
数据存储:行式与列式
行式存储
之前在HBase中对于行式存储与列式存储的区别并没有讲的很清楚,这里把它们彻底搞清楚。
还是之前那张前台登记表。
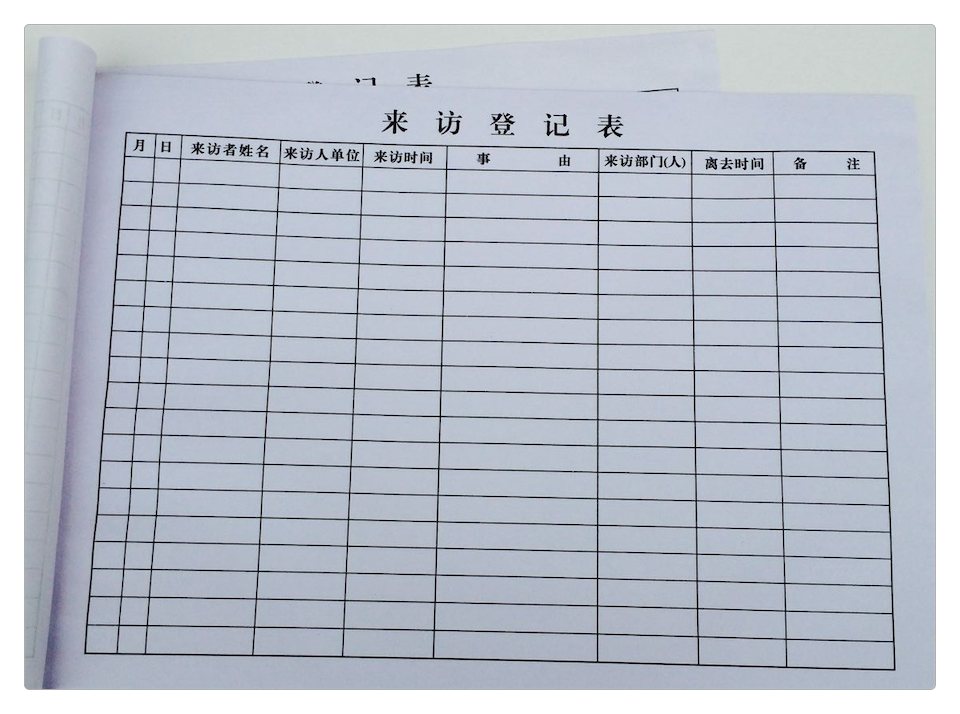
来访登记表的数据记录方式非常符合人的阅读和记忆习惯:从上到下,从左到右。
而且每一行数据的不同列之间,也是有明显的关联关系的:单位、联系方式都必定从属于某个来访者。
大多数的计算机数据库系统也是这么存储数据的,例如Oracle、SQL Server和MySQL,因此这类用“行”的方式来存储数据,且每一行的数据之间有关联关系的数据库系统,又叫关系型数据库(Relational Database Management System,RDBMS)系统。
在计算机技术发展的早期,这种方式运行的很好。但在网络时代,就暴露出了一个很严重的问题:不够灵活,且性能太拉胯了。
以存储商品数据的表格为例。
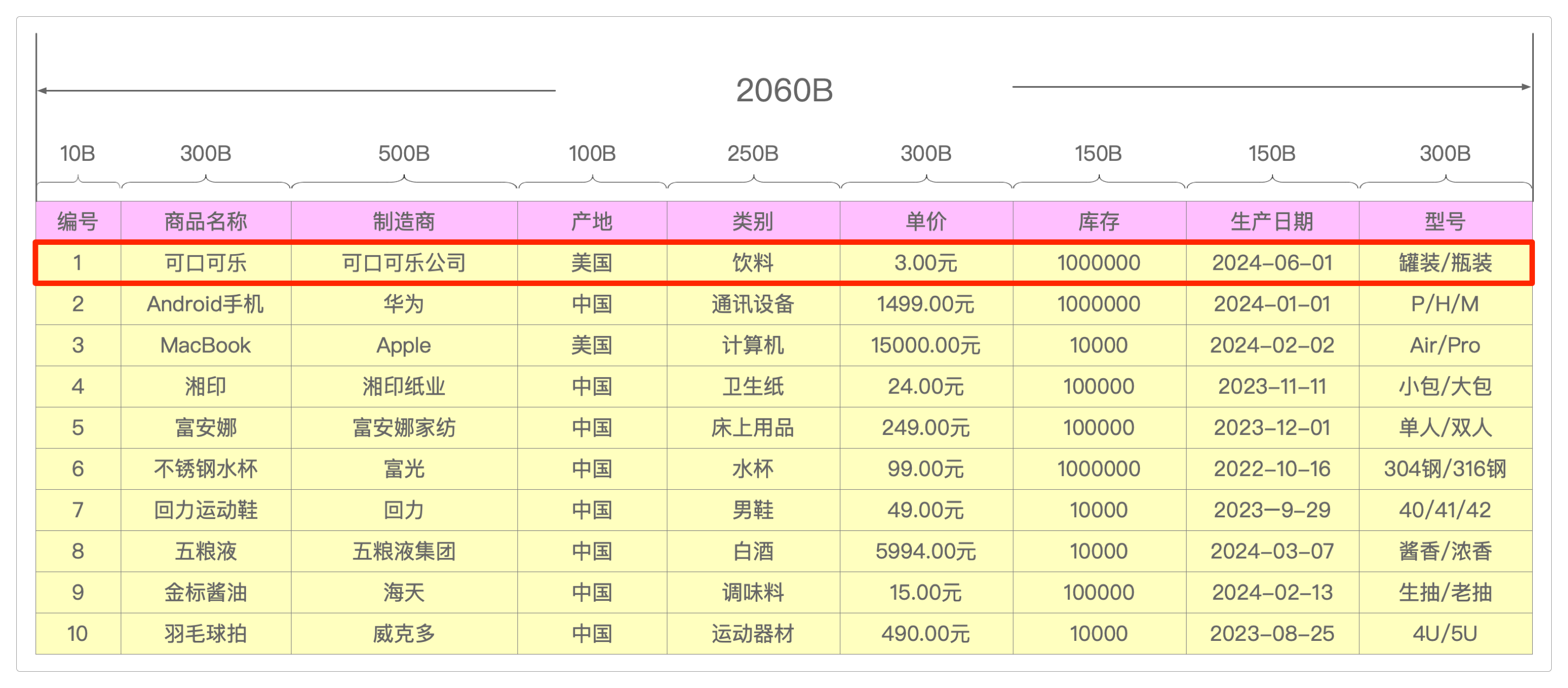
每一列能够存储的数据量是固定的:假设编号数据会占用
