @Override
// public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
// System.out.println("ReduceFunction ==> " + t1.f0 + " ==> " + (t1.f1 + t2.f1));
// return Tuple2.of(t1.f0, t1.f1 + t2.f1);
// }
// },
/*
* 全量聚合函数
* Tuple2<String, Integer> IN 待处理的DataStreamSource中每个元素的类型
* String OUT 结果DataStreamSource中每个元素的类型
* String KEY keyBy()中指定的key的类型
* TimeWindow TimeWindow
*/
new WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
/*
* 输入:
* 1000,a,1
* 2000,a,1
* 3000,a,1
* 4000,a,1
* 5000,a,1 <--- 第一次窗口触发[0000, 5000) a ==> 4
* 6000,a,1
* 7000,a,1
* 8000,a,1
* 9000,a,1
* 10000,a,1 <--- 第二次窗口触发[5000, 10000) a ==> 5
* 11000,a,1
* 12000,a,1
* 13000,a,1
* 14000,a,1
* 15000,a,1 <--- 第三次窗口触发[10000, 15000) a ==> 5
* 16000,a,1
* 输出:
* 1970-01-01 08:00:00 1970-01-01 08:00:05 apply ==> a ==> 4
* 1970-01-01 08:00:05 1970-01-01 08:00:10 apply ==> a ==> 5
* 1970-01-01 08:00:10 1970-01-01 08:00:15 apply ==> a ==> 5
*/
@Override
public void apply(String input, TimeWindow timeWindow, Iterable<Tuple2<String, Integer>> iterable, Collector<String> collector) throws Exception {
int sum = 0;
for (Tuple2<String, Integer> tuple : iterable) {
sum += tuple.f1;
}
collector.collect(DATE_FORMAT.format(new Date(timeWindow.getStart())) + " " +
DATE_FORMAT.format(new Date(timeWindow.getEnd())) +
" apply ==> " + input + " ==> " + sum);
}
})
// 4. 输出结果 - Sink
.print().setParallelism(1);
}
/**
* 自定义reduce()方法,不允许数据延迟
*
*/
private static void reduce(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
SingleOutputStreamOperator<String> result = environment.socketTextStream("localhost", 9528)
.filter(StringUtils::isNoneBlank)
.assignTimestampsAndWatermarks(
/*
* Duration.ZERO:不允许数据延迟
*/
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
// 抽取时间戳字段
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(",")[0]);
}
})
)
// 3. 处理数据 - Transform
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] value = input.split(",");
return Tuple2.of(value[1].trim(), Integer.valueOf(value[2].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
