
什么是RDD?
RDD的概念
RDD(
Resilient Distributed Datasets,弹性分布式数据集)是Spark提供的一个非常核心的抽象概念,它是一种可以被分为多个分区(Partition)的数据元素的集合。默认情况下,RDD的数据是存放在内存中的,而当内存资源不足时,Spark会自动将RDD中的数据写入磁盘(这是它之所以具有
弹性的原因)。分区分布在集群中的不同节点上,所以RDD中的数据可以被并行操作(这是它之所以具有分布式的原因)。RDD最重要的特性就是
容错性,它可以自动从节点失败中恢复过来。即如果某个节点上的分区因为节点故障,导致数据丢失,那么RDD会自动通过自己的数据来源重新计算分区,这一切对使用者都是透明的。可以这样来理解:RDD = 数据 + 算子。
下面是一个极其粗略的Spark计算任务的执行过程。

Spark客户端向集群提交计算任务(此时会生成一个
Driver进程。这个Driver进程所在的节点可以是Spark集群中的节点,也可以就是Spark客户端节点,它是通过任务提交时的参数决定的)。Spark根据客户端给出的地址,从数据源中拿到数据。这里的数据源大多是情况下都是存储在Hadoop的HDFS中的数据(此时集群主节点的
Master进程和从节点的Worker进程相继启动,Master进程负责整个Spark客户端集群的管理和监控,以及资源的分配,而Worker进程则负责具体计算任务的执行)。由
Worker负责启动一个叫做Executor的进程,它负责数据的计算和处理,之后它被反注册到Driver进程中。它将待计算的30万行数据被均匀地分布到了三个节点中,形成了3个分区,每个分区都拿到了10万行数据。Executor这3个
分区在逻辑上组成了一个RDD。Driver进程会提交干个Task线程到Executor中,Task线程真正地执行计算任务的线程,例如各种算子的执行,都是它来完成的。当前RDD执行完
算子所要求的计算后就把数据结果发送给下一个RDD。这里Executor的进程执行Driver分配给它的若干个Task线程,并形成新的RDD中的分区。所有的计算任务执行完成后,Spark会把计算结果保存到数据存储目的地中,这里的数据存储目的地大多是情况下也都是HDFS。
因此,整个Spark任务执行的大致流程如下。
`Driver` -----┐1
↑ | ↓
| | `Master` -----┐2
| | ↓
| | `Worker` -----┐3
| | ↓
4└-+------------------------- `Executor`-----┐6
| ↑ |
5└----------- Task -------------┘ |
↓
`RDD Partition`完整的Spark任务执行过程如下。
Application(1.开发的Spark应用程序) -> spark-submit(2.提交到Spark集群) -> Driver(3.进程,由spark-submit构造)
|
|
|
┌------------------+------------------------------------------------------------------------------┐
| ↓ ↑
| 4.SparkContext -> 9.初始化完成,继续执行计算 -> 10.(每)执行到Action RDD -> 11.创建Job
|
| ┌------------------------------┐
| ↙↙ ↘↘ | =======================|=====┐
| ↓ | | |(16.将TaskSet中的每一个
(Job提交)└--> 12.DAGScheduler 5.TaskScheduler(后台进程)----------------┐ | | Task提交到Executor)
/ (负责连接Master及注册Application) | | | (Task分配算法)
/ | | |
/ | | |
/ (将自己反向注册到Driver) | | |
18.取出TaskRunner执行(线程池) <----- 17.封装Task(TaskRunner) <------/------------- 8.Executor(进程) <=================|====|=====┘
