
性能优化
内存优化
既然Spark是一个基于内存执行计算的大数据系统,那么必须知道它是如何使用内存空间的。
可以通过实际的代码执行效果来估算Spark程序的内存使用情况。
使用Scala 2预估内存的执行情况。
package com.itechthink.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
* 预估内存占用情况
*
*/
object TestMemoryScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("TestMemoryScala")
.setMaster("local")
val sc = new SparkContext(conf)
val path1 = "hdfs://172.16.185.176:9000/data/testfile1"
val path2 = "/testfile1"
val dataRDD = sc.textFile(path2).cache()
val count = dataRDD.count()
println("testfile1文件有 " + count + " 行")
// 让程序循环执行,在本地查看4040页面中的storage信息
while (true) {}
}
}程序启动后会输出如下信息。
......
INFO Utils: Successfully started service 'SparkUI' on port 4040.
INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.2.4:4040
INFO Executor: Starting executor ID driver on host 192.168.2.4
......
testfile1文件有 1179565 行现在可以通过浏览器访问http://192.168.2.4:4040查看对应的内存数据了。
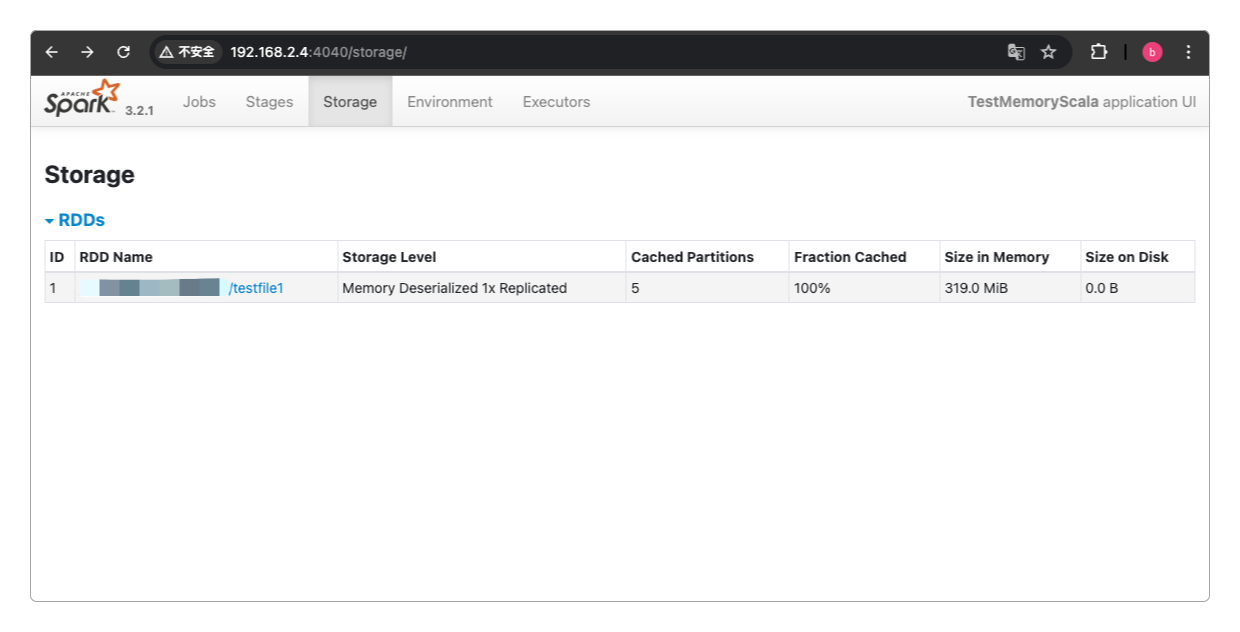
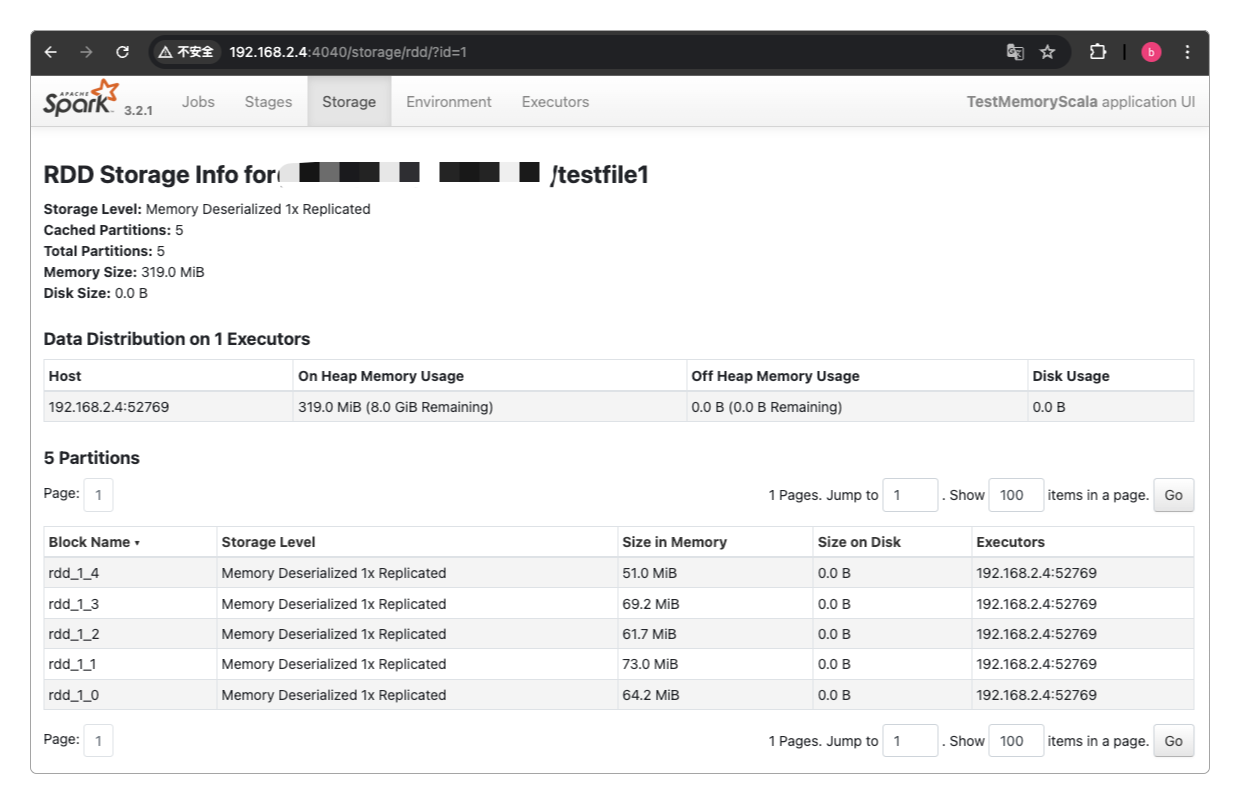
用于测试的文件testfile1实际大小只有157MB,但从上图可以看到,进入到Spark的RDD中之后,它的体积立马翻倍了,这几乎是一个比较普遍的现象。
因此在预估Spark所要使用的JVM内存大小时,必须要知道这种现象才能合理规划。
再通过使用Java来预估内存的执行情况。
package com.itechthink.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 预估内存占用情况
*
*/
public class JavaTestMemory {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
// 设置应用程序名称
.setAppName("JavaTestMemory")
// 设置Spark运行模式
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
String path1 = "hdfs://172.16.185.176:9000/data/testfile1";
String path2 = "/testfile1";
JavaRDD<String> linesRDD = sc.textFile(path2);
long count = linesRDD.count();
System.out.println("testfile1文件有 " + count + " 行");
// 让程序循环执行,在本地查看4040页面中的storage信息
while (true) {}
}
}程序启动后输出的内容同Scala 2一致。
......
INFO Utils: Successfully started service 'SparkUI' on port 4040.
INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.2.4:4040
INFO Executor: Starting executor ID driver on host 192.168.2.4
......
testfile1文件有 1179565 行也可以通过浏览器访问http://192.168.2.4:4040查看对应的内存数据,它显示的内容也和Scala 2一致。
Kryo
Spark再执行作业时难免会进行一些数据序列化的工作,它默认采用的是Java的序列化类Serializable,但其实可以采用性能更高的序列化类库Kryo,一是减少序列化后的文件大小,二是提升速度和效率。
Kryo的执行速度比Serializable更快,而且序列化后的数据更小(号称比Java小10倍),能节省很多存储空间,而且Spark也支持使用Kryo进行序列化。
一般在使用自定义对象,而且这些自定义的对象都在某集合中时,或者使用到了外部的大对象时,比较适合使用Kryo进行自定义的序列化。
先引入Kryo的依赖。
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.4.0</version>
</dependency>package com.itechthink.rdd
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* 使用Kryo执行序列化
*
*/
object ScalaKryoSerializer {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaKryoSerializer")
.setMaster("local")
/*
* 指定使用kryo序列化,在http://192.168.2.4:4040/storage/中显示内存使用为36B
*
* 当注同时注释
* set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
* registerKryoClasses(Array(classOf[Data]))时,http://192.168.2.4:4040/storage/中显示内存使用为146B
*/
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
/*
* 如果仅仅只设置 set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
* 但注释 registerKryoClasses(Array(classOf[Data]))时,http://192.168.2.4:4040/storage/中显示内存使用为132B
* 说明启用Kryo的时候,最好也注册需要序列化的类,否则效果大打折扣
*/
//.registerKryoClasses(Array(classOf[Data]))
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array("hello scala", "hello spark"))
val wordsRDD = dataRDD.flatMap(_.split(" "))
val counterRDD = wordsRDD.map(word => Data(word, 1)).persist(StorageLevel.MEMORY_ONLY_SER)
counterRDD.foreach(println(_))
while (true) {}
}
}
case class Data(name: String, times: Int) extends Serializablepackage com.itechthink.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.storage.StorageLevel;
import java.io.Serializable;
import java.util.Arrays;
import java.util.Iterator;
/**
* 使用Kryo执行序列化
*
*/
public class JavaKryoSerializer {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("JavaKryoSerializer")
.setMaster("local");
/*
* 整体效果和Scala几乎没有差别
*/
