
HDFS三大Node
原创大约 2 分钟
Hadoop中虽有五大组件,但整体上分为两派,分别用于HDFS和YARN的管理。
官方给出的HDFS架构图。
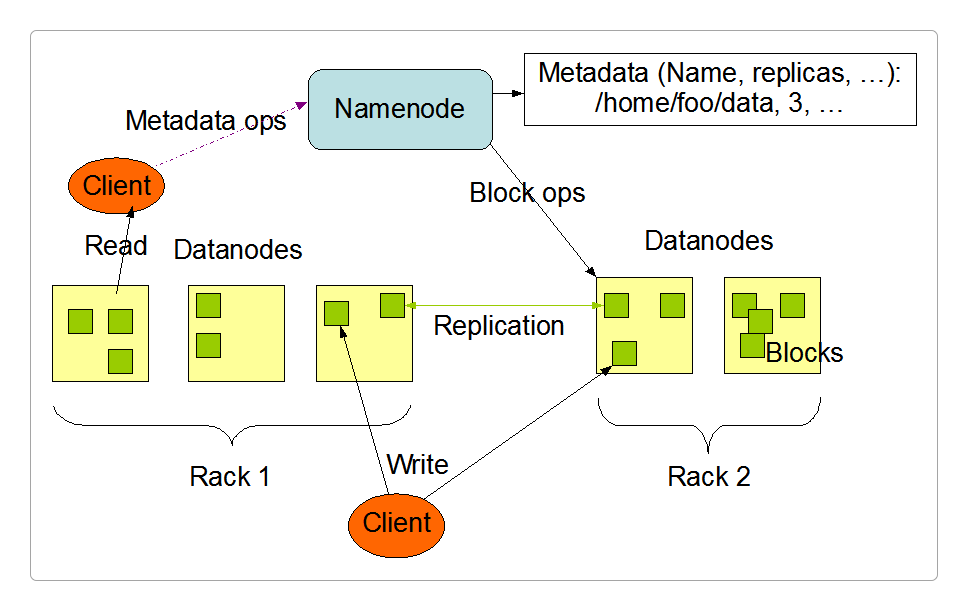
其中NameNode、SecondaryNameNode和DataNode的作品分别如下。
NameNode:HDFS的核心管理节点,存放各种元数据,负责响应和处理客户端的请求。SecondaryNameNode:相当于MySQL的从节点,它不记录任何实时的数据变化,但会定期地保存NameNode中元数据的快照,也作为备用NameNode。DataNode:HDFS的工作节点,真正保存数据的地方,接受客户端和NameNode的调度,读取、存储、复制并检索数据块(BLOCK)。
HDFS的整体实现思路也可以用一张图来说明。
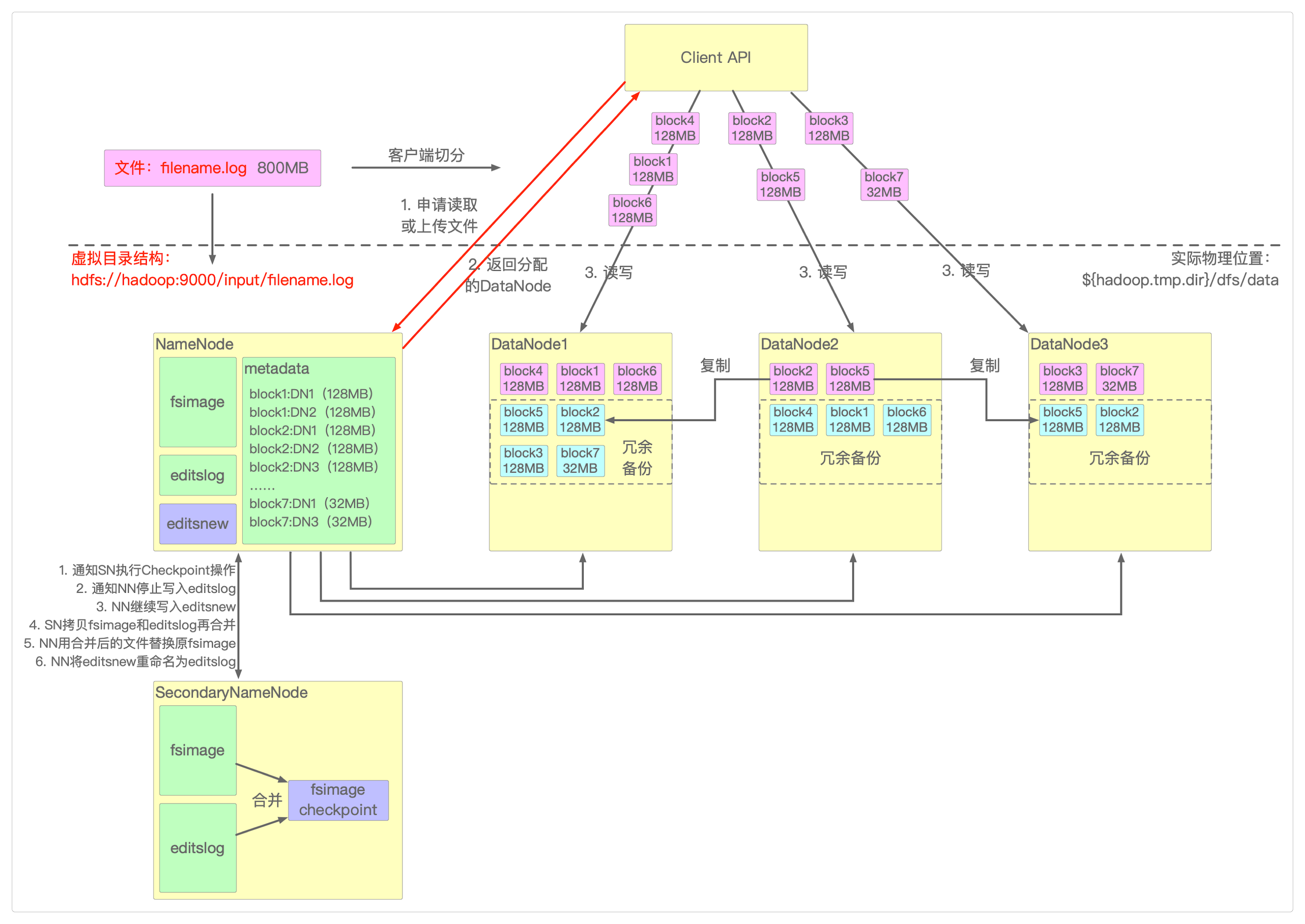
HDFS通过分布式集群来存储文件。
提供了一套虚拟的目录结构来保存实际的文件。
为客户端提供了一种便捷的访问方式。
客户端上传文件时会首先记录
元数据(也就是数据的操作日志)到内存的editslog,然后再为客户端分配可供操作的DataNode。当
editslog满,NameNode会通知SecondaryNameNode将内容合并到fsimage磁盘文件。文件被保存到HDFS集群的时候被切分成一个个的
BLOCK。BLOCK按固定大小切分(Hadoop2的每一个BLOCK的默认大小都是128MB)。如果文件小于
128MB则以BLOCK实际大小为准。
每一个
BLOCK在集群中都会被存储多份副本,既能提高数据可靠性,也能提高访问吞吐量。HDFS保存的文件与
BLOCK之间的映射关系都由NameNode管理。
感谢支持
更多内容,请移步《超级个体》。