
几个优化问题
小文件问题
Hadoop提供了两种容器专门用来解决小文件问题:SequenceFile和MapFile。
SequenceFile
SequenceFile是一种二进制文件,它直接将<key, value>键值对序列化到文件中。通过它对小文件进行合并,将文件名作为key,文件内容作为value序列化到合并的大文件中(但合并后的文件需要遍历才能查看每个小文件的内容)。
引入依赖。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.0</version>
</dependency>下面是用代码实现SequenceFile对文件的读取和写入。
package com.itechthink.mr;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
/**
* SequenceFile小文件写入和读取
*
*/
public class SmallFileWithSequenceFile {
public static void main(String[] args) throws Exception {
// 生成SequenceFile文件
write("/home/work/smallFile", "/seqFile");
// 读取SequenceFile文件
read("/seqFile");
}
/**
* 生成SequenceFile文件
*
*/
private static void write(String inputDir, String outputFile) throws Exception {
// 创建一个配置对象
Configuration conf = new Configuration();
// 指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://hadoop:9000");
// 获取操作HDFD的对象
FileSystem fileSystem = FileSystem.get(conf);
// 删除HDFS上的输出文件
fileSystem.delete(new Path(outputFile), true);
/*
* 构造opts数组,有三个元素
* 第一个是输出路径【文件】
* 第二个是key的类型
* 第三个是value的类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
SequenceFile.Writer.file(new Path(outputFile)),
SequenceFile.Writer.keyClass(Text.class),
SequenceFile.Writer.valueClass(Text.class)
};
// 创建writer实例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);
// 指定需要压缩的文件的目录
File inputDirPath = new File(inputDir);
if (inputDirPath.isDirectory()) {
// 获取目录中的文件
File[] files = inputDirPath.listFiles();
// 迭代文件
assert files != null;
for (File file : files) {
// 获取文件的全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
// 获取文件名
String fileName = file.getName();
Text key = new Text(fileName);
Text value = new Text(content);
// 向SequenceFile中写入数据
writer.append(key, value);
}
}
writer.close();
}
/**
* 读取SequenceFile文件
*
*/
private static void read(String inputFile) throws Exception {
// 创建一个配置对象
Configuration conf = new Configuration();
// 指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://hadoop:9000");
// 创建阅读器
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(new Path(inputFile)));
Text key = new Text();
Text value = new Text();
// 循环读取数据
while (reader.next(key, value)) {
// 输出文件名称
System.out.print("文件名:" + key.toString() + ",");
// 输出文件内容
System.out.println("文件内容:" + value.toString() + "");
}
reader.close();
}
}MapFile
MapFile就是排序后的SequenceFile,它由index和data组成,index存储索引,而data存储数据。
index作为文件的数据索引,记录了每个Record的key值,以及该Record在文件中的偏移位置。当MapFile被访问时,index会被加载到内存,通过映射关系就能马上定位到指定Record所在文件的位置。
引入依赖。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.0</version>
</dependency>下面是用代码实现MapFile对文件的读取和写入。
package com.itechthink.mr;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
/**
* MapFile小文件写入和读取
*
*/
public class SmallFileWithMapFile {
public static void main(String[] args) throws Exception {
// 生成MapFile文件
write("/home/work/smallFile", "/mapFile");
// 读取MapFile文件
read("/mapFile");
}
/**
* 生成MapFile文件
*
*/
private static void write(String inputDir, String outputDir) throws Exception {
// 创建一个配置对象