// [0, 5), [5, 10), [10, 15)......依次类推
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
/*
* 输入:
* 1000,a,1
* 2000,a,1
* 3000,a,1
* 4000,a,1
* 5000,a,1
* 6000,a,1
* 7000,a,1
* 输出:
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3
* ReduceFunction ==> a ==> 4
* ReduceFunction ==> a ==> 5
* currentWatermark ==> 1970-01-01 08:00:04
* [1970-01-01 08:00:00, 1970-01-01 08:00:05) a ==> 5
*/
// 增量聚合方法
.reduce(
// 增量聚合函数
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
System.out.println("ReduceFunction ==> " + t1.f0 + " ==> " + (t1.f1 + t2.f1));
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
},
/*
* 全量聚合函数
* Tuple2<String, Integer> IN 待处理的DataStreamSource中每个元素的类型
* String OUT 结果DataStreamSource中每个元素的类型
* String KEY keyBy()中指定的key的类型
* TimeWindow TimeWindow
*/
new ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
@Override
public void process(String input,
Context context,
Iterable<Tuple2<String, Integer>> iterable,
Collector<String> collector) throws Exception {
for (Tuple2<String, Integer> t : iterable) {
// 查看Flink当前的Watermark时间,有几个key就算几次
System.out.println("currentWatermark ==> " + DATE_FORMAT.format(context.currentWatermark()));
collector.collect("[" + DATE_FORMAT.format(context.window().getStart()) +
", " + DATE_FORMAT.format(context.window().getEnd()) + ") " +
t.f0 + " ==> " + t.f1);
}
}
}
);
// 4. 输出结果 - Sink
result.print().setParallelism(1);
}
/**
* 自定义reduce()方法,偏移量1秒,不允许数据延迟
*
*/
private static void reduceOffset(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
SingleOutputStreamOperator<String> result = environment.socketTextStream("localhost", 9528)
.filter(StringUtils::isNoneBlank)
.assignTimestampsAndWatermarks(
/*
* Duration.ZERO:不允许数据延迟
*/
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
// 抽取时间戳字段
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(",")[0]);
}
})
)
// 3. 处理数据 - Transform
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] value = input.split(",");
return Tuple2.of(value[1].trim(), Integer.valueOf(value[2].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,偏移1秒
