
持久化与共享变量
RDD持久化
当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的分区持久化到内存中,并且之后对RDD的操作都会直接调用已经持久化分区,节约计算资源。
package com.itechthink.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* Scala版RDD持久化
*
*/
object ScalaPersistenceRDD {
def main(args: Array[String]): Unit = {
// 1. 先创建SparkContext
val conf = new SparkConf()
// 设置应用程序名称
.setAppName("ScalaPersistenceRDD")
// 设置Spark运行模式
.setMaster("local")
val sc = new SparkContext(conf)
// 2. 加载数据(持久化)
// cache()默认是基于内存的持久化
val dataRDD = sc.textFile("/Users/bear/Downloads/user.sql")
// 3. transformation操作
var start_time = System.currentTimeMillis()
var count = dataRDD.count()
println("count = " + count)
var end_time = System.currentTimeMillis()
println("第一次耗时:" + (end_time - start_time))
start_time = System.currentTimeMillis()
count = dataRDD.count()
println("count = " + count)
end_time = System.currentTimeMillis()
println("第二次耗时:" + (end_time - start_time))
// 4. 关闭SparkContext
sc.stop()
}
}执行后的结果如下。
不使用cache()
count = 1000041
第一次耗时:1240
count = 1000041
第二次耗时:528
------
使用cache()
count = 1000041
第一次耗时:1633
count = 1000041
第二次耗时:68package com.itechthink.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* Java版RDD持久化
*
*/
public class JavaPersistenceRDD {
public static void main(String[] args) {
// 1. 先创建SparkContext
SparkConf conf = new SparkConf()
// 设置应用程序名称
.setAppName("JavaPersistenceRDD")
// 设置Spark运行模式
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 2. 加载数据
JavaRDD<String> dataRDD = sc.textFile("/Users/bear/Downloads/user.sql").cache();
// 3. transformation操作
long start_time = System.currentTimeMillis();
long count = dataRDD.count();
System.out.println("count = " + count);
long end_time = System.currentTimeMillis();
System.out.println("第一次耗时:" + (end_time - start_time));
start_time = System.currentTimeMillis();
count = dataRDD.count();
System.out.println("count = " + count);
end_time = System.currentTimeMillis();
System.out.println("第二次耗时:" + (end_time - start_time));
// 4. 关闭SparkContext
sc.close();
}
}执行后的结果和Scala 2非常接近。
不使用cache()
count = 1000041
第一次耗时:1262
count = 1000041
第二次耗时:534
------
使用cache()
count = 1000041
第一次耗时:1636
count = 1000041
第二次耗时:74Broadcast Variable
默认情况下,某个算子使用到的外部变量会被拷贝到每个task中,而每个task只能操作自己的变量数据。
如果希望每个task都能共享变量的数据,那就只能使用Spark提供的Shared Variables,也就是共享变量。
Spark提供了两种Shared Variables:Broadcast Variables(广播变量)和Accumulators(累加变量)。
Broadcast Variables(广播变量)会将使用到的变量仅仅为每个节点拷贝一份,而不是给每个task都拷贝一份,这样可以减少很多不必要的网络传输和内存消耗,优化性能。
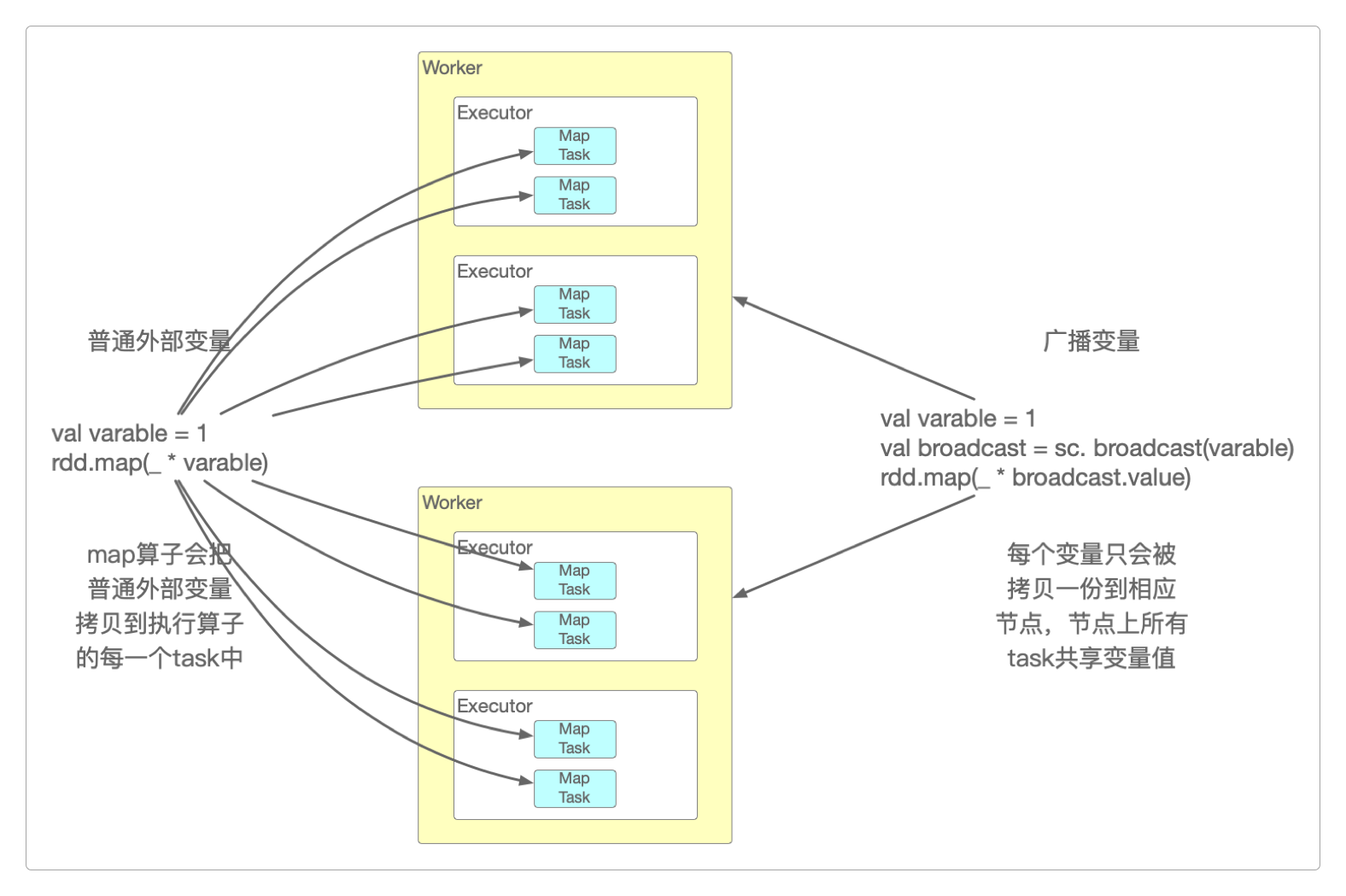
只需要对某个变量调用SparkContext的broadcast()方法,就可以创建它。
但创建出来的Broadcast Variables(广播变量)是只读的,只能通过value()方法读取它的数值。
Broadcast Variables(广播变量)的Scala 2代码。
package com.itechthink.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* Scala版广播变量
*
*/
object ScalaBroadcastVariables {
def main(args: Array[String]): Unit = {
// 1. 先创建SparkContext
val conf = new SparkConf()
// 设置应用程序名称
.setAppName("ScalaBroadcastVariables")
// 设置Spark运行模式
