
MapReduce计算
什么是MapReduce
如果说HDFS是用来存储数据的,那么MapReduce就是用来计算数据的。
MapReduce是Google提出的一种分布式计算模型,它由两个阶段组成。
Map阶段:将待计算的文件分解成若干个更小的子文件,每个子文件都会生成一个对应且独立的任务来处理数据。Reduce阶段:将多个任务产生的计算结果进行汇总和合并。
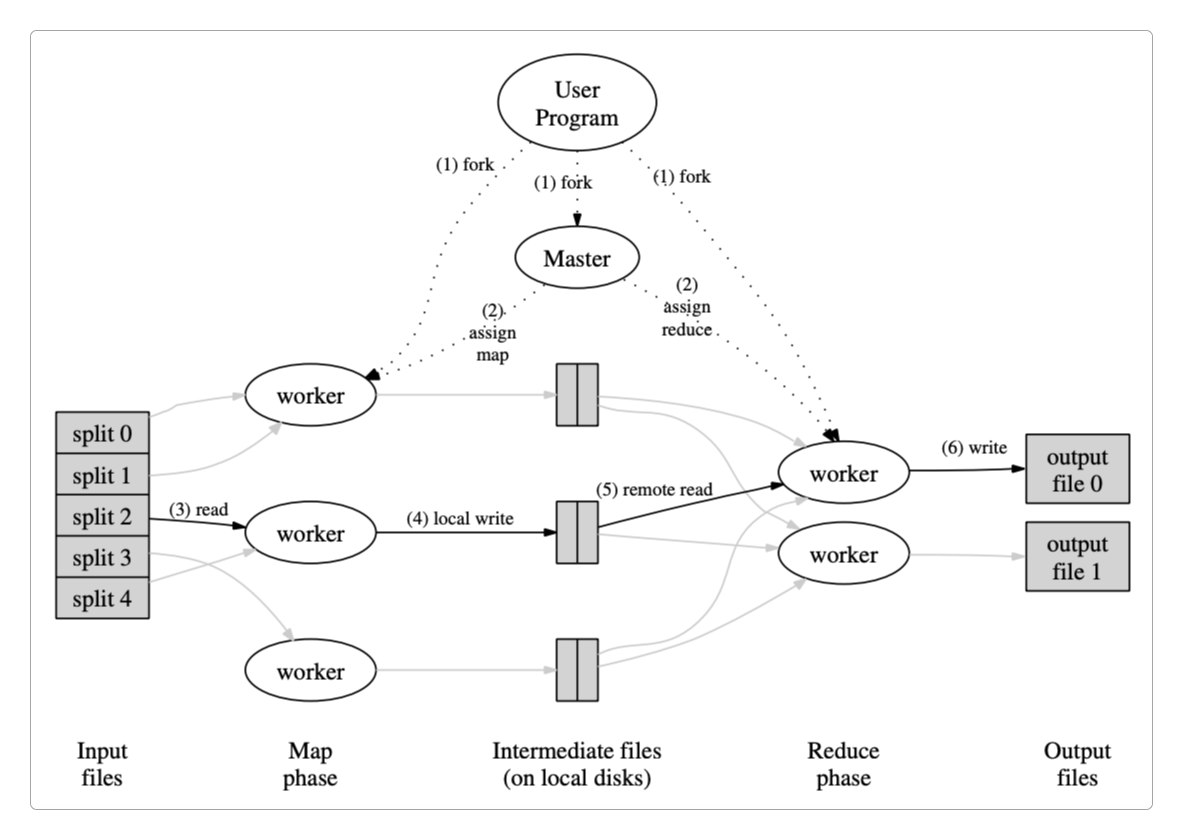
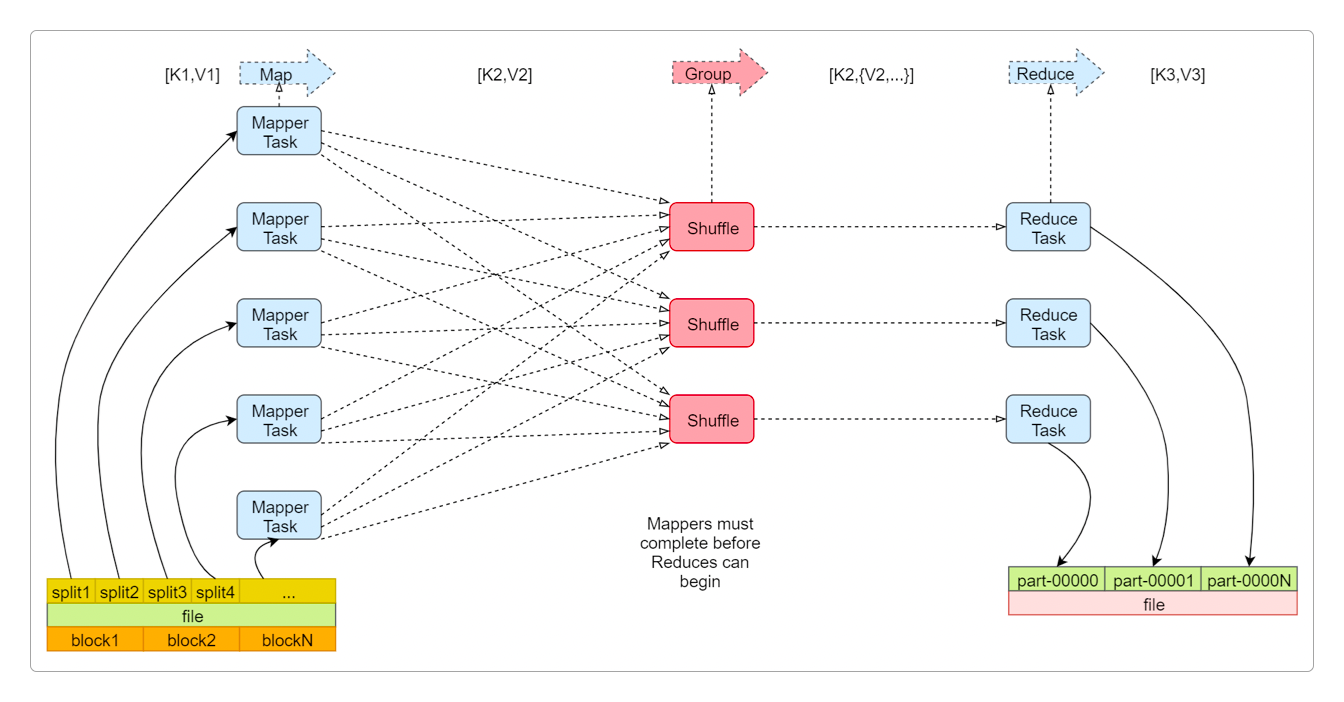
从上图中可以清晰地看到MapReduce的工作流程。
file文件被HDFS划分成多个Block存储在DataNode中,而它的内容同样被划分成多个split。在
Map阶段,每个split都对应一个Mapper Task,不同的Mapper Task中的相同Partition(分区)中的数据被分到相同的Shuffle(Shuffle & Sorting of MapReduce Task)中。在
Reduce阶段,每个Shuffle都会产生一个对应的Reduce Task,通过这些Reduce Task将计算结果汇总到结果文件。
MapReduce最典型的应用就是单词统计,它相当于大数据开发中的Hello World。
执行步骤和结果
例如,有下面的句子。
hello hadoop
hello spark
hello flink
hello world第一步(Input)
Hadoop会把输入数据划分成很多个
split。默认情况下,每个HDFS的
Block都对应一个split,而每个split都对应一个Map Task,它会被解析成多个对应的键值对<k1,v1>。默认情况下,每一行数据,都会被解析成一个