// [1, 6), [6, 11), [11, 16)......依次类推
.window(TumblingEventTimeWindows.of(Time.seconds(5), Time.seconds(1)))
/*
* 输入:
* 1000,a,1
* 2000,a,1
* 3000,a,1
* 4000,a,1
* 5000,a,1
* 6000,a,1
* 7000,a,1
* 输出:
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3
* ReduceFunction ==> a ==> 4
* ReduceFunction ==> a ==> 5 <--- 这里执行的是增量函数ReduceFunction()的求和,计算的是[1000, 6000)窗口内的数据
* ReduceFunction ==> a ==> 2
* currentWatermark ==> 1970-01-01 08:00:06
* [1970-01-01 08:00:01, 1970-01-01 08:00:06) a ==> 5 <--- 这里执行的是全量函数ProcessWindowFunction()的求和,在“6000”时间点到来时触发,计算的是[1000, 6000)窗口内的数据
*/
// 增量聚合方法
.reduce(
// 增量聚合函数
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
System.out.println("ReduceFunction ==> " + t1.f0 + " ==> " + (t1.f1 + t2.f1));
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
},
/*
* 全量聚合函数
* Tuple2<String, Integer> IN 待处理的DataStreamSource中每个元素的类型
* String OUT 结果DataStreamSource中每个元素的类型
* String KEY keyBy()中指定的key的类型
* TimeWindow TimeWindow
*/
new ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
@Override
public void process(String input,
Context context,
Iterable<Tuple2<String, Integer>> iterable,
Collector<String> collector) throws Exception {
for (Tuple2<String, Integer> t : iterable) {
// 查看Flink当前的Watermark时间,有几个key就算几次
System.out.println("currentWatermark ==> " + format.format(context.currentWatermark()));
collector.collect("[" + format.format(context.window().getStart()) +
", " + format.format(context.window().getEnd()) + ") " +
t.f0 + " ==> " + t.f1);
}
}
}
);
// 4. 输出结果 - Sink
result.print().setParallelism(1);
}
/**
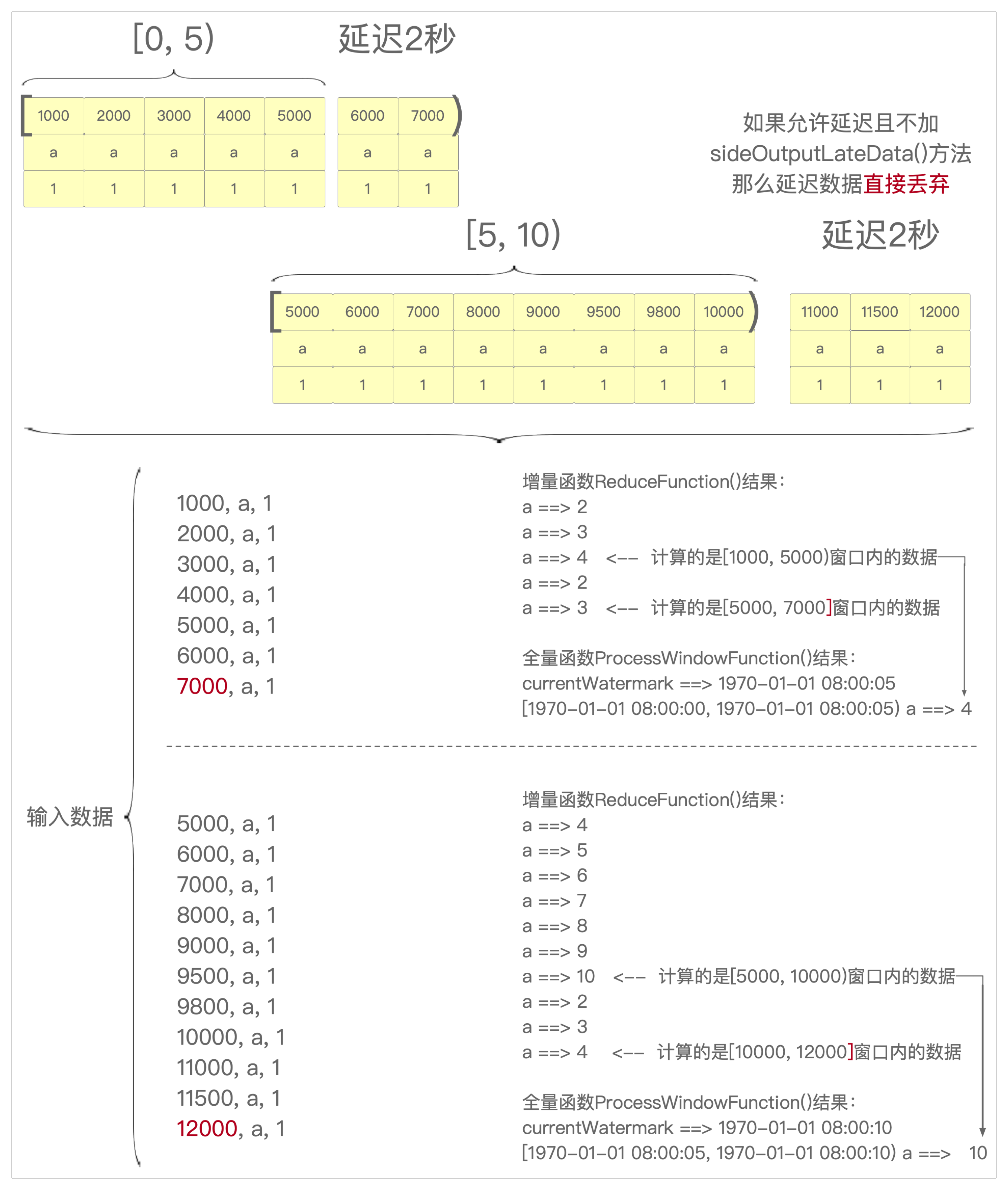
* 自定义reduce()方法,允许数据延迟且不带sideOutputLateData(outputTag)旁路输出
*
*/
private static void reduceWithDelayNoSide(StreamExecutionEnvironment environment) {
// 2. 读取数据 - Source
SingleOutputStreamOperator<String> result = environment.socketTextStream("localhost", 9528)
.filter(StringUtils::isNoneBlank)
.assignTimestampsAndWatermarks(
/*
* Time.seconds(2):允许数据延迟2秒
*/
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
// 抽取时间戳字段