(拿到算子及函数的拷贝,反序列化后执行) / ↑ | |
/ | | |
/ | | |
/ | | |
/ 7.Worker | |
↓ ↑ | |
13.将Job划分为多个Stage | | |
(划分算法) | | |
| 6.Master(资源调度算法) <-----------┘ |
↓ |
14.每个Stage创建一个TaskSet |
| |
| |(15.TaskSet提交给TaskScheduler)
└-----------------------------------------------------------------┘两种RDD
Spark把RDD的操作分为两种不同的类型,其实它也对应于两大类不同的算子操作。
transformation操作:它会针对已有的RDD创建一个新的RDD,而且具有Lazy Loading(又叫延迟加载,懒加载)特性,也就是说,transformation操作只是记录了RDD需要执行的任务,但不会立即执行,除非有外部条件触发(也就是由action操作触发)。action操作:它是一种任务收尾性的操作,例如遍历结果数据集、reduce汇聚结果、将结果保存到文件等操作都属于这一类。action操作会触发一个Spark任务执行,从而触发这个action之前所有的transformation的执行,并且它还会将执行的结果返回给Driver程序。
三种生成RDD的方式
RDD是Spark开发中非常核心的东西,开发中的首要工作就是创建一个初始的RDD。
通过集合生成
// 第2个参数指定分区Partition的个数,不指定的话默认值为2
val linesRDD = sc.parallelize(List("hello world", "hello spark", "hello scala"), 2)// 第2个参数指定分区Partition的个数,不指定的话默认值为2
JavaRDD<String> linesRDD = sc.parallelize(Arrays.asList("hello world", "hello spark", "hello java"), 2);通过本地文件生成
textFile()方法支持针对目录、压缩文件以及通配符生成RDD。
// 第2个参数指定分区Partition的个数,不指定的话默认值为2
val linesRDD = sc.textFile("/home/work/wordcount.txt", 2)// 第2个参数指定分区Partition的个数,不指定的话默认值为2
JavaRDD<String> linesRDD = sc.textFile("/home/work/wordcount.txt", 2);通过HDFS文件生成
在这种方式下,Spark默认会为HDFS文件的每一个Block创建一个对应的分区Partition。
如果通过textFile()方法的第2个参数手动指定分区数量的话,那么这个数量只能比Block,而不能比它少。
// 第2个参数指定分区Partition的个数,不指定的话默认值为2
val linesRDD = sc.textFile("hdfs://hadoop:9000/spark/job/wordcount.txt", 2)// 第2个参数指定分区Partition的个数,不指定的话默认值为2
JavaRDD<String> linesRDD = sc.textFile("hdfs://hadoop:9000/spark/job/wordcount.txt", 2);RDD持久化
Spark之所以能够实现大数据计算秒级响应的一个很重要的原因就是RDD的持久化。
但RDD的持久化既不是指的将数据保存在数据库中的那种持久化,又不是指的将数据保存在磁盘中的那种持久化,而是指的 将RDD持久化在内存中。
当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的分区持久化到内存中,并且之后如果再次调用该RDD,那么就直接使用内存中的分区数据。