<k1,v1>。这里k1指的是每一行的起始偏移量,而v1则代表那一行的内容。
所以,经过split处理后,数据就变成了这样。
<0,hello hadoop>
<12,hello spark>
<24,hello flink>
<36,hello world>第二步(Map阶段第一步)
Hadoop调用Mapper类中的map()函数,每个输入的
<k1,v1>,都可以输出多个<k2,v2>。这里的每个
k2都是v1分割之后产生的若干个元素,而v2则通常是一个固定数字1。整个Hadoop计算进入
Map阶段。
所以,前一步的结果通过map()函数转换之后,就变成了这样。
# <0,hello hadoop> k1=0, v1=hello hadoop
<hello,1> k2=hello, v2=1
<hadoop,1> k2=hadoop, v2=1
# <12,hello spark> 同上
<hello,1>
<spark,1>
# <24,hello flink> 同上
<hello,1>
<flink,1>
# <36,hello world> 同上
<hello,1>
<world,1>第三步(Map阶段第二步)
接下来,Hadoop会对第二步中的结果<k2,v2>进行分区,不同分区的<k2,v2>由不同的的Reduce Task处理,默认只有1个分区。
所以,前一步的结果会变成这样。
<hello,1>
<hadoop,1>
<hello,1>
<spark,1>
<hello,1>
<flink,1>
<hello,1>
<world,1>在此阶段,Hadoop可以执行一个可选的Combiner操作,先执行聚合计算(求和可以,但求平均值不行)。