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(",")[0]);
}
})
)
// 3. 处理数据 - Transform
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] value = input.split(",");
return Tuple2.of(value[1].trim(), Integer.valueOf(value[2].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
// [0, 5+2), [5, 10+2), [10, 15+2)......依次类推
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
/*
* 输入:
* 1000,a,1
* 2000,a,1
* 3000,a,1
* 4000,a,1
* 5000,a,1
* 6000,a,1
* 7000,a,1
* 输出:
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3
* ReduceFunction ==> a ==> 4 <--- 这里执行的是增量函数ReduceFunction()的求和,计算的是[1000, 5000)窗口内的数据
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3 <--- 这里执行的也是增量函数ReduceFunction()的求和,计算的是[5000, 7000]窗口内的数据
* currentWatermark ==> 1970-01-01 08:00:05
* [1970-01-01 08:00:00, 1970-01-01 08:00:05) a ==> 4 <--- 这里执行的是全量函数ProcessWindowFunction()的求和,在“7000”时间点到来时触发,计算的是[1000, 5000)窗口内的数据
*
* 输入:
* 5000,a,1
* 6000,a,1
* 7000,a,1
* 8000,a,1
* 9000,a,1
* 9500,a,1
* 9800,a,1
* 10000,a,1
* 11000,a,1
* 11500,a,1
* 12000,a,1
* 输出:
* ReduceFunction ==> a ==> 4
* ReduceFunction ==> a ==> 5
* ReduceFunction ==> a ==> 6
* ReduceFunction ==> a ==> 7
* ReduceFunction ==> a ==> 8
* ReduceFunction ==> a ==> 9
* ReduceFunction ==> a ==> 10 <--- 这里执行的是增量函数ReduceFunction()的求和,计算的是[5000, 10000)窗口内的数据
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3
* ReduceFunction ==> a ==> 4 <--- 这里执行的是增量函数ReduceFunction()的求和,计算的是[10000, 12000]窗口内的数据
* currentWatermark ==> 1970-01-01 08:00:10
* [1970-01-01 08:00:05, 1970-01-01 08:00:10) a ==> 10 <--- 这里执行的是全量函数ProcessWindowFunction()的求和,在“7000”时间点到来时触发,计算的是[5000, 10000)窗口内的数据
*
* 所以从结果来看,增量函数和全量函数的表现不同
* 1. 增量聚合函数:既处理当前窗口内的数据,也处理下一个窗口的数据
* 2. 全量聚合函数:只处理当前窗口内的数据
*/
// 增量聚合函数
.reduce(
// 增量聚合函数
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
System.out.println("ReduceFunction ==> " + t1.f0 + " ==> " + (t1.f1 + t2.f1));
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
},
/*
* 全量聚合函数
* Tuple2<String, Integer> IN 待处理的DataStreamSource中每个元素的类型
* String OUT 结果DataStreamSource中每个元素的类型
* String KEY keyBy()中指定的key的类型
