
窗口函数
所谓窗口函数,就是相当于在一个独立的窗口空间里对数据进行计算和分析,但不改变原始数据。
而且窗口还可以根据事先设置的条件动态滑动,例如基于时间滑动。
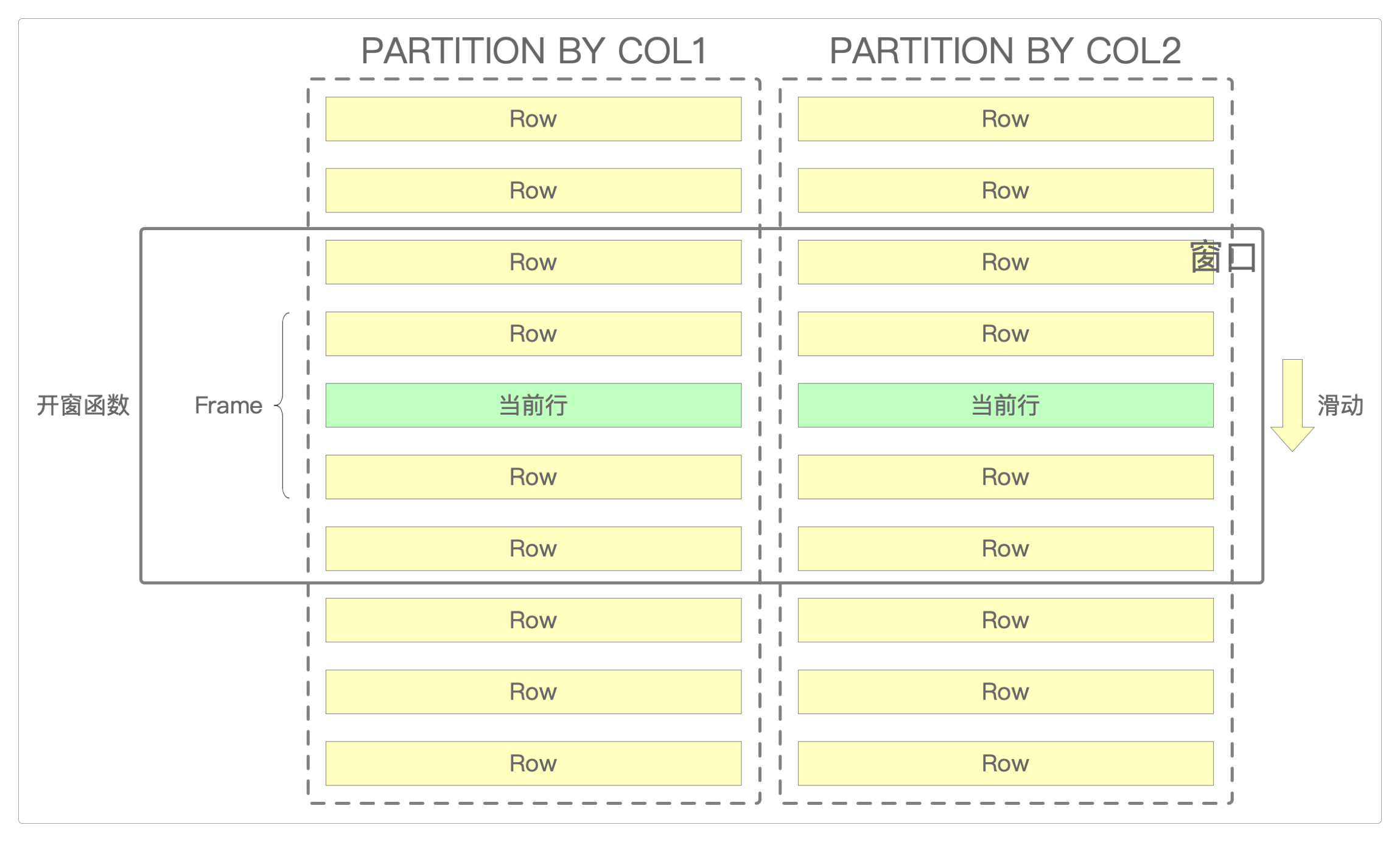
窗口函数
1. 语法
aggregate_function (column_name)
OVER ([[PARTITION BY grouping_column] [ORDER BY sorting_column] [ROWS or RANGE expression_to_bound_rows_withing_the_group]] | [window_name])
FROM table_name
WINDOW window_name as ([PARTITION BY grouping_column] [ORDER BY sorting_column])PARTITION BY:定义如何将结果集分组。ORDER BY:定义在计算聚合函数期间如何对组内的行进行排序。ROWS或RANGE:定义Frame的边界,aggregate_function在Frame内计算。WINDOW:允许多个表达式使用相同的窗口定义。
整个窗口函数的定义可以这样拆分开来看。
{}:表示定义的变量。[]:表示可选项。
aggregate_function (column_name)
OVER ( {window_spec} | [{window_name}] )
FROM table_name
WINDOW {window_name} as ( {window_spec} )各组成部分含义如下。
{window_spec}:[PARTITION BY子句][ORDER BY子句][ROWS or RANGE子句]。[PARTITION BY子句]:PARTITION BY col1 [, col2...]。[ORDER BY子句]:ORDER BY col1 [ASC | DESC] [, col2 [ASC | DESC]...]。[ROWS or RANGE子句]:{ ROWS | RANGE frame_extent}(frame_extent=expression_to_bound_rows_withing_the_group)。frame_extent:{frame_start | frame_end | frame_between}frame_start:{CURRENT ROW | UNBOUNDED PRECEDING | UNBOUNDED FOLLOWING | expr PRECEDING | expr FOLLOWING}。frame_end:{CURRENT ROW | UNBOUNDED PRECEDING | UNBOUNDED FOLLOWING | expr PRECEDING | expr FOLLOWING}。frame_between:BETWEEN frame_start AND frame_end。
各行标记含义如下。
UNBOUNDED:无限的。PRECEDING:在...之前。FOLLOWING:在...之后。{n} PRECEDING:前面的 n 行。{n} FOLLOWING:后面的 n 行。UNBOUNDED PRECEDING:前面所有的行。CURRENT ROW:当前行。UNBOUNDED FOLLOWING:后面所有的行。
这样一步步地来理解窗口函数的语法就会相对容易一些。
官方画的图也是这样标记的。
PARTITION
┌─────────────────┐ <-- UNBOUNDED PRECEDING (BEGINNING of the PARTITION) <-- frame_start
│ │
│ │
│=================│ <-- N PRECEDING <─┐
│ N ROWS │ │ F
│ Before CURRENT │ │ R
│~~~~~~~~~~~~~~~~~│ <-- CURRENT ROW │ A <-- frame_between
│ M ROWS │ │ M
│ After CURRENT │ │ E
│=================│ <-- M FOLLOWING <─┘
│ │
│ │
└─────────────────┘ <--- UNBOUNDED FOLLOWING (END of the PARTITION) <-- frame_end可以将两种类型的函数应用于窗口。
只能作为窗口使用的函数。
row_number():从1开始对分区内的当前行进行编号。first_value(x):返回在其有序帧内计算的第一个非NULL值。last_value(x):返回在其有序帧内计算的最后一个非NULL值。nth_value(x, offset):返回排序Frame中第n行(offset)的第一个非NULL值。rank():用间隔对当前行在其分区内进行排名。dense_rank():不用间隔对当前行在其分区内进行排名。lagInFrame(x):返回在有序Frame中当前行之前指定物理偏移行处的计算值。leadInFrame(x):返回在有序Frame中当前行之后偏移行的行处计算的值。
常规聚合函数。
所有的标准聚合函数,如
min、max和avg等。特定的聚合函数,如
argMin、argMax和avgWeighted等。
2. 简单使用示例
知道了语法,再来看看怎么用。
2.1 移动平均线
滑动计算当前行与前面3行的平均值。
:) SELECT number, avg(number) OVER (ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS avg
FROM values('number Int8', 1, 2, 3, 4, 5, 6, 7, 8);
┌─number─┬─avg─┐
│ 1 │ 1 │
│ 2 │ 1.5 │
│ 3 │ 2 │
│ 4 │ 2.5 │
│ 5 │ 3.5 │
│ 6 │ 4.5 │
│ 7 │ 5.5 │
│ 8 │ 6.5 │
└────────┴─────┘窗口从第一行开始往下移动,每移动一行,都会计算与前面三行的平均值。如果不足3行,则计算前面所有的行。
2.2 移动求和
滑动计算当前行与前两行的和。
:) SELECT number, SUM(number) OVER (ORDER BY number ASC RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum
FROM (SELECT array(1, 7, 8, 4, 5, 3, 2, 6) AS number) ARRAY JOIN number;
┌─number─┬─sum─┐
│ 1 │ 1 │
│ 2 │ 3 │
│ 3 │ 6 │
│ 4 │ 9 │
│ 5 │ 12 │
│ 6 │ 15 │
│ 7 │ 18 │
│ 8 │ 21 │
└────────┴─────┘:) SELECT number, SUM(number) OVER (RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum
FROM (SELECT array(1, 7, 8, 4, 5, 3, 2, 6) AS number) ARRAY JOIN number;
┌─number─┬─sum─┐
│ 1 │ 36 │
│ 7 │ 36 │
│ 8 │ 36 │
│ 4 │ 36 │
│ 5 │ 36 │
│ 3 │ 36 │
│ 2 │ 36 │
│ 6 │ 36 │
└────────┴─────┘如果没有ORDER BY,就无法使用n PRECEDING条件,那么所有的行都只能作为当前行,不然会报错。
反之,使用了ORDER BY,就不能用CURRENT ROW AND CURRENT ROW这样的条件,也会报错。
2.3 官方示例
官方带的几个开窗例子都不错,虽然有些是错误的,这里稍微优化一下。
先创建数据表。
:) CREATE TABLE t_window_func
(
key UInt64,
value UInt64,
order UInt64
) ENGINE = Memory();
:) INSERT INTO t_window_func VALUES
(1, 8, 1),
(1, 5, 2),
(1, 8, 3),
(2, 39, 4),
(2, 17, 5),
(3, 21, 6),
(3, 6, 7),
(3, 44, 8),
(4, 61, 9),
(4, 50, 10);
┌─key─┬─value─┬─order─┐
│ 1 │ 8 │ 1 │
│ 1 │ 5 │ 2 │
│ 1 │ 8 │ 3 │
│ 2 │ 39 │ 4 │
│ 2 │ 17 │ 5 │
│ 3 │ 21 │ 6 │
│ 3 │ 6 │ 7 │
│ 3 │ 44 │ 8 │
│ 4 │ 61 │ 9 │
│ 4 │ 50 │ 10 │
└─────┴───────┴───────┘- 先来个简单的,看看
row_number()、rank()和dense_rank()这三个开窗函数的不同。
