
分区、分片与副本
概念
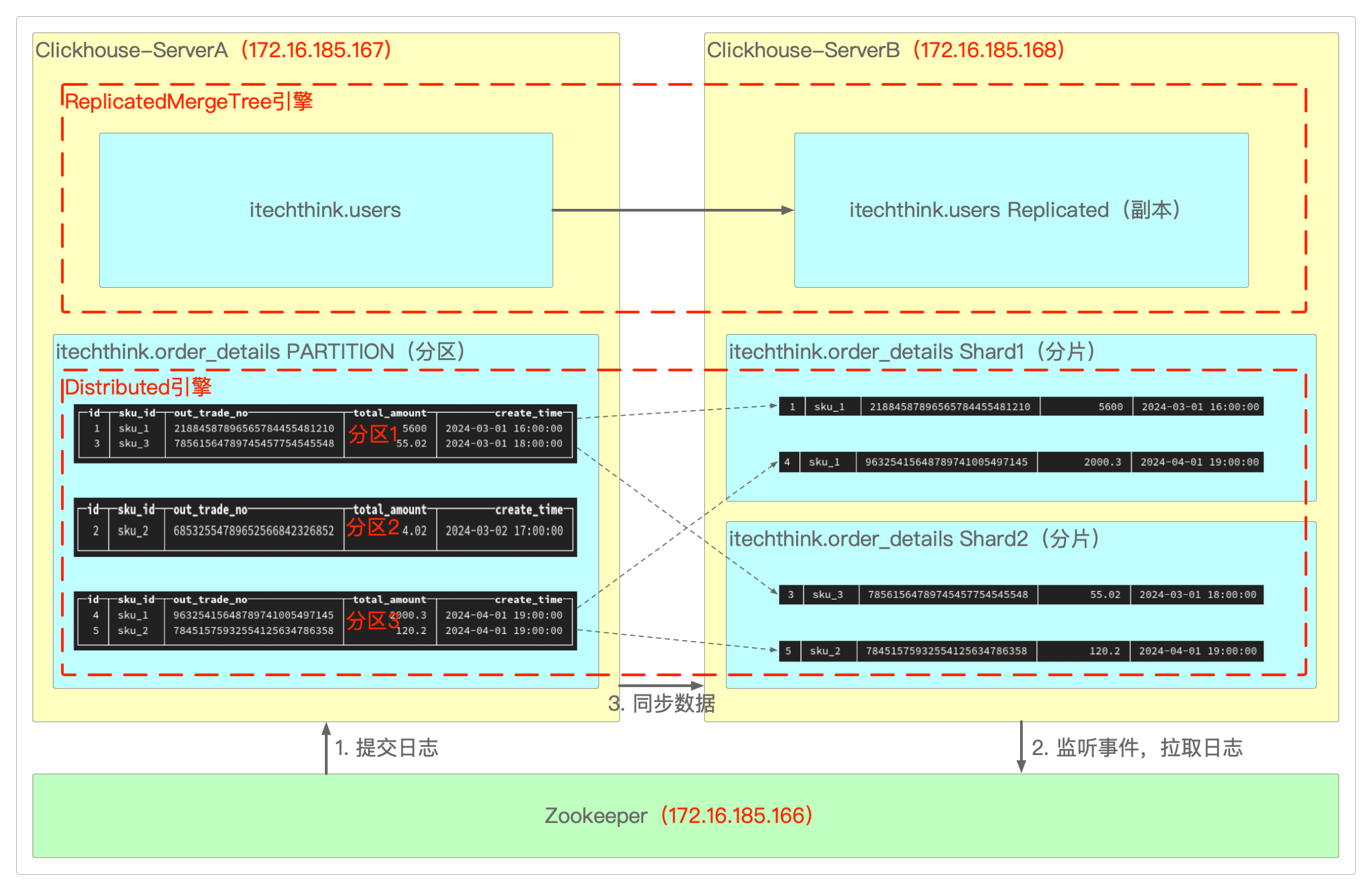
分区
分区是针对表而言的,Clickhouse可以把一张表拆分成多个区块,这类似于MySQL的水平分表。
分区后的表还是一张表,数据处理还是由自己来完成。
建表时加入partition关键字,允许查询在指定分区键的条件下,尽可能的少读取数据,提升性能。
不是所有的表引擎都可以分区,MergeTree系列引擎才支持数据分区,而Log系列引擎不支持。
:) CREATE TABLE order_details
(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(create_time)
ORDER BY (id, sku_id)
PRIMARY KEY (id);分片
分片是把数据库横向扩展到多个物理节点上,相当于在分区之上又做了一次分区。
分片可以将同一个分区中的多条数据分不到不同节点上,再通过Distributed引擎把数据拼接起来使用。
分片使得Clickhouse可以横向线性拓展,构建大规模分布式集群,但需要避免数据倾斜问题。
副本
为了数据备份与安全,保障数据的高可用性,Clickhouse的某个节点将同一张表的数据复制并同步到另一个节点上。
这样,即使其中一台Clickhouse宕机,那么也可以从另外一台服务器获取数据——这类似于MySQL的主从结构。
环境准备
机器一:Docker安ZooKeeper(172.16.185.166)
机器二: rpm安装Clickhouse(172.16.185.167)
机器三: rpm安装Clickhouse(172.16.185.168)
下载官方提供的RPM安装包,主要是下面这几个。
clickhouse-client。clickhouse-common-static。clickhouse-common-static-dbg。clickhouse-serve。clickhouse-keeper、clickhouse-keeper-dbg、clickhouse-library-bridge和clickhouse-odbc-bridge可不装。
先在172.16.185.166上安装ZooKeeper(也可以用clickhouse-keeper和clickhouse-keeper-dbg代替)。
> docker run -d --name zookeeper -p 2181:2181 zookeeper因为涉及到配置文件的修改,因此以rpm方式安装(两台虚拟机上做同样操作)。
> cd /home/work
> sudo rpm -ivh *.rpm
# 增加IP和Host域名
> sudo vi /etc/hosts
172.16.185.167 clickhouse01
172.16.185.168 clickhouse02
# 取消<listen_host>0.0.0.0</listen_host>的注释
> sudo vi /etc/clickhouse-server/config.xml
<listen_host>0.0.0.0</listen_host>服务启停相关命令。