* TimeWindow TimeWindow
*/
new ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
@Override
public void process(String input,
Context context,
Iterable<Tuple2<String, Integer>> iterable,
Collector<String> collector) throws Exception {
for (Tuple2<String, Integer> t : iterable) {
// 查看Flink当前的Watermark时间
System.out.println("currentWatermark ==> " + DATE_FORMAT.format(context.currentWatermark()));
collector.collect("[" + DATE_FORMAT.format(context.window().getStart()) +
", " + DATE_FORMAT.format(context.window().getEnd()) + ") " +
t.f0 + " ==> " + t.f1);
}
}
}
);
// 4. 输出结果 - Sink
result.print().setParallelism(1);
}
/**
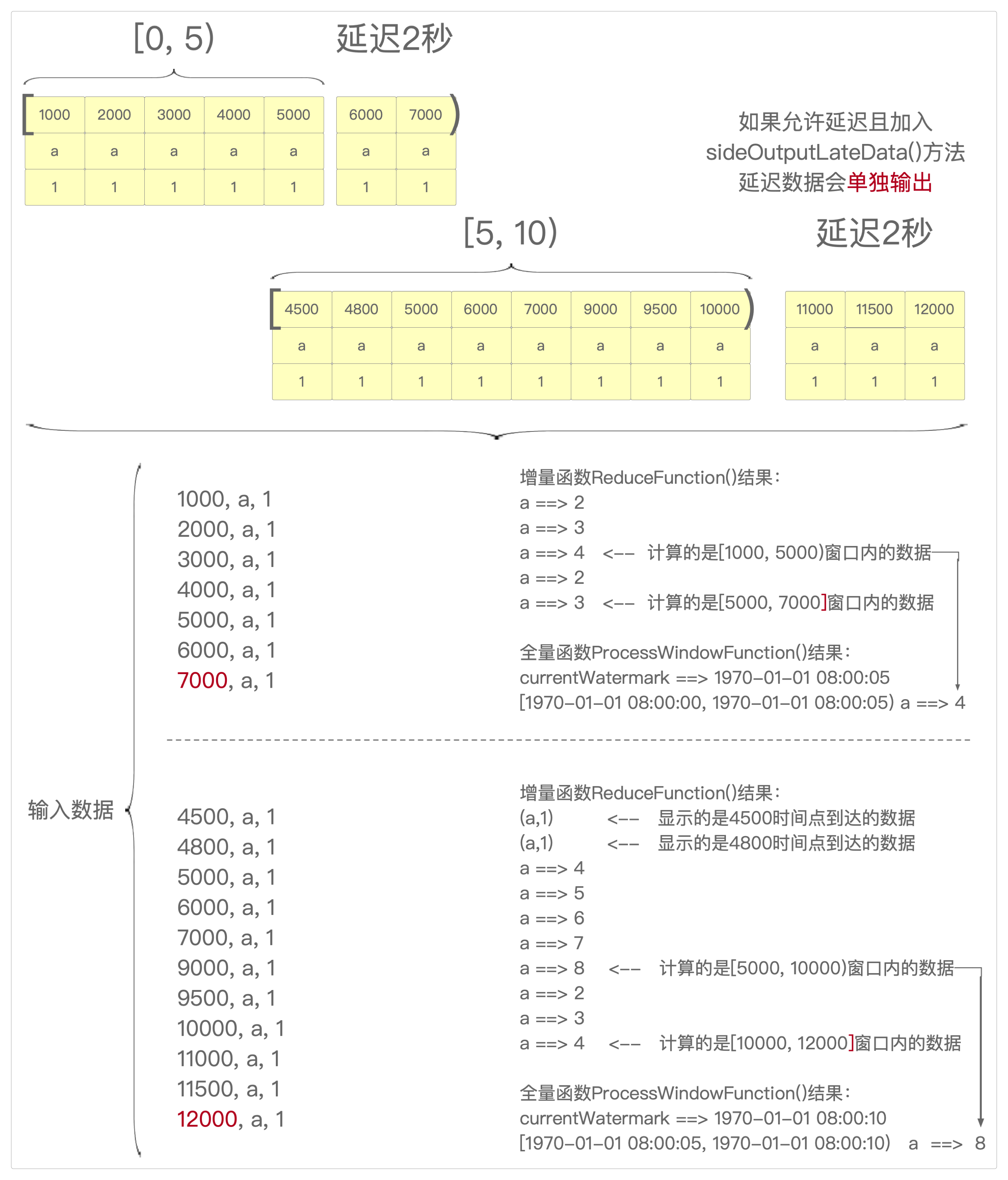
* 自定义reduce()方法,允许数据延迟且带有sideOutputLateData(outputTag)旁路输出
*
*/
private static void reduceWithDelayHaveSide(StreamExecutionEnvironment environment) {
// 延迟数据处理
OutputTag<Tuple2<String, Integer>> outputTag = new OutputTag<Tuple2<String, Integer>>("late-data") {};
// 2. 读取数据 - Source
SingleOutputStreamOperator<String> result = environment.socketTextStream("localhost", 9528)
.filter(StringUtils::isNoneBlank)
.assignTimestampsAndWatermarks(
/*
* Time.seconds(2):允许数据延迟2秒
*/
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<String>() {
// 抽取时间戳字段
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(",")[0]);
}
})
)
// 3. 处理数据 - Transform
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String input) throws Exception {
String[] value = input.split(",");
return Tuple2.of(value[1].trim(), Integer.valueOf(value[2].trim()));
}
})
// 按key分组
.keyBy(x -> x.f0)
// 窗口大小:5秒,无偏移量
// [0, 5+2), [5, 10+2), [10, 15+2)......依次类推
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 延迟数据旁路输出
.sideOutputLateData(outputTag)
/*
* 输入:
* 1000,a,1
* 2000,a,1
* 3000,a,1
* 4000,a,1 <--- 第一次全量触发仅计算到这里
* 5000,a,1
* 6000,a,1
* 7000,a,1 <--- 因为延迟2秒,所以在这里触发全量计算函数ProcessWindowFunction()
* 输出:
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3
* ReduceFunction ==> a ==> 4
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3
* currentWatermark ==> 1970-01-01 08:00:04