:) SELECT key, value,
row_number() OVER (ORDER BY value) AS row,
rank() OVER (ORDER BY value) AS rank,
dense_rank() OVER (ORDER BY value) AS denseRank
FROM t_window_func;
┌─key─┬─value─┬─row─┬─rank─┬─denseRank─┐
│ 1 │ 5 │ 1 │ 1 │ 1 │
│ 3 │ 6 │ 2 │ 2 │ 2 │
│ 1 │ 8 │ 3 │ 3 │ 3 │
│ 1 │ 8 │ 4 │ 3 │ 3 │
│ 2 │ 17 │ 5 │ 5 │ 4 │
│ 3 │ 21 │ 6 │ 6 │ 5 │
│ 2 │ 39 │ 7 │ 7 │ 6 │
│ 3 │ 44 │ 8 │ 8 │ 7 │
│ 4 │ 50 │ 9 │ 9 │ 8 │
│ 4 │ 61 │ 10 │ 10 │ 9 │
└─────┴───────┴─────┴──────┴───────────┘可以看到rank()和dense_rank()都出现了重复的序号,但row_number()没有。
row_number()不允许出现并列排名,所有序号都连续排列。rank()方法会出现并列排名的情况,也就是如果有两个第一,那么接着后面就是第三。比如上面的两个3之后就是5。dense_rank()和rank()类似,但排名是连续的,也就是不会从1突然跳到3。比如上面的两个3之后是4而不是5。
- 将开窗函数用于聚合。
:) SELECT key, value,
ROUND(avg(value) OVER (PARTITION BY key), 2) AS vavg,
ROUND(value - part, 2) AS diff
FROM t_window_func;
┌─key─┬─value─┬──vavg─┬───diff─┐
│ 1 │ 8 │ 7 │ 1 │
│ 1 │ 5 │ 7 │ -2 │
│ 1 │ 8 │ 7 │ 1 │
│ 2 │ 39 │ 28 │ 11 │
│ 2 │ 17 │ 28 │ -11 │
│ 3 │ 21 │ 23.67 │ -2.67 │
│ 3 │ 6 │ 23.67 │ -17.67 │
│ 3 │ 44 │ 23.67 │ 20.33 │
│ 4 │ 61 │ 55.5 │ 5.5 │
│ 4 │ 50 │ 55.5 │ -5.5 │
└─────┴───────┴───────┴────────┘这里按key字段进行分区,并计算了不同分区中value字段的平均值vavg,以及每个value与平均值的差。
开窗SQL语句有完整形式和简短形式,可以这样写查询语句。
-- 完整形式
:) SELECT key, value, order,
groupArray(value) OVER (
PARTITION BY key
ORDER BY order ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS vframe
FROM t_window_func;
-- 简短形式
:) SELECT key, value, order,
groupArray(value) OVER (
PARTITION BY key
) AS vframe
FROM t_window_func;
┌─key─┬─value─┬─order─┬─vframe────┐
│ 1 │ 8 │ 1 │ [8,5,8] │
│ 1 │ 5 │ 2 │ [8,5,8] │
│ 1 │ 8 │ 3 │ [8,5,8] │
│ 2 │ 39 │ 4 │ [39,17] │
│ 2 │ 17 │ 5 │ [39,17] │
│ 3 │ 21 │ 6 │ [21,6,44] │
│ 3 │ 6 │ 7 │ [21,6,44] │
│ 3 │ 44 │ 8 │ [21,6,44] │
│ 4 │ 61 │ 9 │ [61,50] │
│ 4 │ 50 │ 10 │ [61,50] │
└─────┴───────┴───────┴───────────┘上面的完整形式和简短形式官方说效果是一样的。只是看起来一样,如果将order列值不按顺序插入,而是打乱顺序,带上ORDER BY order之后效果就不一样了。
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING就是把所有行全部带上了,即使不写默认也是带上全部行。
为了看到所谓UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING的效果,可以这样写。
:) SELECT key, value, order,
groupArray(value) OVER (
PARTITION BY key
ORDER BY order ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS vframe
FROM t_window_func;
┌─key─┬─value─┬─order─┬─vframe────┐
│ 1 │ 8 │ 1 │ [8] │
│ 1 │ 5 │ 2 │ [8,5] │
│ 1 │ 8 │ 3 │ [8,5,8] │
│ 2 │ 39 │ 4 │ [39] │
│ 2 │ 17 │ 5 │ [39,17] │
│ 3 │ 21 │ 6 │ [21] │
│ 3 │ 6 │ 7 │ [21,6] │
│ 3 │ 44 │ 8 │ [21,6,44] │
│ 4 │ 61 │ 9 │ [61] │
│ 4 │ 50 │ 10 │ [61,50] │
└─────┴───────┴───────┴───────────┘可以明显地看到一个阶梯(从[8] -> [8,5] ->[8,5,8])。如果将BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW换成BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING,那就是一个倒阶梯了。
现在再来看看滑动窗口:每个当前行和它的前一行。
:) SELECT key, value, order,
groupArray(value) OVER (
PARTITION BY key
ORDER BY order ASC
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
) AS vframe
FROM t_window_func;
┌─key─┬─value─┬─order─┬─vframe──┐
│ 1 │ 8 │ 1 │ [8] │
│ 1 │ 5 │ 2 │ [8,5] │
│ 1 │ 8 │ 3 │ [5,8] │
│ 2 │ 39 │ 4 │ [39] │
│ 2 │ 17 │ 5 │ [39,17] │
│ 3 │ 21 │ 6 │ [21] │
│ 3 │ 6 │ 7 │ [21,6] │
│ 3 │ 44 │ 8 │ [6,44] │
│ 4 │ 61 │ 9 │ [61] │
│ 4 │ 50 │ 10 │ [61,50] │
└─────┴───────┴───────┴─────────┘关于row_number()和n PRECEDING、n FOLLOWING的关系,下面这个查询讲的比较清楚了。
:) SELECT
key,
value,
order,
groupArray(value) OVER w1 AS vframe,
row_number() OVER w1 AS rn_1,
sum(1) OVER w1 AS rn_2,
row_number() OVER w2 AS rn_3,
sum(1) OVER w2 AS rn_4
FROM t_window_func
WINDOW
w1 AS (PARTITION BY key ORDER BY order ASC),
w2 AS (
PARTITION BY key
ORDER BY order ASC
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
) ORDER BY key, order;
┌─key─┬─value─┬─order─┬─vframe────┬─rn_1─┬─rn_2─┬─rn_3─┬─rn_4─┐
│ 1 │ 8 │ 1 │ [8] │ 1 │ 1 │ 1 │ 1 │
│ 1 │ 5 │ 2 │ [8,5] │ 2 │ 2 │ 2 │ 2 │
│ 1 │ 8 │ 3 │ [8,5,8] │ 3 │ 3 │ 3 │ 2 │
│ 2 │ 39 │ 4 │ [39] │ 1 │ 1 │ 1 │ 1 │
│ 2 │ 17 │ 5 │ [39,17] │ 2 │ 2 │ 2 │ 2 │
│ 3 │ 21 │ 6 │ [21] │ 1 │ 1 │ 1 │ 1 │
│ 3 │ 6 │ 7 │ [21,6] │ 2 │ 2 │ 2 │ 2 │
│ 3 │ 44 │ 8 │ [21,6,44] │ 3 │ 3 │ 3 │ 2 │