也就是说,对于某个RDD被反复执行多次的应用场景,Spark可以事先执行一次计算,然后将计算结果保存下来(也就是持久化)。当需要再次调用这个RDD执行计算时直接给结果就行了,而不必每次都重复计算,浪费时间和资源——这其实是一种以空间换时间的提升性能的做法。
特别是一些迭代步骤多或者需要频繁交互的应用场景,这种将RDD持久化的做法对性能的提升特别明显。
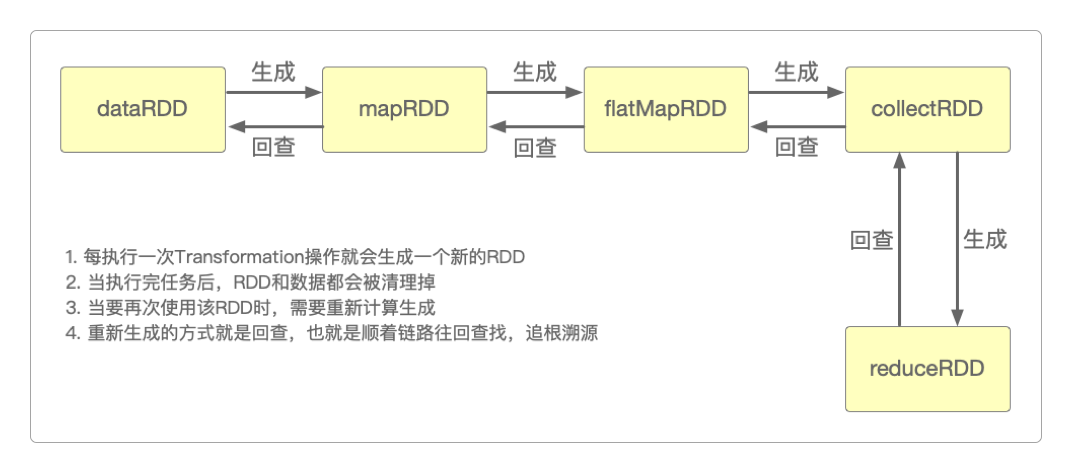
如果没有持久化,那么当要再次使用reduceRDD时,最坏的情况就是Spark顺着链路往回找,把所有的RDD全部重新生成一次。
查找 查找 查找 查找
`reduceRDD` ---> `collectRDD` ---> `flatMapRDD` ---> `mapRDD` ---> `dataRDD`
|
|
|
`reduceRDD` <--- `collectRDD` <--- `flatMapRDD` <--- `mapRDD` <--- ┘
生成 生成 生成 生成要持久化一个RDD,只要调用其cache()或者persist()方法就行了。当该RDD第一次被计算出来时,就会直接缓存在每个节点中。
Spark的RDD持久化机制是自动容错的:如果持久化的RDD的任何分区丢失了,那么Spark会自动通过其源RDD(也就是上游RDD),使用transformation操作重新计算该分区。
关于RDD的持久化有一个小小的误区。
......
// 正确的调用方式
JavaRDD<String> rdd = context.textFile("hdfs://hadoop:9000/input/spark.txt").cache();
// 错误的调用方式:这样调用是没有效果的,而且会报错,大量的文件会丢失
JavaRDD<String> rdd = context.textFile("hdfs://hadoop:9000/input/spark.txt");
rdd.cache();
......RDD的持久化可以选择不同实现策略,比如可以选择持久化的存储介质,例如,可以将RDD持久化在内存中、磁盘上,使用序列化的方式持久化,使持久化的数据支持多路复用等。
| 持久化级别 | 说明 |
|---|---|
| MEMORY_ONLY | 以非序列化Java对象的方式持久化在JVM内存中。如果内存无法存储RDD所有的分区,那么那些没有持久化的分区就会在下一次需要使用它的时候被重新计算 |
| MEMORY_AND_DISK | 同上,但是当某些分区无法存储在内存中时,会持久化到磁盘中,下次需要使用这些分区时,需要从磁盘上读取 |
| MEMORY_ONLY_SER (Java and Scala) | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销 |
| MEMORY_AND_DSK_SER (Java and Scala) | 同MEMORY_AND_DSK,但是使用序列化方式持久化Java对象 |
| DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2 等 | 同MEMORY_ONLY,但尾部加了2的持久化级别,表示会将持久化数据复制一份保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
| OFF_HEAP (实验性功能) | 同MEMORY_ONLY_SER,但将数据存储在堆外内存中,需要启用堆外内存 |
Spark提供多种持久化级别的主要目的是为了在CPU和内存消耗之间进行取舍,下面是一些通用的持久化级别的选择建议。
应该优先使用
MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。如果
MEMORY_ONLY策略无法存储的下所有数据的话,那么就使用MEMORY_ONLY_SER将数据序列化后再进行存储,纯内存操作还是非常快,只是要消耗CPU进行反序列化。如果需要快速从失败中恢复,那么就选择带后缀为
_2的策略进行数据备份,这样在失败时,就不需要重新计算了。能不使用
DISK相关的策略就不使用,有时从磁盘读取数据还不如重新计算一次。
感谢支持
更多内容,请移步《超级个体》。