例如,先计算每个Map阶段局部的结果,这样还能减少数据传输大小,节约带宽。
<hello,4>
<hadoop,1>
<spark,1>
<flink,1>
<world,1>第四步(Map阶段第三步)
所以,前一步的结果会变成这样。
<flink,{1}>
<hadoop,{1}>
<hello,{1,1,1,1}>
<spark,{1}>
<world,{1}>第五步(Reduce阶段第一步)
Hadoop将多个Map Task的输出按照不同的分区,拷贝到不同的Reduce节点,这一过程称为Shuffle。
所以,前一步的结果会变成这样。
<flink,{1}>
<hadoop,{1}>
<hello,{1,1,1,1}>
<spark,{1}>
<world,{1}>第六步(Reduce阶段第二步)
Hadoop对Reduce节点收到的相同分区的<k2,v2>执行全局的合并、排序和分组。
所以,前一步的结果会变成这样。
<flink,{1}>
<hadoop,{1}>
<hello,{1,1,1,1}>
<spark,{1}>
<world,{1}>第七步(Reduce阶段第三步)
Hadoop调用
Reducer类中的reduce()方法,将输入的<k2,v2>转换成<k3,v3>。这里的每个
k3就是前面的k2,而v3则是v2中所有数值之和。
所以,最后的结果会变成这样。
<flink,1>
<hadoop,1>
<hello,4>
<spark,1>
<world,1>第八步(Output)
结果会这样保存。
flink 1
hadoop 1
hello 4
spark 1
world 1整个计算任务结束。
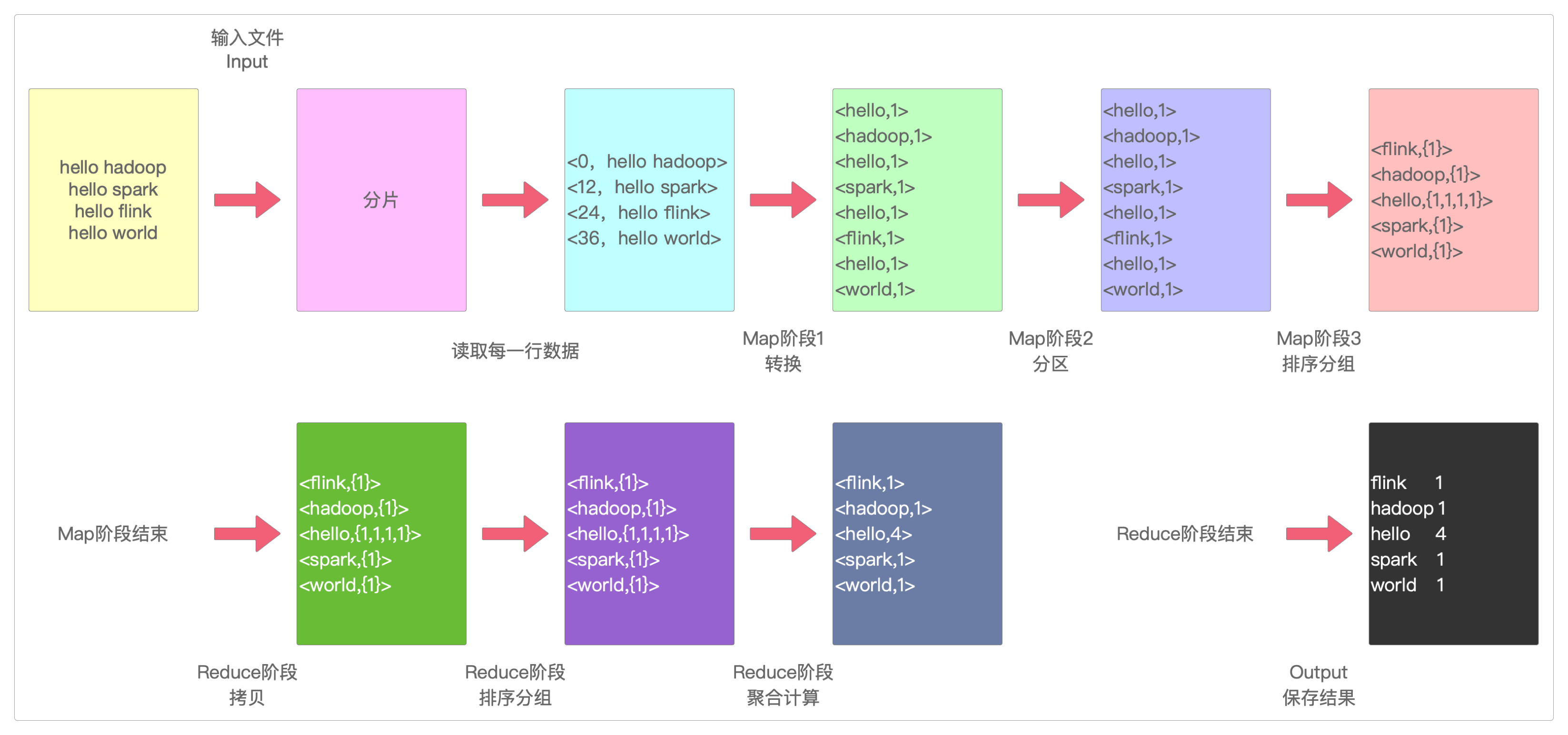