│ 4 │ 61 │ 9 │ [61] │ 1 │ 1 │ 1 │ 1 │
│ 4 │ 50 │ 10 │ [61,50] │ 2 │ 2 │ 2 │ 2 │
└─────┴───────┴───────┴───────────┴──────┴──────┴──────┴──────┘理解了上面这个查询,基本上整个{window_spec}就都清楚了。
再加上first_value()和last_value()试一试。
:) SELECT
groupArray(value) OVER w1 AS frame_values_1,
first_value(value) OVER w1 AS first_value_1,
last_value(value) OVER w1 AS last_value_1,
groupArray(value) OVER w2 AS frame_values_2,
first_value(value) OVER w2 AS first_value_2,
last_value(value) OVER w2 AS last_value_2,
lagInFrame(value) OVER w3 AS lagInFrame,
leadInFrame(value) OVER w4 AS leadInFrame
FROM t_window_func
WINDOW
w1 AS (PARTITION BY key ORDER BY order ASC),
w2 AS (PARTITION BY key ORDER BY order ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW),
w3 AS (PARTITION BY key ORDER BY order ASC ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING),
w4 AS (PARTITION BY key ORDER BY order ASC ROWS BETWEEN 1 FOLLOWING AND 1 FOLLOWING)
ORDER BY key, order;
┌─frame_values_1─┬─first_value_1─┬─last_value_1─┬─frame_values_2─┬─first_value_2─┬─last_value_2─┬─lagInFrame─┬─leadInFrame─┐
│ [8] │ 8 │ 8 │ [8] │ 8 │ 8 │ 0 │ 5 │
│ [8,5] │ 8 │ 5 │ [8,5] │ 8 │ 5 │ 8 │ 8 │
│ [8,5,8] │ 8 │ 8 │ [5,8] │ 5 │ 8 │ 5 │ 0 │
│ [39] │ 39 │ 39 │ [39] │ 39 │ 39 │ 0 │ 17 │
│ [39,17] │ 39 │ 17 │ [39,17] │ 39 │ 17 │ 39 │ 0 │
│ [21] │ 21 │ 21 │ [21] │ 21 │ 21 │ 0 │ 6 │
│ [21,6] │ 21 │ 6 │ [21,6] │ 21 │ 6 │ 21 │ 44 │
│ [21,6,44] │ 21 │ 44 │ [6,44] │ 6 │ 44 │ 6 │ 0 │
│ [61] │ 61 │ 61 │ [61] │ 61 │ 61 │ 0 │ 50 │
│ [61,50] │ 61 │ 50 │ [61,50] │ 61 │ 50 │ 61 │ 0 │
└────────────────┴───────────────┴──────────────┴────────────────┴───────────────┴──────────────┴────────────┴─────────────┘其中,lagInFrame既可以理解为同比,也可以理解为环比(不同时间跨度的区别而已)。
至于leadInFrame,则只是单纯地与后一条相比较。
3. 自建测试数据
把之前在聚合函数组合器中用到的表结构再拿过来。
:) CREATE TABLE t_employee
(
id UInt16,
name String,
job String,
leaderid UInt16,
hiredate Date,
salaries decimal(10, 2),
bonus decimal(8, 2),
departid UInt32
) ENGINE = MergeTree()
ORDER BY id;
:) INSERT INTO t_employee VALUES
(1, '萧炎', '销售员', 13, '2023-12-17', 2800, null, 2),
(2, '柳神', '市场人员', 6,'2023-02-20', 1600, 300, 3),
(3, '李慕婉', '营销部长', 6, '2023-02-22', 2250, 500, 3),
(4, '秦羽', '销售部长', 9, '2023-04-02', 2975, null, 2),
(5, '姜立', '市场人员', 6, '2023-09-28', 2250, 1400, 3),
(6, '罗峰', '市场经理', 9, '2023-05-01', 2850, null, 3),
(7, '唐三', '项目经理', 9, '2023-06-09', 2450, null, 1),
(8, '徐欣', '营销人员', 4, '2023-04-19', 3000, null, 2),
(9, '石昊', '架构师', null, '2023-11-17', 5000, null, 1),
(10, '云韵', '市场人员', 6, '2023-09-08', 1500, 0, 3),
(11, '龙昊晨', '销售员', 8, '2023-05-23', 1100, null, 2),
(12, '美杜莎', '市场人员', 6, '2023-12-03', 1950, null, 3),
(13, '王林', '营销人员', 4,'2023-12-02', 3000, null, 2),
(14, '小舞', '软件工程师', 7, '2023-01-23', 2300, null, 1);
:) CREATE TABLE t_department
(
id UInt32,
name String,
location String
) ENGINE = MergeTree()
ORDER BY id;
:) INSERT INTO t_department VALUES
(1, '研发部', '北京'),
(2, '销售部', '上海'),
(3, '营销部', '武汉'),
(4, '客服部', '西安');分别用rank()、dense_rank()和row_number()按部门对不同职员进行薪资排序,得到每个职员的排序序号。
3.1 rank()
:) SELECT departid, name, hiredate, salaries,
rank() OVER (PARTITION BY departid ORDER BY salaries DESC) AS rank
FROM t_employee;
┌─departid─┬─name───┬───hiredate─┬─salaries─┬─rank─┐
│ 1 │ 石昊 │ 2023-11-17 │ 5000 │ 1 │
│ 1 │ 唐三 │ 2023-06-09 │ 2450 │ 2 │
│ 1 │ 小舞 │ 2023-01-23 │ 2300 │ 3 │
│ 2 │ 徐欣 │ 2023-04-19 │ 3000 │ 1 │
│ 2 │ 王林 │ 2023-12-02 │ 3000 │ 1 │
│ 2 │ 秦羽 │ 2023-04-02 │ 2975 │ 3 │
│ 2 │ 萧炎 │ 2023-12-17 │ 2800 │ 4 │
│ 2 │ 龙昊晨 │ 2023-05-23 │ 1100 │ 5 │
│ 3 │ 罗峰 │ 2023-05-01 │ 2850 │ 1 │
│ 3 │ 李慕婉 │ 2023-02-22 │ 2250 │ 2 │
│ 3 │ 姜立 │ 2023-09-28 │ 2250 │ 2 │
│ 3 │ 美杜莎 │ 2023-12-03 │ 1950 │ 4 │
│ 3 │ 柳神 │ 2023-02-20 │ 1600 │ 5 │
│ 3 │ 云韵 │ 2023-09-08 │ 1500 │ 6 │
└──────────┴────────┴────────────┴──────────┴──────┘3.2 dense_rank()
:) SELECT departid, name, hiredate, salaries,
dense_rank() OVER (PARTITION BY departid ORDER BY salaries DESC) AS rank
FROM t_employee;
┌─departid─┬─name───┬───hiredate─┬─salaries─┬─rank─┐
│ 1 │ 石昊 │ 2023-11-17 │ 5000 │ 1 │