10B(B是Byte的缩写,表示字节,10B表示10个字节)、商品名称会占用300B,这样合计下来,一条完整的商品信息将占用2060B,也就是2KB多一点。对于
行式存储来说,任何一行数据都是不可分割的,也就是说,如果它需要读取一条商品信息,例如可口可乐,要么把它所有的属性列全部取出来,要么一个属性列都不取(有点像捆绑销售)。这就产生了一个问题:哪怕仅仅只想看看价格,也不得不把其他不相干的数据列也拿出来。这是因为计算机没有
眼睛,它无法像人一样看到并取出数据,它只能依靠蛮力查找——也就是纯粹的计算,而且它的内存分配方式也不允许它只拿部分。所以,当要读取商品名称和价格时,为了这
600B的数据,就不得不把剩下的1460B也拿出来。这就好比某人去旅行时本来只用带衣服,却不得不把整个衣柜都打包带上一样,简直要命——这种效率可想而知——事实上,当前的互联网应用中的所有用于OLAP的行式存储数据库都是这么干的。
列式存储
既然行的方式不行,那换一种思路呢?于是,有人就提出了另外一种存储和读取数据的方式:把行转成列。
这样一来,按照计算机的读取方式,就不用再费力去打包很多无关的内容了。
现在仅仅只需要将商品名称和价格所在的行(也就是原来的列)拿出来就行了。
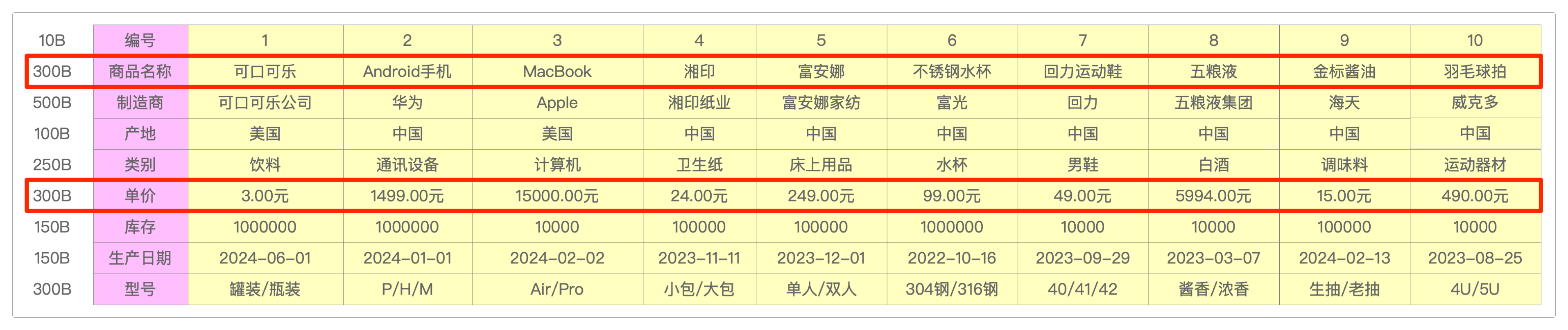
这种方式,人类看起来很不习惯,但是却非常适合计算机处理——再也不需要去读那些无关的数据了。
用更符合人类阅读的习惯来看,就是下面这样。
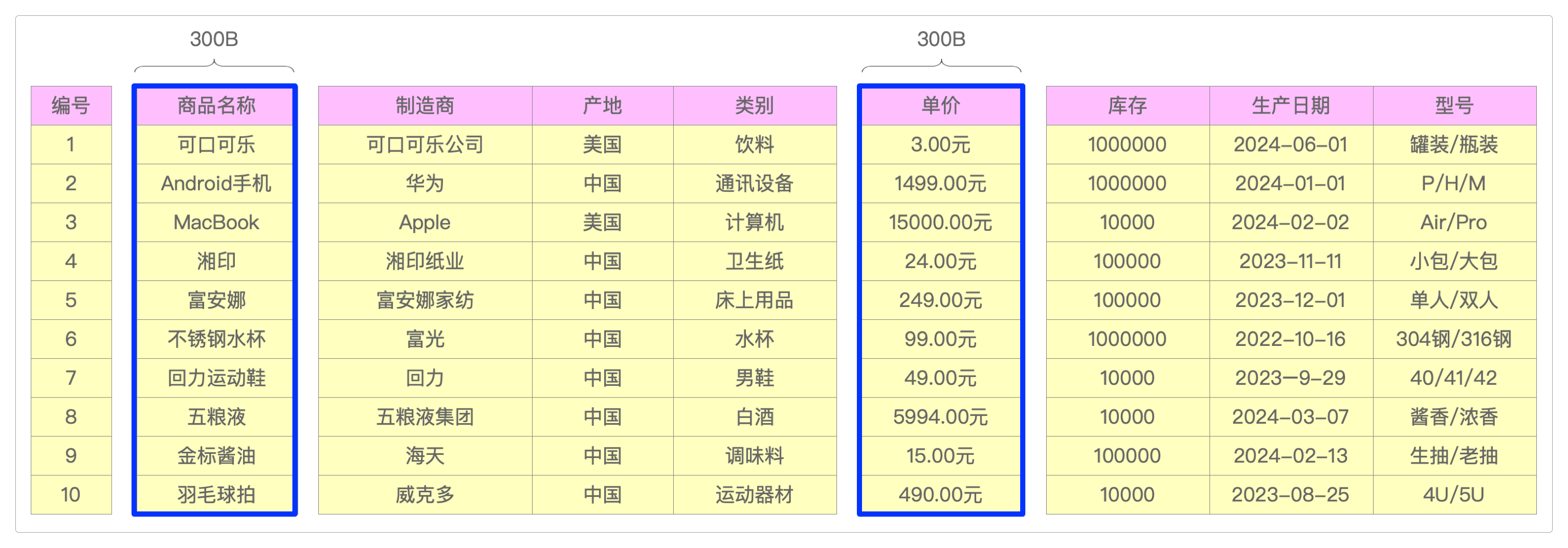
而且,当使用列式存储时,因为列中都是同一类数据,所以也可以更好地进行“压缩”。
例如,如果要压缩产地数据,那么在计算机内部,完全可以用1代表中国,用2代表美国——用数字来表示数据,可比用文字省空间多了,而且传输也更快。

这样一来,既少了很多包袱,且每样用品还能压缩——这就是为什么列式存储数据库的性能普遍都比较高的根本原因。
上面这些图只是用于表述和方便理解,计算机中真正的存储结构可不是这样的。
Clickhouse正是这样一款基于列式存储的大数据系统。
现在,通过列式存储,计算机再也不用每次查询时把数据的全家都搜罗出来了。