Configuration conf = new Configuration();
// 指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://hadoop:9000");
// 获取操作HDFD的对象
FileSystem fileSystem = FileSystem.get(conf);
// 删除HDFS上的输出文件
fileSystem.delete(new Path(outputDir), true);
/*
* 构造opts数组,有两个元素
* 第一个是key的类型
* 第二个是value的类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
MapFile.Writer.keyClass(Text.class),
MapFile.Writer.valueClass(Text.class)
};
// 创建writer实例
MapFile.Writer writer = new MapFile.Writer(conf, new Path(outputDir), opts);
// 指定需要压缩的文件的目录
File inputDirPath = new File(inputDir);
if (inputDirPath.isDirectory()) {
// 获取目录中的文件
File[] files = inputDirPath.listFiles();
// 对获取到的文件进行排序
assert files != null;
List<File> fileList = Arrays.asList(files);
fileList.sort(new Comparator<File>() {
@Override
public int compare(File f1, File f2) {
return f1.getName().compareTo(f2.getName());
}
});
// 迭代文件
for (File file : fileList) {
// 获取文件的全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
// 获取文件名
String fileName = file.getName();
Text key = new Text(fileName);
Text value = new Text(content);
// 向SequenceFile中写入数据
writer.append(key, value);
}
}
writer.close();
}
/**
* 读取MapFile文件
*
*/
private static void read(String inputDir) throws Exception {
// 创建一个配置对象
Configuration conf = new Configuration();
// 指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://hadoop:9000");
// 创建阅读器
MapFile.Reader reader = new MapFile.Reader(new Path(inputDir), conf);
Text key = new Text();
Text value = new Text();
// 循环读取数据
while (reader.next(key, value)) {
// 输出文件名称
System.out.print("文件名:" + key.toString() + ",");
// 输出文件内容
System.out.println("文件内容:" + value.toString() + "");
}
reader.close();
}
}实际应用
在实际的计算任务中读取SequenceFile。
package com.itechthink.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 在计算任务中读取SequenceFile文件
*
*/
public class WordCountJobBySequenceFile {
/**
* Map阶段
*
*/
public static class MyMapper extends Mapper<Text, Text, Text, LongWritable> {
/*
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*/
@Override
protected void map(Text k1, Text v1, Context context) throws IOException, InterruptedException {
// 输出k1,v1的值
System.out.println("<k1,v1>=<" + k1.toString() + "," + v1.toString() + ">");
// logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
// k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word : words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把<k2,v2>写出去
context.write(k2, v2);
}
}
}
/**
* Reduce阶段
*
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/*
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
*
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {
// sum保存v2s的和
long sum = 0L;
// 对v2s中的数据进行累加求和
for (LongWritable v2 : v2s) {
// 输出k2,v2的值
// System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
// logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
// 输出k3,v3的值
// System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3, v3);
}
}
/**
* 组装Job = Map + Reduce
*
*/
public static void main(String[] args) {
try {