│ 1 │ 唐三 │ 2023-06-09 │ 2450 │ 2 │
│ 1 │ 小舞 │ 2023-01-23 │ 2300 │ 3 │
│ 2 │ 徐欣 │ 2023-04-19 │ 3000 │ 1 │
│ 2 │ 王林 │ 2023-12-02 │ 3000 │ 1 │
│ 2 │ 秦羽 │ 2023-04-02 │ 2975 │ 2 │
│ 2 │ 萧炎 │ 2023-12-17 │ 2800 │ 3 │
│ 2 │ 龙昊晨 │ 2023-05-23 │ 1100 │ 4 │
│ 3 │ 罗峰 │ 2023-05-01 │ 2850 │ 1 │
│ 3 │ 李慕婉 │ 2023-02-22 │ 2250 │ 2 │
│ 3 │ 姜立 │ 2023-09-28 │ 2250 │ 2 │
│ 3 │ 美杜莎 │ 2023-12-03 │ 1950 │ 3 │
│ 3 │ 柳神 │ 2023-02-20 │ 1600 │ 4 │
│ 3 │ 云韵 │ 2023-09-08 │ 1500 │ 5 │
└──────────┴────────┴────────────┴──────────┴──────┘3.3 row_number()
:) SELECT departid, name, hiredate, salaries,
row_number() OVER (PARTITION BY departid ORDER BY salaries DESC) AS rownumber
FROM t_employee;
┌─departid─┬─name───┬───hiredate─┬─salaries─┬─rownumber─┐
│ 1 │ 石昊 │ 2023-11-17 │ 5000 │ 1 │
│ 1 │ 唐三 │ 2023-06-09 │ 2450 │ 2 │
│ 1 │ 小舞 │ 2023-01-23 │ 2300 │ 3 │
│ 2 │ 徐欣 │ 2023-04-19 │ 3000 │ 1 │
│ 2 │ 王林 │ 2023-12-02 │ 3000 │ 2 │
│ 2 │ 秦羽 │ 2023-04-02 │ 2975 │ 3 │
│ 2 │ 萧炎 │ 2023-12-17 │ 2800 │ 4 │
│ 2 │ 龙昊晨 │ 2023-05-23 │ 1100 │ 5 │
│ 3 │ 罗峰 │ 2023-05-01 │ 2850 │ 1 │
│ 3 │ 李慕婉 │ 2023-02-22 │ 2250 │ 2 │
│ 3 │ 姜立 │ 2023-09-28 │ 2250 │ 3 │
│ 3 │ 美杜莎 │ 2023-12-03 │ 1950 │ 4 │
│ 3 │ 柳神 │ 2023-02-20 │ 1600 │ 5 │
│ 3 │ 云韵 │ 2023-09-08 │ 1500 │ 6 │
└──────────┴────────┴────────────┴──────────┴───────────┘3.4 开窗聚合
除了排名,开窗函数一般情况下,更多地是用于诸如总数、求和、平均值、最大值、最小值以及差额等聚合计算。
这里也可以仔细体会一下下面三条不同SQL语句之间的差别,看看它们分别执行后每一列的数据有什么变化。
:) SELECT d.name AS deptname, name AS empname, e.hiredate, e.salaries,
COUNT(*) OVER win AS count,
SUM(e.salaries) OVER win AS sum,
ROUND(AVG(e.salaries) OVER win, 2) AS avg,
MAX(e.salaries) OVER win AS max,
MIN(e.salaries) OVER win AS min,
max - salaries AS diff
FROM t_employee AS e JOIN t_department AS d ON e.departid = d.id
WINDOW win AS (PARTITION BY e.departid);
┌─deptname─┬─empname─┬───hiredate─┬─salaries─┬─count─┬───sum─┬─────avg─┬──max─┬──min─┬─diff─┐
│ 研发部 │ 唐三 │ 2023-06-09 │ 2450 │ 3 │ 9750 │ 3250 │ 5000 │ 2300 │ 2550 │
│ 研发部 │ 石昊 │ 2023-11-17 │ 5000 │ 3 │ 9750 │ 3250 │ 5000 │ 2300 │ 0 │
│ 研发部 │ 小舞 │ 2023-01-23 │ 2300 │ 3 │ 9750 │ 3250 │ 5000 │ 2300 │ 2700 │
│ 销售部 │ 萧炎 │ 2023-12-17 │ 2800 │ 5 │ 12875 │ 2575 │ 3000 │ 1100 │ 200 │
│ 销售部 │ 秦羽 │ 2023-04-02 │ 2975 │ 5 │ 12875 │ 2575 │ 3000 │ 1100 │ 25 │
│ 销售部 │ 徐欣 │ 2023-04-19 │ 3000 │ 5 │ 12875 │ 2575 │ 3000 │ 1100 │ 0 │
│ 销售部 │ 龙昊晨 │ 2023-05-23 │ 1100 │ 5 │ 12875 │ 2575 │ 3000 │ 1100 │ 1900 │
│ 销售部 │ 王林 │ 2023-12-02 │ 3000 │ 5 │ 12875 │ 2575 │ 3000 │ 1100 │ 0 │
│ 营销部 │ 柳神 │ 2023-02-20 │ 1600 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 1250 │
│ 营销部 │ 李慕婉 │ 2023-02-22 │ 2250 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 600 │
│ 营销部 │ 姜立 │ 2023-09-28 │ 2250 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 600 │
│ 营销部 │ 罗峰 │ 2023-05-01 │ 2850 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 0 │
│ 营销部 │ 云韵 │ 2023-09-08 │ 1500 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 1350 │
│ 营销部 │ 美杜莎 │ 2023-12-03 │ 1950 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 900 │
└──────────┴─────────┴────────────┴──────────┴───────┴───────┴─────────┴──────┴──────┴──────┘
-- 开窗中带上了 `ORDER BY e.salaries DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW`
:) SELECT d.name AS deptname, name AS empname, e.hiredate, e.salaries,
COUNT(*) OVER win AS count,
SUM(e.salaries) OVER win AS sum,
ROUND(AVG(e.salaries) OVER win, 2) AS avg,
MAX(e.salaries) OVER win AS max,
MIN(e.salaries) OVER win AS min,
max - salaries AS diff
FROM t_employee AS e JOIN t_department AS d ON e.departid = d.id
WINDOW win AS (PARTITION BY e.departid ORDER BY e.salaries DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);
┌─deptname─┬─empname─┬───hiredate─┬─salaries─┬─count─┬───sum─┬─────avg─┬──max─┬──min─┬─diff─┐
│ 研发部 │ 石昊 │ 2023-11-17 │ 5000 │ 1 │ 5000 │ 5000 │ 5000 │ 5000 │ 0 │
│ 研发部 │ 唐三 │ 2023-06-09 │ 2450 │ 2 │ 7450 │ 3725 │ 5000 │ 2450 │ 2550 │
│ 研发部 │ 小舞 │ 2023-01-23 │ 2300 │ 3 │ 9750 │ 3250 │ 5000 │ 2300 │ 2700 │
│ 销售部 │ 徐欣 │ 2023-04-19 │ 3000 │ 1 │ 3000 │ 3000 │ 3000 │ 3000 │ 0 │