> systemctl start clickhouse-server
> systemctl stop clickhouse-server
> systemctl restart clickhouse-server
> systemctl status clickhouse-server安装副本(两台虚拟机上做同样操作)
修改Clickhouse的配置文件。
> sudo vi /etc/clickhouse-server/config.xml
# 找到zookeeper节点,增加下面的内容
<zookeeper>
<node>
<host>172.16.185.166</host>
<port>2181</port>
</node>
</zookeeper>
# 重启clickhouse
> systemctl restart clickhouse-server在每个Clickhouse服务器中均创建表users(因为副本只能同步数据,不能同步表结构)。
-- 172.16.185.167(节点1)
:) CREATE TABLE users
(
user_id UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/users', 'users-replica-1')
ORDER BY (user_id)
-- 172.16.185.168(节点2)
:) CREATE TABLE users
(
user_id UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/users', 'users-replica-2')
ORDER BY (user_id)ReplicatedMergeTree的格式为ReplicatedMergeTree('${zoo_path}', '${replica_name}')
${zoo_path}:表示在ZooKeeper中该表的路径,可自定义名称,同一张表的同一分片的不同副本,要定义相同的路径。${replica_name}:表示ZooKeeper中的该表的副本名称,同一张表的同一分片的不同副本,要定义不同的名称。
ReplicatedMergeTree如果没有参数则使用/clickhouse/tables/${uuid}/${shard}和${replica}。
这些可以在配置文件
config.xml的default_replica_path和default_replica_name属性中更改。变量
${uuid}被表的uuid替换,而${shard}和${replica}则被配置文件config.xml中的值替换,而不是数据库引擎参数。但是将来可以使用
Replicated数据库引擎的shard_name和replica_name。
副本配置成功后,两台Clickhouse服务器的数据库中都会多出一个ZooKeeper表。
插入数据,测试结果。
-- 在172.16.185.167(节点1)上执行
:) INSERT INTO users VALUES(1),(2),(3)
:) SELECT * FROM users
┌───id───┐