.setMaster("local")
val sc = new SparkContext(conf)
// 2. 加载数据
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
// 普通变量
val varnum = 2
//dataRDD.map(_ * varnum)
// 广播变量
val broadcast = sc.broadcast(varnum)
dataRDD.map(_ * broadcast.value)
// 3. 关闭SparkContext
sc.stop()
}
}Broadcast Variables(广播变量)的Java代码。
package com.itechthink.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.broadcast.Broadcast;
import java.util.Arrays;
/**
* Java版广播变量
*
*/
public class JavaBroadcastVariables {
public static void main(String[] args) {
// 1. 先创建SparkContext
SparkConf conf = new SparkConf()
// 设置应用程序名称
.setAppName("JavaBroadcastVariables")
// 设置Spark运行模式
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 2. 加载数据
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
// 普通变量
int varnum = 2;
//dataRDD.map(x -> x * varnum)
// 广播变量
Broadcast<Integer> broadcast = sc.broadcast(varnum);
dataRDD.map(x -> x * broadcast.value());
// 3. 关闭SparkContext
sc.close();
}
}Accumulator
由于Broadcast Variables(广播变量)只能读不能写,所以Spark又提供了Accumulators(累加变量),用于多个节点对某个变量进行共享性操作。
但Accumulators(累加变量)只提供了累加功能,task只能对它进行累加操作,而不能读取它的值,只有Driver进程才能读取。
Accumulators(累加变量)的Scala 2代码。
package com.itechthink.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* Scala版累加变量
*
*/
object ScalaAccumulators {
def main(args: Array[String]): Unit = {
// 1. 先创建SparkContext
val conf = new SparkConf()
// 设置应用程序名称
.setAppName("ScalaAccumulators")
// 设置Spark运行模式
.setMaster("local")
val sc = new SparkContext(conf)
// 2. 加载数据
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5))
var total = 0
dataRDD.foreach(x => total += x)
// 因为累加变量total是局部变量,foreach代码是在worker节点上执行的
// 而 total = 0 和 println(total) 是在driver进程中执行的
// 所以结果依然是0
// 并且foreach算子会在多个task中执行,这样foreach内部实现的累加也不是最终全局累加的结果
println(total)
val totalAcc = sc.longAccumulator
dataRDD.foreach(x => totalAcc.add(x))
// 只能在driver进程中读取累加的结果
println(totalAcc.value)
// 3. 关闭SparkContext
sc.stop()
}
}Accumulators(累加变量)的Java代码。
package com.itechthink.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.util.LongAccumulator;
import java.util.Arrays;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Java版累加变量
*
*/
public class JavaAccumulators {
public static void main(String[] args) {
// 1. 先创建SparkContext
SparkConf conf = new SparkConf()
// 设置应用程序名称
.setAppName("JavaAccumulators")
// 设置Spark运行模式
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 2. 加载数据
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
AtomicInteger total = new AtomicInteger();
dataRDD.foreach(total::addAndGet);
// 因为累加变量total是局部变量,foreach代码是在worker节点上执行的
// 而 total = 0 和 println(total) 是在driver进程中执行的
// 所以结果依然是0
// 并且foreach算子会在多个task中执行,这样foreach内部实现的累加也不是最终全局累加的结果
System.out.println(total.get());
LongAccumulator totalAcc = sc.sc().longAccumulator();
dataRDD.foreach(totalAcc::add);
// 只能在driver进程中读取累加的结果
System.out.println(totalAcc.value());
// 3. 关闭SparkContext
sc.close();
}
}感谢支持
更多内容,请移步《超级个体》。