│ 销售部 │ 王林 │ 2023-12-02 │ 3000 │ 2 │ 6000 │ 3000 │ 3000 │ 3000 │ 0 │
│ 销售部 │ 秦羽 │ 2023-04-02 │ 2975 │ 3 │ 8975 │ 2991.67 │ 3000 │ 2975 │ 25 │
│ 销售部 │ 萧炎 │ 2023-12-17 │ 2800 │ 4 │ 11775 │ 2943.75 │ 3000 │ 2800 │ 200 │
│ 销售部 │ 龙昊晨 │ 2023-05-23 │ 1100 │ 5 │ 12875 │ 2575 │ 3000 │ 1100 │ 1900 │
│ 营销部 │ 罗峰 │ 2023-05-01 │ 2850 │ 1 │ 2850 │ 2850 │ 2850 │ 2850 │ 0 │
│ 营销部 │ 李慕婉 │ 2023-02-22 │ 2250 │ 2 │ 5100 │ 2550 │ 2850 │ 2250 │ 600 │
│ 营销部 │ 姜立 │ 2023-09-28 │ 2250 │ 3 │ 7350 │ 2450 │ 2850 │ 2250 │ 600 │
│ 营销部 │ 美杜莎 │ 2023-12-03 │ 1950 │ 4 │ 9300 │ 2325 │ 2850 │ 1950 │ 900 │
│ 营销部 │ 柳神 │ 2023-02-20 │ 1600 │ 5 │ 10900 │ 2180 │ 2850 │ 1600 │ 1250 │
│ 营销部 │ 云韵 │ 2023-09-08 │ 1500 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 1350 │
└──────────┴─────────┴────────────┴──────────┴───────┴───────┴─────────┴──────┴──────┴──────┘
-- 把 `ORDER BY e.salaries DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW` 中的 `ROWS` 换成了 `RANGE`
:) SELECT d.name AS deptname, name AS empname, e.hiredate, e.salaries,
COUNT(*) OVER win AS count,
SUM(e.salaries) OVER win AS sum,
ROUND(AVG(e.salaries) OVER win, 2) AS avg,
MAX(e.salaries) OVER win AS max,
MIN(e.salaries) OVER win AS min,
max - salaries AS diff
FROM t_employee AS e JOIN t_department AS d ON e.departid = d.id
WINDOW win AS (PARTITION BY e.departid ORDER BY e.salaries DESC RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);
┌─deptname─┬─empname─┬───hiredate─┬─salaries─┬─count─┬───sum─┬─────avg─┬──max─┬──min─┬─diff─┐
│ 研发部 │ 石昊 │ 2023-11-17 │ 5000 │ 1 │ 5000 │ 5000 │ 5000 │ 5000 │ 0 │
│ 研发部 │ 唐三 │ 2023-06-09 │ 2450 │ 2 │ 7450 │ 3725 │ 5000 │ 2450 │ 2550 │
│ 研发部 │ 小舞 │ 2023-01-23 │ 2300 │ 3 │ 9750 │ 3250 │ 5000 │ 2300 │ 2700 │
│ 销售部 │ 徐欣 │ 2023-04-19 │ 3000 │ 2 │ 6000 │ 3000 │ 3000 │ 3000 │ 0 │
│ 销售部 │ 王林 │ 2023-12-02 │ 3000 │ 2 │ 6000 │ 3000 │ 3000 │ 3000 │ 0 │
│ 销售部 │ 秦羽 │ 2023-04-02 │ 2975 │ 3 │ 8975 │ 2991.67 │ 3000 │ 2975 │ 25 │
│ 销售部 │ 萧炎 │ 2023-12-17 │ 2800 │ 4 │ 11775 │ 2943.75 │ 3000 │ 2800 │ 200 │
│ 销售部 │ 龙昊晨 │ 2023-05-23 │ 1100 │ 5 │ 12875 │ 2575 │ 3000 │ 1100 │ 1900 │
│ 营销部 │ 罗峰 │ 2023-05-01 │ 2850 │ 1 │ 2850 │ 2850 │ 2850 │ 2850 │ 0 │
│ 营销部 │ 李慕婉 │ 2023-02-22 │ 2250 │ 3 │ 7350 │ 2450 │ 2850 │ 2250 │ 600 │
│ 营销部 │ 姜立 │ 2023-09-28 │ 2250 │ 3 │ 7350 │ 2450 │ 2850 │ 2250 │ 600 │
│ 营销部 │ 美杜莎 │ 2023-12-03 │ 1950 │ 4 │ 9300 │ 2325 │ 2850 │ 1950 │ 900 │
│ 营销部 │ 柳神 │ 2023-02-20 │ 1600 │ 5 │ 10900 │ 2180 │ 2850 │ 1600 │ 1250 │
│ 营销部 │ 云韵 │ 2023-09-08 │ 1500 │ 6 │ 12400 │ 2066.67 │ 2850 │ 1500 │ 1350 │
└──────────┴─────────┴────────────┴──────────┴───────┴───────┴─────────┴──────┴──────┴──────┘3.5 开窗累计
如果想将薪资按部门排序并进行累计求和,那么可以这样写。
:) SELECT d.name AS deptname, name AS empname, e.hiredate, e.salaries,
-- 第1行 RANK() OVER win AS row,
-- 第2行 SUM(e.salaries) OVER win AS sum
-- 下面一行是第3行
SUM(e.salaries) OVER (PARTITION BY e.departid ORDER BY e.salaries DESC RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sum
FROM t_employee AS e JOIN t_department AS d ON e.departid = d.id
WINDOW win AS (PARTITION BY e.departid ORDER BY e.salaries DESC);
┌─deptname─┬─empname─┬───hiredate─┬─salaries─┬───sum─┐
│ 研发部 │ 石昊 │ 2023-11-17 │ 5000 │ 5000 │
│ 研发部 │ 唐三 │ 2023-06-09 │ 2450 │ 7450 │
│ 研发部 │ 小舞 │ 2023-01-23 │ 2300 │ 9750 │
│ 销售部 │ 徐欣 │ 2023-04-19 │ 3000 │ 6000 │
│ 销售部 │ 王林 │ 2023-12-02 │ 3000 │ 6000 │
│ 销售部 │ 秦羽 │ 2023-04-02 │ 2975 │ 8975 │
│ 销售部 │ 萧炎 │ 2023-12-17 │ 2800 │ 11775 │
│ 销售部 │ 龙昊晨 │ 2023-05-23 │ 1100 │ 12875 │
│ 营销部 │ 罗峰 │ 2023-05-01 │ 2850 │ 2850 │
│ 营销部 │ 李慕婉 │ 2023-02-22 │ 2250 │ 7350 │
│ 营销部 │ 姜立 │ 2023-09-28 │ 2250 │ 7350 │
│ 营销部 │ 美杜莎 │ 2023-12-03 │ 1950 │ 9300 │
│ 营销部 │ 柳神 │ 2023-02-20 │ 1600 │ 10900 │
│ 营销部 │ 云韵 │ 2023-09-08 │ 1500 │ 12400 │
└──────────┴─────────┴────────────┴──────────┴───────┘可以看到结果显示。
徐欣和王林的累计都是6000,这并不是出现错误,而是因为他们是并列的,所以Clickhouse把他们的数据做一行合并处理了。李慕婉和姜立也是这样的情况。把RANK()换成ROW_NUMBER()也是一样。把上面
第1行和第2行的注释取消掉,而把第3行注释,那么查询结果和上面的一致,除了多出一个row列。这说明,当应用Clickhouse自带的开窗函数时,它默认就会做开窗处理。
也可以不通过开窗函数,而是通过groupArray()函数配合ARRAY JOIN子句实现。