* [1970-01-01 08:00:00, 1970-01-01 08:00:05) a ==> 4
* 生成结果的原理同前一个方法
*
* 输入:
* 4500, a, 1
* 4800, a, 1
* 5000, a, 1
* 6000, a, 1
* 7000, a, 1
* 9000, a, 1
* 9500, a, 1
* 10000, a, 1
* 11000, a, 1
* 11500, a, 1
* 12000, a, 1
* 输出:
* (a,1)
* (a,1)
* ReduceFunction ==> a ==> 4
* ReduceFunction ==> a ==> 5
* ReduceFunction ==> a ==> 6
* ReduceFunction ==> a ==> 7
* ReduceFunction ==> a ==> 8
* ReduceFunction ==> a ==> 2
* ReduceFunction ==> a ==> 3
* ReduceFunction ==> a ==> 4
* currentWatermark ==> 1970-01-01 08:00:09
* [1970-01-01 08:00:05, 1970-01-01 08:00:10) a ==> 8
* 生成结果的原理同前一个方法
*
* 所以从结果来看,增量函数和全量函数的表现不同
* 1. 增量聚合函数:既处理当前窗口内的数据,也处理下一个窗口的数据
* 2. 全量聚合函数:只处理当前窗口内的数据,既不管下一个窗口,也不管迟到的数据
*/
// 增量聚合方法
.reduce(
// 增量聚合函数
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
System.out.println("ReduceFunction ==> " + t1.f0 + " ==> " + (t1.f1 + t2.f1));
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
},
/*
* 全量聚合函数
* Tuple2<String, Integer> IN 待处理的DataStreamSource中每个元素的类型
* String OUT 结果DataStreamSource中每个元素的类型
* String KEY keyBy()中指定的key的类型
* TimeWindow TimeWindow
*/
new ProcessWindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {
@Override
public void process(String input,
Context context,
Iterable<Tuple2<String, Integer>> iterable,
Collector<String> collector) throws Exception {
for (Tuple2<String, Integer> t : iterable) {
// 查看Flink当前的Watermark时间
// 有几个key就算几次
System.out.println("currentWatermark ==> " + DATE_FORMAT.format(context.currentWatermark()));
collector.collect("[" + DATE_FORMAT.format(context.window().getStart()) +
", " + DATE_FORMAT.format(context.window().getEnd()) + ") " +
t.f0 + " ==> " + t.f1);
}
}
}
);
// 4. 输出结果 - Sink
result.print().setParallelism(1);
// 拿到延迟的数据 OutputTag<Tuple2<String, Integer>>
DataStream<Tuple2<String, Integer>> sideOutput = result.getSideOutput(outputTag);
// 以不同的颜色观察延迟数据输出
sideOutput.printToErr();
}
}reduce()、reduceWithDelayNoSide()和reduceWithDelayHaveSide()这三个方法的执行过程可以用三张图来表示。
- reduce()执行过程

- reduceWithDelayNoSide()执行过程
- reduceWithDelayHaveSide()执行过程
感谢支持
更多内容,请移步《超级个体》。