if (args.length != 2) {
// 如果传递的参数不够,程序直接退出
System.exit(0);
}
// 指定Job需要的配置参数
Configuration conf = new Configuration();
// 创建Job
Job job = Job.getInstance(conf);
// 这一行必须设置,否则在集群中执行时找不到WordCountJob类
job.setJarByClass(WordCountJobSeq.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
/*
* 设置输入数据处理类为SequenceFile
*
*/
job.setInputFormatClass(SequenceFileInputFormat.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}数据倾斜问题
在MapReduce的执行过程中,它的效率是和Block的数量相关的。
所谓数据倾斜,指的是待处理的数据或任务都集中在了某个节点,导致该节点负荷较大,而其他节点却较为空闲的现象。
有时这种问题无法通过简单地增加任务并行度的方式来解决。
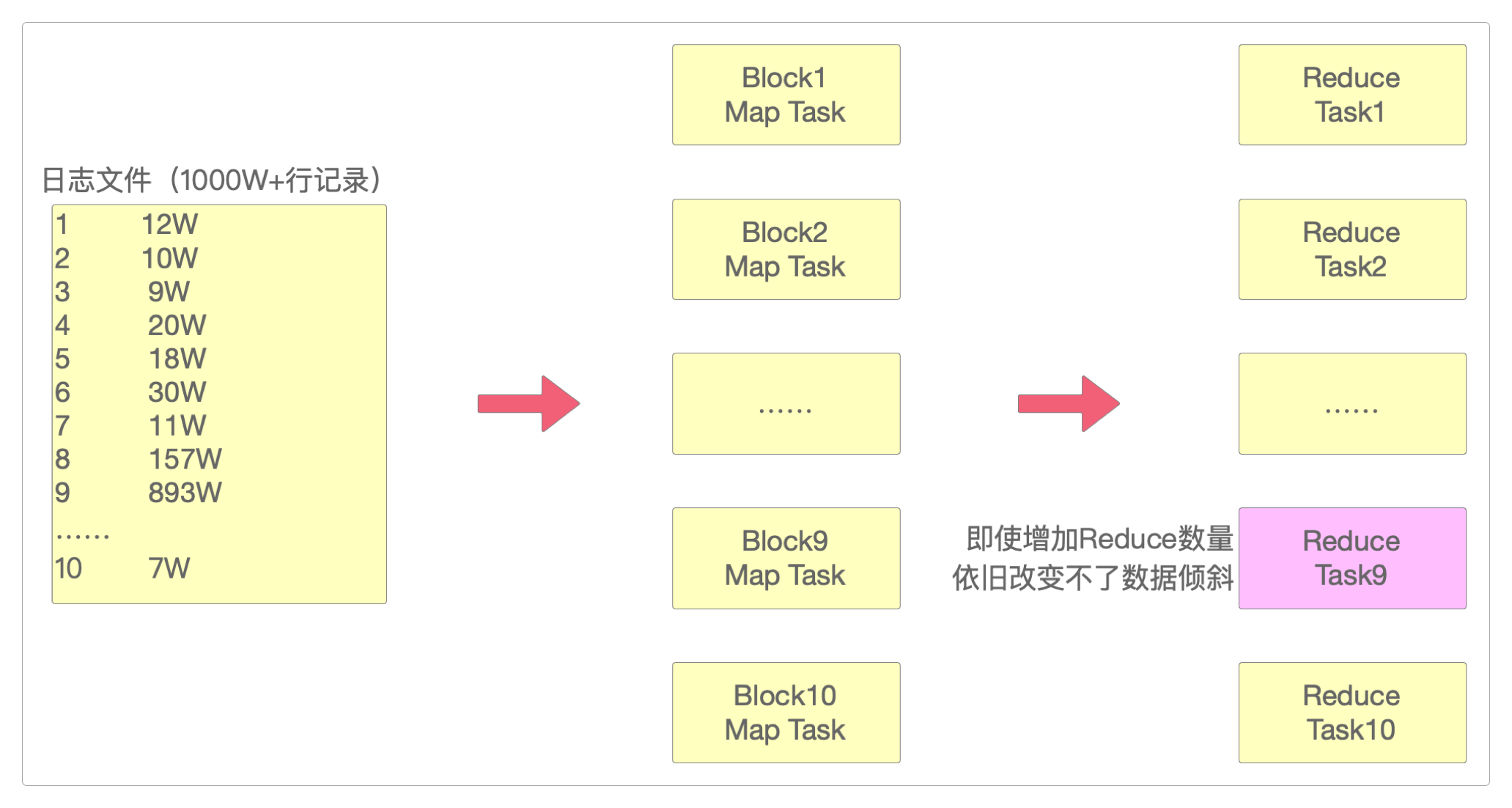
在上面的图中,ID从1到10一共记录了1000多万条记录,但其中有893万条记录是数值为9的ID记录的。
如果按照增加并行度的方式,即使增加到10个Reduce,依然会由其中的Reduce9来处理这893万条数据,依然会发生严重的数据倾斜,严重拖累整个MapReduce任务的执行。
所以现在需要通过另一种方式将ID为9的893万条数据打散,让它重新均匀分布。
通过增加Reduce任务个数的方式解决数据倾斜问题。
package com.itechthink.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 解决数据倾斜:增加Reduce任务个数
*
*/
public class WordCountJobDataSkew {
/**
* Map阶段
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String[] words = v1.toString().split(" ");
Text k2 = new Text(words[0]);
LongWritable v2 = new LongWritable(1L);
context.write(k2, v2);
}
}
/**
* Reduce阶段
*
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {
long sum = 0L;
for (LongWritable v2 : v2s) {
sum += v2.get();
if (sum % 200 == 0) {
Thread.sleep(1);
}
}
LongWritable v3 = new LongWritable(sum);
context.write(k2, v3);
}
}
/**
* 组装Job = Map + Reduce
*
*/
public static void main(String[] args) {
try {
if (args.length != 3) {
System.exit(0);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJobDataSkew.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 设置Reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
// 提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}通过把倾斜的数据打散的方式解决数据倾斜问题。
package com.itechthink.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Random;
/**
* 解决数据倾斜:把倾斜的数据打散
*
*/
public class WordCountJobDataSkewByRandKey {
/**
* Map阶段
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
Random random = new Random();
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String[] words = v1.toString().split(" ");
String key = words[0];
// 给ID增加一些随机数,打散数据倾斜
if ("5".equals(key)) {
key = "5" + "_" + random.nextInt(10);
}
Text k2 = new Text(key);
LongWritable v2 = new LongWritable(1L);
context.write(k2, v2);
}
}
/**
* Reduce阶段
*
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
*
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {
long sum = 0L;
for (LongWritable v2 : v2s) {
sum += v2.get();
if (sum % 200 == 0) {
Thread.sleep(1);
}
}
LongWritable v3 = new LongWritable(sum);
context.write(k2, v3);
}
}
/**
* 组装Job = Map + Reduce
*
*/
public static void main(String[] args) {
try {
if (args.length != 3) {
System.exit(0);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJobDataSkewByRandKey.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 设置Reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
// 提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}感谢支持
更多内容,请移步《超级个体》。