:) SELECT d.name AS deptname, name, departid, hiredate, salaries, rank, sum
FROM
(
SELECT
departid,
groupArray(name) name,
groupArray(hiredate) hiredate,
groupArray(salaries) salaries
FROM
(
SELECT *
FROM t_employee
)
GROUP BY departid
) AS e JOIN t_department AS d ON e.departid = d.id
ARRAY JOIN name, hiredate, salaries, arrayCumSum(salaries) AS sum, arrayEnumerate(salaries) AS rank
ORDER BY departid ASC;
┌─deptname─┬─name───┬─departid─┬───hiredate─┬─salaries─┬─rank─┬───sum─┐
│ 研发部 │ 唐三 │ 1 │ 2023-06-09 │ 2450 │ 1 │ 2450 │
│ 研发部 │ 石昊 │ 1 │ 2023-11-17 │ 5000 │ 2 │ 7450 │
│ 研发部 │ 小舞 │ 1 │ 2023-01-23 │ 2300 │ 3 │ 9750 │
│ 销售部 │ 萧炎 │ 2 │ 2023-12-17 │ 2800 │ 1 │ 2800 │
│ 销售部 │ 秦羽 │ 2 │ 2023-04-02 │ 2975 │ 2 │ 5775 │
│ 销售部 │ 徐欣 │ 2 │ 2023-04-19 │ 3000 │ 3 │ 8775 │
│ 销售部 │ 龙昊晨 │ 2 │ 2023-05-23 │ 1100 │ 4 │ 9875 │
│ 销售部 │ 王林 │ 2 │ 2023-12-02 │ 3000 │ 5 │ 12875 │
│ 营销部 │ 柳神 │ 3 │ 2023-02-20 │ 1600 │ 1 │ 1600 │
│ 营销部 │ 李慕婉 │ 3 │ 2023-02-22 │ 2250 │ 2 │ 3850 │
│ 营销部 │ 姜立 │ 3 │ 2023-09-28 │ 2250 │ 3 │ 6100 │
│ 营销部 │ 罗峰 │ 3 │ 2023-05-01 │ 2850 │ 4 │ 8950 │
│ 营销部 │ 云韵 │ 3 │ 2023-09-08 │ 1500 │ 5 │ 10450 │
│ 营销部 │ 美杜莎 │ 3 │ 2023-12-03 │ 1950 │ 6 │ 12400 │
└──────────┴────────┴──────────┴────────────┴──────────┴──────┴───────┘或者再加上高阶函数arraySort()。
:) SELECT d.name AS deptname, name2, departid, hiredate2, salaries2, rank, sum
FROM
(
SELECT
departid,
groupArray(name) name,
groupArray(hiredate) hiredate,
groupArray(salaries) salaries
FROM
(
SELECT *
FROM t_employee
)
GROUP BY departid
) AS e JOIN t_department AS d ON e.departid = d.id
ARRAY JOIN arraySort((x, y) -> -y, name, salaries) AS name2,
arraySort((x, y) -> -y, hiredate, salaries) AS hiredate2,
arraySort((x) -> -x, salaries) AS salaries2,
arrayCumSum(arraySort((x) -> -x, salaries)) AS sum,
arrayEnumerate(arraySort((x) -> -x, salaries)) AS rank
ORDER BY departid ASC;
┌─deptname─┬─name2──┬─departid─┬──hiredate2─┬─salaries2─┬─rank─┬───sum─┐
│ 研发部 │ 石昊 │ 1 │ 2023-11-17 │ 5000 │ 1 │ 5000 │
│ 研发部 │ 唐三 │ 1 │ 2023-06-09 │ 2450 │ 2 │ 7450 │
│ 研发部 │ 小舞 │ 1 │ 2023-01-23 │ 2300 │ 3 │ 9750 │
│ 销售部 │ 徐欣 │ 2 │ 2023-04-19 │ 3000 │ 1 │ 3000 │
│ 销售部 │ 王林 │ 2 │ 2023-12-02 │ 3000 │ 2 │ 6000 │
│ 销售部 │ 秦羽 │ 2 │ 2023-04-02 │ 2975 │ 3 │ 8975 │
│ 销售部 │ 萧炎 │ 2 │ 2023-12-17 │ 2800 │ 4 │ 11775 │
│ 销售部 │ 龙昊晨 │ 2 │ 2023-05-23 │ 1100 │ 5 │ 12875 │
│ 营销部 │ 罗峰 │ 3 │ 2023-05-01 │ 2850 │ 1 │ 2850 │
│ 营销部 │ 李慕婉 │ 3 │ 2023-02-22 │ 2250 │ 2 │ 5100 │
│ 营销部 │ 姜立 │ 3 │ 2023-09-28 │ 2250 │ 3 │ 7350 │
│ 营销部 │ 美杜莎 │ 3 │ 2023-12-03 │ 1950 │ 4 │ 9300 │
│ 营销部 │ 柳神 │ 3 │ 2023-02-20 │ 1600 │ 5 │ 10900 │
│ 营销部 │ 云韵 │ 3 │ 2023-09-08 │ 1500 │ 6 │ 12400 │
└──────────┴────────┴──────────┴────────────┴───────────┴──────┴───────┘基本上已经很完美地还原了开窗函数的功能显然,这种方式比开窗要麻烦许多。
4. 公共测试数据
第三方公开的电商网站行为事件数据,可直接点击下载。
先创建表结构再导入数据。
:) CREATE TABLE t_events
(
date DateTime,
product_id String,
user_id Int64,
event String,
extra_data String
) ENGINE = MergeTree()
ORDER BY date;
:) clickhouse-client --query 'INSERT INTO default.t_events FORMAT CSV' < events_10K.csv
┌────────────────date─┬─product_id───────────────────────────┬─user_id─┬─event─────────────────┬─extra_data──────────────────────────┐
1. │ 2017-01-01 02:13:08 │ 63ad4714-1aaa-11eb-b7e5-acde48001122 │ 488942 │ add_item_to_cart │ {"city": "Austin"} │
2. │ 2017-01-01 04:26:04 │ 6bb04e28-1aaa-11eb-9f1f-acde48001122 │ 893470 │ add_item_to_cart │ {"city": "Lincoln"} │
3. │ 2017-01-01 08:45:35 │ 6a2326c2-1aaa-11eb-b004-acde48001122 │ 747132 │ remove_item_from_cart │ {"city": "Sacramento"} │
4. │ 2017-01-01 12:21:35 │ 6b4236f6-1aaa-11eb-aa39-acde48001122 │ 364184 │ buy │ {"city": "Concord", "price": 0.85} │
5. │ 2017-01-01 12:54:25 │ 68b7e6d8-1aaa-11eb-baaf-acde48001122 │ 246801 │ view │ {"city": "Columbus"} │
6. │ 2017-01-01 15:40:57 │ 67f9cc70-1aaa-11eb-86b0-acde48001122 │ 222559 │ add_item_to_cart │ {"city": "Madison"} │
7. │ 2017-01-01 18:31:42 │ 6c2f8dde-1aaa-11eb-9467-acde48001122 │ 861135 │ buy │ {"city": "Madison", "price": 11.95} │
8. │ 2017-01-01 20:09:47 │ 69cec514-1aaa-11eb-a08d-acde48001122 │ 849166 │ remove_item_from_cart │ {"city": "Sacramento"} │