//.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 使用自定义的数据类型
//.set("spark.kryo.classesToRegister", "com.itechthink.rdd.Counter");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> dataRDD = sc.parallelize(Arrays.asList("hello scala", "hello spark"));
JavaRDD<String> wordsRDD = dataRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaRDD<Counter> counterRDD = wordsRDD.map(new Function<String, Counter>() {
@Override
public Counter call(String word) throws Exception {
return new Counter(word, 1);
}
}).persist(StorageLevel.MEMORY_ONLY_SER());
counterRDD.foreach(new VoidFunction<Counter>() {
@Override
public void call(Counter counter) throws Exception {
System.out.println(counter);
}
});
while (true) {
}
}
}
class Counter implements Serializable {
private String name;
private int times;
Counter(String name, int times) {
this.name = name;
this.times = times;
}
@Override
public String toString() {
return "Counter{" +
"name='" + name + '\'' +
", times=" + times +
'}';
}
}Checkpoint
可以对RDD执行持久化操作,避免它被反复计算,再配合StorageLevel.MEMORY_ONLY_SER存储级别。
然后再对RDD调用checkpoint()方法,实现持久化的高可靠。
JVM调优
默认情况下,Spark使用每个Executor中60%的内存空间来缓存RDD,那也就只剩下40%的空间用来存放算子执行期间创建的对象了。
当这40%的空间不足以继续执行作业时,就会触发JVM GC。
可以通过conf.set("spark.storage.memoryFraction", "0.6")来调整这个60%和40%的比例。
另外,可以通过查看Spark中每个Task的执行情况来观察是否发生或频繁发生JVM GC。
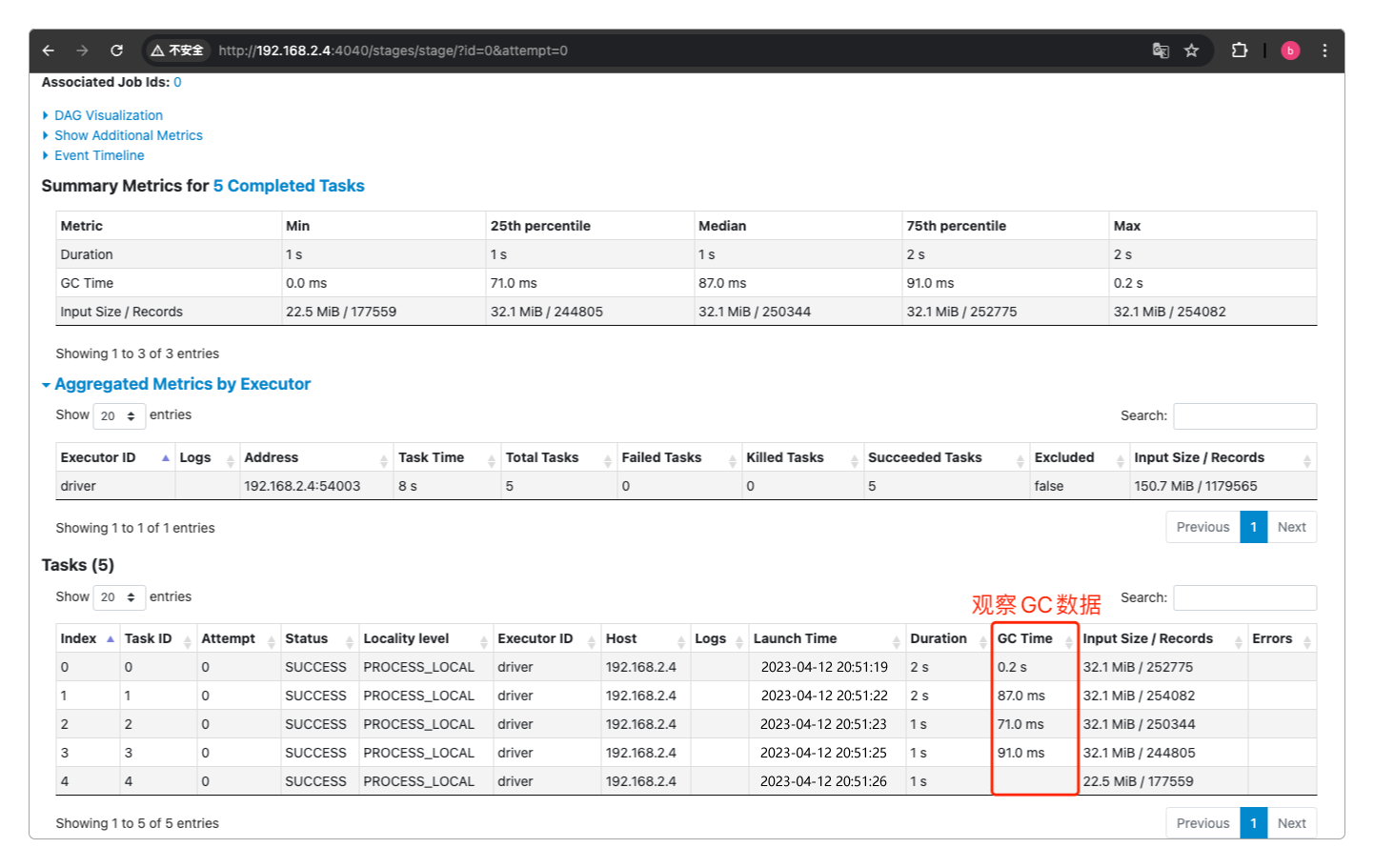
除了查看每个Task,也能查看Executor整体的JVM GC情况。

所以,在整体上对Spark的JVM GC进行优化就肯定是绕不开的问题。
而如何实施JVM调优,可以参考我写的《Java深度探索:开发基础、高级技术与工程实践》中《第4章 JVM GC》的内容。
算子并行度
实际上,Spark集群的资源并不一定会被充分利用,可以通过设置算子的并行度来调节。
可以通过textFile()和parallelize()方法中的第二个参数来指定并行度,也可以通过spark.default.parallelism参数来设置统一的并行度(Spark官方推荐给集群中的每个CPU Core设置2~3个Task)。
例如,有以下spark-submit执行脚本。
> ./bin/spark-submit \
--class com.itechthink.ScalaWordCount \
--master spark://hadoop:7077 \
--deploy-mode cluster \
--executor-memory 1G \
# 这里给任务设置了5个executors
--num-executors 5 \
# 每个executor有2个CPU Core
--executor-cores 2 \
/home/work/volumes/spark/job/ScalaJavaSpark-1.0-SNAPSHOT-jar-with-dependencies.jar \
# 指定数据源路径
hdfs://hadoop:9000/spark/job/wordcount.txt而执行任务的代码片段是这样的。
......