下面是Clickhouse官方对行式存储和列式存储的比较。
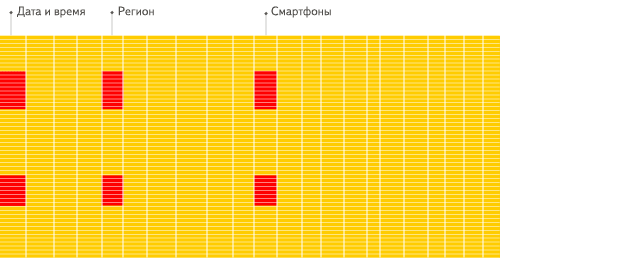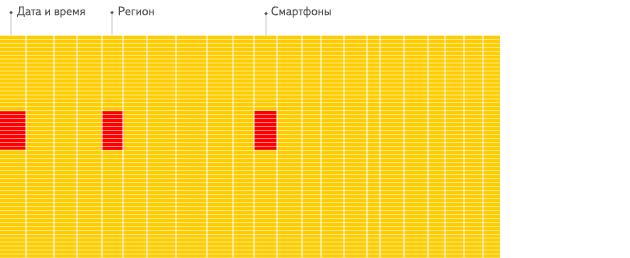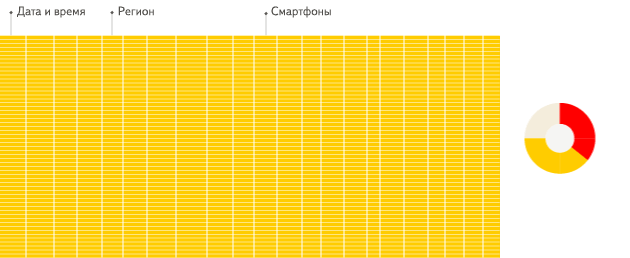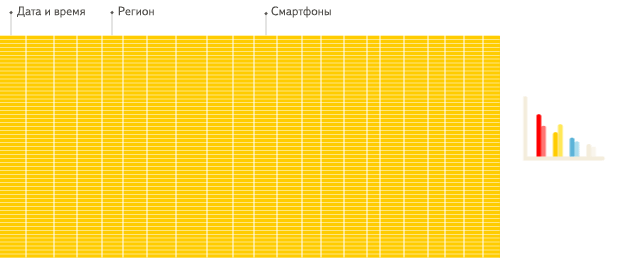
适用场景
列式存储尽管读取性能更好,但它并不是用来取代行式存储的,而是一种更好的补充,它们有各自适用的场景。
行式存储更适用于插入和更新,它适用于OLTP(On-Line Transaction Processing,联机事务处理)型业务。列式存储更适用于读取和分析,它适用于OLAP(On-Line Analysis Processing,联机分析处理)型业务。
从名字就能看出来,它们一个适合做日常事务数据的管理操作,而另一个适合做海量数据分析操作。
关注公众号后回复 ck 即可获得Clickhouse栏目剩余文章的访问密码。