9. │ 2017-01-01 20:57:25 │ 68330ca6-1aaa-11eb-8ebb-acde48001122 │ 318921 │ view │ {"city": "Boston"} │
10. │ 2017-01-01 21:00:14 │ 6a9898f8-1aaa-11eb-a100-acde48001122 │ 67312 │ remove_item_from_cart │ {"city": "Tallahassee"} │
│ │ │ │ │ │
... │ ...... │ ...... │ ...... │ ...... │ ...... │
│ │ │ │ │ │
9999. │ 2020-11-03 14:48:12 │ 6c34ceac-1aaa-11eb-9c26-acde48001122 │ 440425 │ remove_item_from_cart │ {"city": "Olympia"} │
10000. │ 2020-11-03 16:12:58 │ 6866a9ee-1aaa-11eb-93bb-acde48001122 │ 596081 │ search │ {"city": "Austin", "term": "Fully"} │
└─────────────────────┴──────────────────────────────────────┴─────────┴───────────────────────┴─────────────────────────────────────┘4.1 按天统计购买次数、累加购买次数、销售额,以及累加销售额
:) SELECT toDate(date) AS day,
COUNT() AS count,
SUM(count) OVER win AS totalbuy,
ROUND(AVG(count) OVER win, 2) AS averagebuy,
SUM(JSONExtractFloat(extra_data, 'price')) AS sell,
SUM(sell) OVER win AS totalsell
FROM t_events
WHERE event = 'buy'
GROUP BY day
WINDOW win AS (ORDER BY day ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
LIMIT 10;
┌────────day─┬─count─┬─totalbuy─┬─averagebuy─┬──sell─┬─totalsell─┐
│ 2017-01-01 │ 2 │ 2 │ 2 │ 12.8 │ 12.8 │
│ 2017-01-03 │ 1 │ 3 │ 1.5 │ 11.65 │ 24.45 │
│ 2017-01-04 │ 2 │ 5 │ 1.67 │ 44.16 │ 68.61 │
│ 2017-01-06 │ 1 │ 6 │ 1.5 │ 33.75 │ 102.36 │
│ 2017-01-07 │ 1 │ 7 │ 1.4 │ 11.25 │ 113.61 │
│ 2017-01-08 │ 3 │ 10 │ 1.67 │ 23.02 │ 136.63 │
│ 2017-01-10 │ 1 │ 11 │ 1.57 │ 0.83 │ 137.46 │
│ 2017-01-12 │ 2 │ 13 │ 1.62 │ 45.5 │ 182.96 │
│ 2017-01-13 │ 1 │ 14 │ 1.56 │ 11.65 │ 194.61 │
│ 2017-01-14 │ 1 │ 15 │ 1.5 │ 0.85 │ 195.46 │
└────────────┴───────┴──────────┴────────────┴───────┴───────────┘4.2 计算30天的移动平均销售额,以及过去30天的销售额总和
:) SELECT toDate(date) AS day,
SUM(JSONExtractFloat(extra_data, 'price')) AS daysell,
SUM(daysell) OVER win AS totalsell,
ROUND(AVG(daysell) OVER win, 2) AS avgsell
FROM t_events
WHERE event = 'buy' AND date BETWEEN '2017-01-01 00:00:00' AND '2017-02-01 23:59:59'
GROUP BY day
WINDOW win AS (ORDER BY day ASC ROWS BETWEEN 30 PRECEDING AND CURRENT ROW)
LIMIT 30;
┌────────day─┬────────────daysell─┬──────────totalsell─┬─avgsell─┐
│ 2017-01-01 │ 12.799999999999999 │ 12.799999999999999 │ 12.8 │
│ 2017-01-03 │ 11.65 │ 24.45 │ 12.22 │
│ 2017-01-04 │ 44.16 │ 68.61 │ 22.87 │
│ 2017-01-06 │ 33.75 │ 102.36 │ 25.59 │
│ 2017-01-07 │ 11.25 │ 113.61 │ 22.72 │
│ 2017-01-08 │ 23.02 │ 136.63 │ 22.77 │
│ 2017-01-10 │ 0.83 │ 137.46 │ 19.64 │
│ 2017-01-12 │ 45.5 │ 182.96 │ 22.87 │
│ 2017-01-13 │ 11.65 │ 194.61 │ 21.62 │
│ 2017-01-14 │ 0.85 │ 195.46 │ 19.55 │
│ 2017-01-15 │ 22.1 │ 217.56 │ 19.78 │
│ 2017-01-16 │ 22.08 │ 239.64 │ 19.97 │
│ 2017-01-17 │ 33.29 │ 272.93 │ 20.99 │
│ 2017-01-18 │ 78.21000000000001 │ 351.14 │ 25.08 │
│ 2017-01-20 │ 275.29 │ 626.4300000000001 │ 41.76 │
│ 2017-01-22 │ 737.75 │ 1364.18 │ 85.26 │
│ 2017-01-24 │ 22.55 │ 1386.73 │ 81.57 │
│ 2017-01-25 │ 56.2 │ 1442.93 │ 80.16 │
│ 2017-01-26 │ 99.75 │ 1542.68 │ 81.19 │
│ 2017-01-27 │ 440 │ 1982.68 │ 99.13 │
│ 2017-01-28 │ 110.95 │ 2093.63 │ 99.7 │
│ 2017-01-29 │ 66.95 │ 2160.58 │ 98.21 │
│ 2017-01-30 │ 22.740000000000002 │ 2183.3199999999997 │ 94.93 │
│ 2017-01-31 │ 0.42 │ 2183.74 │ 90.99 │
│ 2017-02-01 │ 66.51 │ 2250.25 │ 90.01 │
└────────────┴────────────────────┴────────────────────┴─────────┘4.3 计算每月的销售额及当月所属年的总销售额
:) SELECT
toYYYYMM(date) month,
toStartOfMonth(date) start_month_date,
ROUND(SUM(JSONExtractFloat(extra_data, 'price')), 2) AS month_sell,
ROUND(SUM(month_sell) OVER (PARTITION BY toYear(start_month_date)), 2) AS year_sell
FROM t_events
WHERE event = 'buy'
GROUP BY month, start_month_date
ORDER BY month;
┌──month─┬─start_month_date─┬─month_sell─┬─year_sell─┐
│ 201701 │ 2017-01-01 │ 2183.74 │ 14549.83 │
│ 201702 │ 2017-02-01 │ 686.96 │ 14549.83 │
│ 201703 │ 2017-03-01 │ 1368.12 │ 14549.83 │
│ 201704 │ 2017-04-01 │ 943.36 │ 14549.83 │
│ 201705 │ 2017-05-01 │ 1340.15 │ 14549.83 │
│ 201706 │ 2017-06-01 │ 1483.65 │ 14549.83 │