conf.setAppName("JobTask")
.setMaster("spark://hadoop:7077")
.set("spark.default.parallelism", "5")
......那么问题来了。
set("spark.default.parallelism", "5")把所有RDD的并行度都设置成了5,也就是每个RDD都有5个Partition,每一个Partition,Spark都会启动一个对应的Task来计算。--num-executors 5和--executor-cores 2设置了5个Executor,而每个Executor又用2个CPU Core去执行,这样一来就有10((5 × 2)个CPU Core。代码指定了只用5个,但脚本却申请了10个,所以就会有5个
CPU Core空闲。
但性能最优的情况是每个CPU Core都不空闲,而且官方还建议给每个CPU Core设置2~3个Task,这样充分压榨CPU的性能。
按照这种思路,两种更改的办法。
- 一是如果脚本设置不变,那么就需要改一改代码中的设置。
......
conf.setAppName("JobTask")
.setMaster("spark://hadoop:7077")
.set("spark.default.parallelism", "20")
......把每个RDD都划分成20个Partition,也就是会有对应的20个Task,虽然脚本只产生10个CPU Core,但每个CPU Core都必须执行2个任务。
- 二是代码设置不变,改一改脚本设置。
> ./bin/spark-submit \
--class com.itechthink.ScalaWordCount \
--master spark://hadoop:7077 \
--deploy-mode cluster \
--executor-memory 1G \
# 将executors的数量改为1
--num-executors 1 \
# CPU Core数量不变
--executor-cores 2 \
/home/work/volumes/spark/job/ScalaJavaSpark-1.0-SNAPSHOT-jar-with-dependencies.jar \
# 指定数据源路径
hdfs://hadoop:9000/spark/job/wordcount.txt这样一来,就只有2个CPU Core可用,但任务有5个Task,平均下来每个CPU Core会分到2~3个Task,依然可以充分压榨CPU性能。
这也说明另一个问题:代码和执行脚本之间需要协调配合,并设置合理的parallelism和executor-cores。
最后一个问题。
# 第一种方式:多Executor单CPU Core模式
--num-executors 2