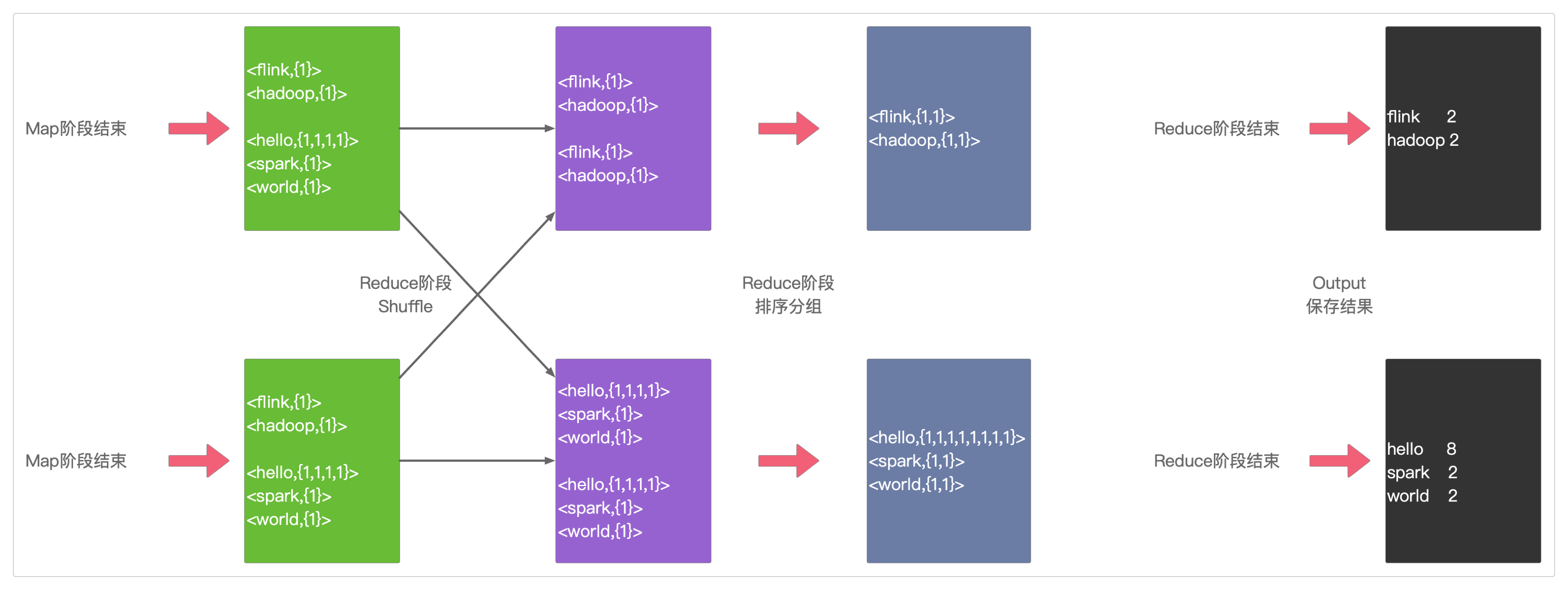
图解
下面是整个任务执行过程的图解。
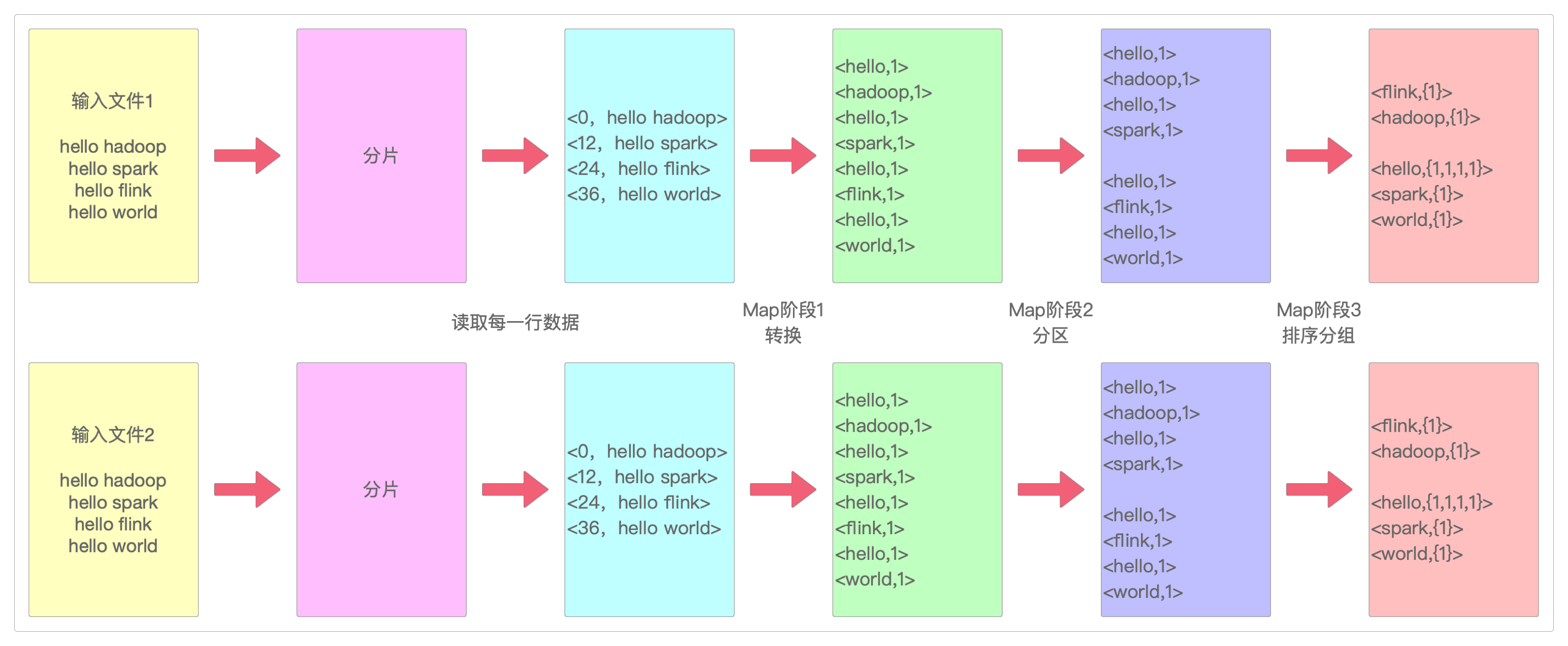
上面是单一文件的执行,如果是两份文件,而且加入分区和Shuffle的过程,那就是这样的。
代码实现
package com.itechthink.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数
*
* 原始文件hello.txt内容:
* hello hadoop
* hello spark
* hello flink
* hello world
*
* 最终需要的结果:
* hello 4
* hadoop 1
* flink 1
* spark 1
* world 1
*/
public class WordCountJob {
/**
* Map阶段
* <k1,v1> = <offset, "hello hadoop">
* <k2,v2> = <hello, 1>
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
// 输出k1,v1的值
// System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
// logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
// k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word : words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把<k2,v2>写出去
context.write(k2, v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {
// sum保存v2s的和
long sum = 0L;
// 对v2s中的数据进行累加求和
for (LongWritable v2 : v2s) {
// 输出k2,v2的值
// System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
// logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
// 输出k3,v3的值
// System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3, v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try {
if (args.length != 2) {
// 如果传递的参数不够,程序直接退出
System.exit(0);
}
// 指定Job需要的配置参数
Configuration conf = new Configuration();
// 创建一个Job
Job job = Job.getInstance(conf);
// 这一行必须设置,否则在集群中执行时找不到WordCountJob类
job.setJarByClass(WordCountJob.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}感谢支持
更多内容,请移步《超级个体》。