│ 201707 │ 2017-07-01 │ 866.9 │ 14549.83 │
│ 201708 │ 2017-08-01 │ 1186.99 │ 14549.83 │
│ 201709 │ 2017-09-01 │ 1418.29 │ 14549.83 │
│ 201710 │ 2017-10-01 │ 1039.54 │ 14549.83 │
│ 201711 │ 2017-11-01 │ 955.27 │ 14549.83 │
│ 201712 │ 2017-12-01 │ 1076.86 │ 14549.83 │
└────────┴──────────────────┴────────────┴───────────┘
┌──month─┬─start_month_date─┬─month_sell─┬─year_sell─┐
│ 201801 │ 2018-01-01 │ 1072.54 │ 15934.95 │
│ 201802 │ 2018-02-01 │ 1184.51 │ 15934.95 │
│ 201803 │ 2018-03-01 │ 1687.69 │ 15934.95 │
│ 201804 │ 2018-04-01 │ 886.7 │ 15934.95 │
│ 201805 │ 2018-05-01 │ 987.27 │ 15934.95 │
│ 201806 │ 2018-06-01 │ 684.04 │ 15934.95 │
│ 201807 │ 2018-07-01 │ 1150.86 │ 15934.95 │
│ 201808 │ 2018-08-01 │ 2166.78 │ 15934.95 │
│ 201809 │ 2018-09-01 │ 2000.5 │ 15934.95 │
│ 201810 │ 2018-10-01 │ 1289.49 │ 15934.95 │
│ 201811 │ 2018-11-01 │ 1268.47 │ 15934.95 │
│ 201812 │ 2018-12-01 │ 1556.1 │ 15934.95 │
└────────┴──────────────────┴────────────┴───────────┘
┌──month─┬─start_month_date─┬─month_sell─┬─year_sell─┐
│ 201901 │ 2019-01-01 │ 1167.67 │ 17420.09 │
│ 201902 │ 2019-02-01 │ 1031.11 │ 17420.09 │
│ 201903 │ 2019-03-01 │ 884.26 │ 17420.09 │
│ 201904 │ 2019-04-01 │ 1100.37 │ 17420.09 │
│ 201905 │ 2019-05-01 │ 1198.78 │ 17420.09 │
│ 201906 │ 2019-06-01 │ 2675.85 │ 17420.09 │
│ 201907 │ 2019-07-01 │ 1256.87 │ 17420.09 │
│ 201908 │ 2019-08-01 │ 2336.72 │ 17420.09 │
│ 201909 │ 2019-09-01 │ 1247.26 │ 17420.09 │
│ 201910 │ 2019-10-01 │ 1308.28 │ 17420.09 │
│ 201911 │ 2019-11-01 │ 819.23 │ 17420.09 │
│ 201912 │ 2019-12-01 │ 2393.69 │ 17420.09 │
└────────┴──────────────────┴────────────┴───────────┘
┌──month─┬─start_month_date─┬─month_sell─┬─year_sell─┐
│ 202001 │ 2020-01-01 │ 1242.35 │ 15783.71 │
│ 202002 │ 2020-02-01 │ 1934.56 │ 15783.71 │
│ 202003 │ 2020-03-01 │ 1483.58 │ 15783.71 │
│ 202004 │ 2020-04-01 │ 1949.68 │ 15783.71 │
│ 202005 │ 2020-05-01 │ 1712.64 │ 15783.71 │
│ 202006 │ 2020-06-01 │ 1168.45 │ 15783.71 │
│ 202007 │ 2020-07-01 │ 1579.37 │ 15783.71 │
│ 202008 │ 2020-08-01 │ 1693.54 │ 15783.71 │
│ 202009 │ 2020-09-01 │ 1797.41 │ 15783.71 │
│ 202010 │ 2020-10-01 │ 1097.88 │ 15783.71 │
│ 202011 │ 2020-11-01 │ 124.25 │ 15783.71 │
└────────┴──────────────────┴────────────┴───────────┘4.4 计算过去1个小时的总销售额
:) SELECT
date,
COUNT() OVER win AS past_hour,
SUM(JSONExtractFloat(extra_data, 'price')) OVER win AS sell
FROM t_events
WHERE event = 'buy'
WINDOW win AS (ORDER BY date ASC RANGE BETWEEN 3600 PRECEDING AND CURRENT ROW)
ORDER BY date ASC
LIMIT 10;
┌────────────────date─┬─past_hour─┬──sell─┐
│ 2017-01-01 12:21:35 │ 1 │ 0.85 │
│ 2017-01-01 18:31:42 │ 1 │ 11.95 │
│ 2017-01-03 05:43:24 │ 1 │ 11.65 │
│ 2017-01-04 18:29:00 │ 1 │ 22.08 │
│ 2017-01-04 23:13:40 │ 1 │ 22.08 │
│ 2017-01-06 18:48:49 │ 1 │ 33.75 │
│ 2017-01-07 16:23:37 │ 1 │ 11.25 │
│ 2017-01-08 03:03:06 │ 1 │ 22.08 │
│ 2017-01-08 03:14:07 │ 2 │ 22.47 │
│ 2017-01-08 15:37:50 │ 1 │ 0.55 │
└─────────────────────┴───────────┴───────┘时间窗口函数
时间窗口函数用于对时间序列数据进行分析和聚合操作,实现滑动窗口计算。
只是官方提供的文档不够丰富,而且也没有实际案例可供学习,只有干巴巴的几条SQL查询。
tumble
tumble是连续的、不重叠的固定大小时间窗口,它返回一个包含上界和不包含下界的元组[StartTime, EndTime)。
-- tumble语法
tumble(time_attr, interval [, timezone])其中interval包括:Year、Quarter、Month、Week、Day、Hour、Minute和Second,在查询中只需要统一加上前缀toInterval就行了,比如toIntervalWeek(1)。
:) SELECT tumble(now(), toIntervalWeek('1'), 'Asia/Shanghai') AS tw;
┌─tw──────────────────────────┐
│ ('2024-01-01','2024-01-08') │
└─────────────────────────────┘和tumble配套的还有两个函数:tumbleStart和tumbleEnd。
hop
hop是固定大小的时间窗口,并按照固定的滑动间隔滑动。
当滑动间隔小于窗口大小时,滑动窗口间会存在重叠,此时一个数据可能存在于多个窗口。
-- hop语法
hop(time_attr, hop_interval, window_interval [, timezone])它和tumble类似,也返回一个包含上界和不包含下界的元组[StartTime, EndTime)。
hop_interval是滑动间隔,而window_interval为窗口大小。
:) SELECT hop(now(), INTERVAL '1' SECOND, INTERVAL '2' SECOND, 'Asia/Shanghai') AS tw;
┌─tw────────────────────────────────────────────┐
│ ('2024-01-01 13:08:11','2024-01-01 13:08:13') │
└───────────────────────────────────────────────┘和hop配套的也有两个函数:hopStart和hopEnd。
感谢支持
更多内容,请移步《超级个体》。