--executor-cores 1
# 第二种方式:单Executor多CPU Core模式
--num-executors 1
--executor-cores 2这两种设置最终都会向集群申请2个CPU Core,并行运行两个Task,但这两种方式的区别是什么?
多
Executor单CPU Core模式:因为只有一个CPU Core,所以无法发挥JVM利用多核的优势运行多任务,而如果这两个Executor分别在不同的节点中启动,那么会把数据通过广播复制两份。单
Executor多CPU Core模式:虽然只有一个Executor,但一方面JVM可以利用多核的优势运行多个任务,二是因为只有一个Executor,所以数据只会有1份,减少了不必要的网络空存储空间消耗。
也不是把CPU Core设置的越大越好,一是内存大小和CPU的数量有限,二是过多会导致Task争抢资源,不利于任务的执行。
数据本地化
如果数据和计算它的代码在同一个地方(不光是逻辑上,物理上也在同一台计算机上),那肯定会节约很多数据传输的网络开销,性能会提升不少。
相对于移动以GB为单位的数据,移动代码肯定开销更小,所以Spark会根据这种原则来调度Task的执行。
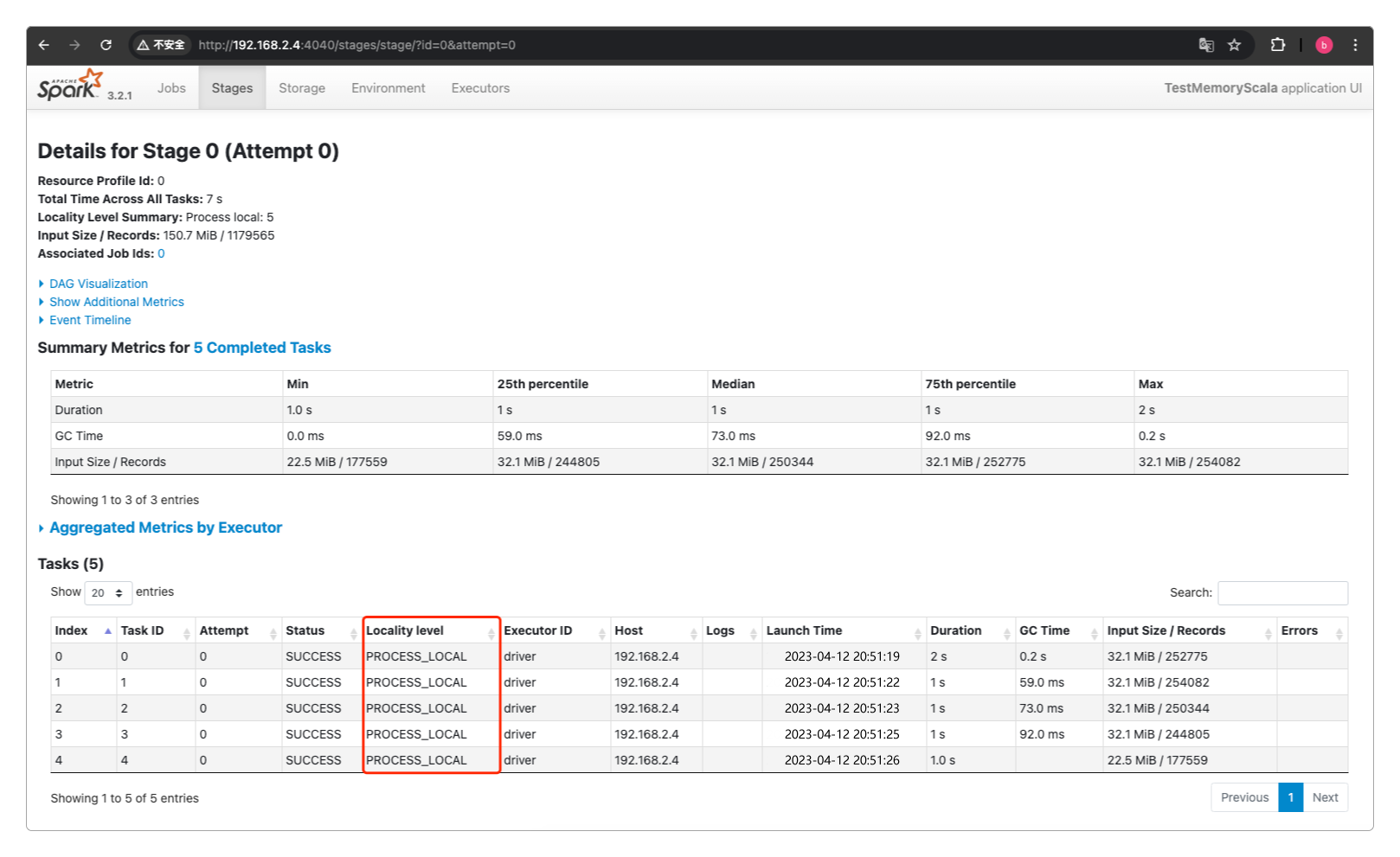
Spark的数据本地化级别如下。
| 级别 | 说明 |
|---|---|
| PROCESS_LOCAL | 数据和计算代码在同一个进程,性能最好 |
| NODE_LOCAL | 数据和计算代码在同一个节点,但是不在一个JVM进程,数据要跨进程拷贝,性能稍次 |
| NO_PREF | 数据在哪里都一样,不影响性能,例如数据在数据库中 |
| RACK_LOCAL | 数据和计算代码在同一个机架(有点类似于局域网或RAID的意思) |
| ANY | 数据可能在任意的地点,性能最差 |
如果待处理数据所在的Executor中没有空闲可用的CPU Core,那么Spark要么等待,直到有空闲的CPU Core可用,这样就可以达到PROCESS_LOCAL级别的最佳性能。要么立即在别的Executor中启动Task执行任务,那性能就无法保证了。
可以通过设置这个等待时间的阈值来调整Spark的执行性能,通过设置spark.locality系列参数,就可以调节这个等待时间。
spark.locality.wait.process、spark.locality.wait.node、spark.locality.wait.rack从名字就可以看出来它们设置的是哪种数据本地化级别。
还有一个通用的参数spark.locality.wait用于设置统一的等待时间阈值,默认值是3000毫秒。
同样可以在http://192.168.2.4:4040查看对应的数据本地化级别。
感谢支持
更多内容,请移步《超级个体》。