│ 1 │
│ 2 │
│ 3 │
└────────┘然后在172.16.185.168(节点2)中查询结果即可。
安装分片(两台虚拟机上做同样操作)
修改Clickhouse的配置文件。
<remote_servers>
<!-- 分片集群名称 -->
<cluster_2shards>
<!-- 分片1 -->
<shard>
<replica>
<host>172.16.185.167</host>
<port>9000</port>
</replica>
</shard>
<!-- 分片2 -->
<shard>
<replica>
<host>172.16.185.168</host>
<port> 9000</port>
</replica>
</shard>
</cluster_2shards>
</remote_servers>重启Clickhouse。
> systemctl restart clickhouse-server可通过查询来判断是否配置成功(重启后能查询到)。
:) SELECT * FROM system.clusters插入数据,测试结果。
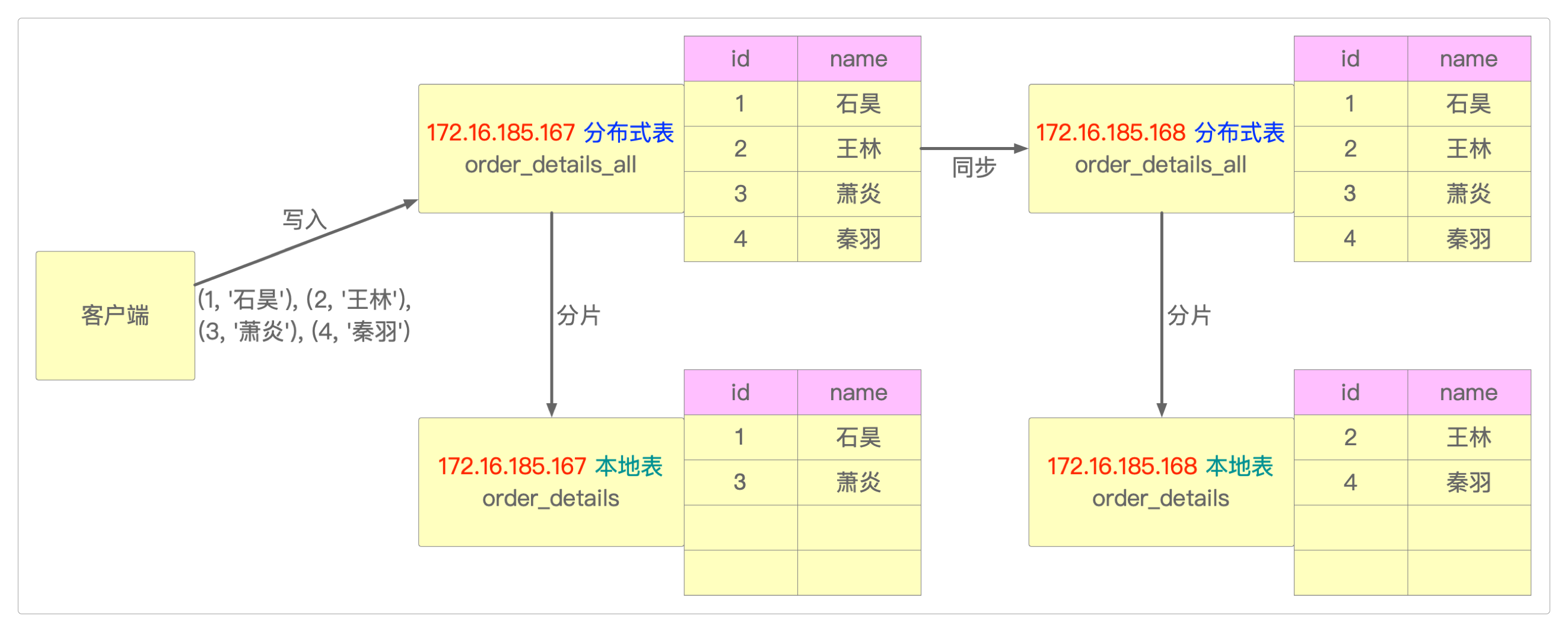
-- 创建本地表(在一个节点上创建,另外一个节点也会同步)
:) CREATE TABLE order_details ON CLUSTER cluster_2shards
(
id Int8,
name String
) ENGINE = MergeTree
ORDER BY id;
-- 创建分布式表
:) CREATE TABLE order_details_all ON CLUSTER cluster_2shards
(
id Int8,
name String
) Distributed(cluster_2shards, default, order_details, hiveHash(id));分布式表order_details_all创建之后会出现在每个节点的视图中。
:) SELECT * FROM order_details_all向分布式表order_details_all中插入数据。
:) INSERT INTO order_details_all VALUES(1, '石昊'), (2, '王林'), (3, '萧炎'), (4, '秦羽');在任意节点查询分布式表,可查询到全部数据。
:) SELECT * FROM order_details_all
┌───id───┬────name────┐
│ 1 │ 石昊 │
│ 2 │ 王林 │
│ 3 │ 萧炎 │
│ 4 │ 秦羽 │
└────────┴────────────┘在任意节点查询本地表,只能查询到部分数据(两个节点数据合并后就是全部的数据)。
:) SELECT * FROM order_details有两种方式向集群中写入数据。
- 指定将哪些数据写入哪些本地数据表,然后在分布式表中查询,这样各个不同节点的数据将完全独立。

- 或者,直接在分布式表中执行
INSERT,数据将按分片权重分布到各个本地表中。
感谢支持
更多内容,请移步《超级个体》。