
什么是Flume?
三大核心组件
官方对Flume的定义有这么几个关键点。
一种高可用、高可靠的分布式系统。
实现海量日志的高效采集、聚合和传输。
具有基于流的数据架构。
具有负载均衡机制、故障转移和恢复机制。
具有简单可扩展的数据模型。
它一行代码都不需要写,就能实现PB级的日志采集、聚合和传输,简单来说就是简单、好用、靠谱。
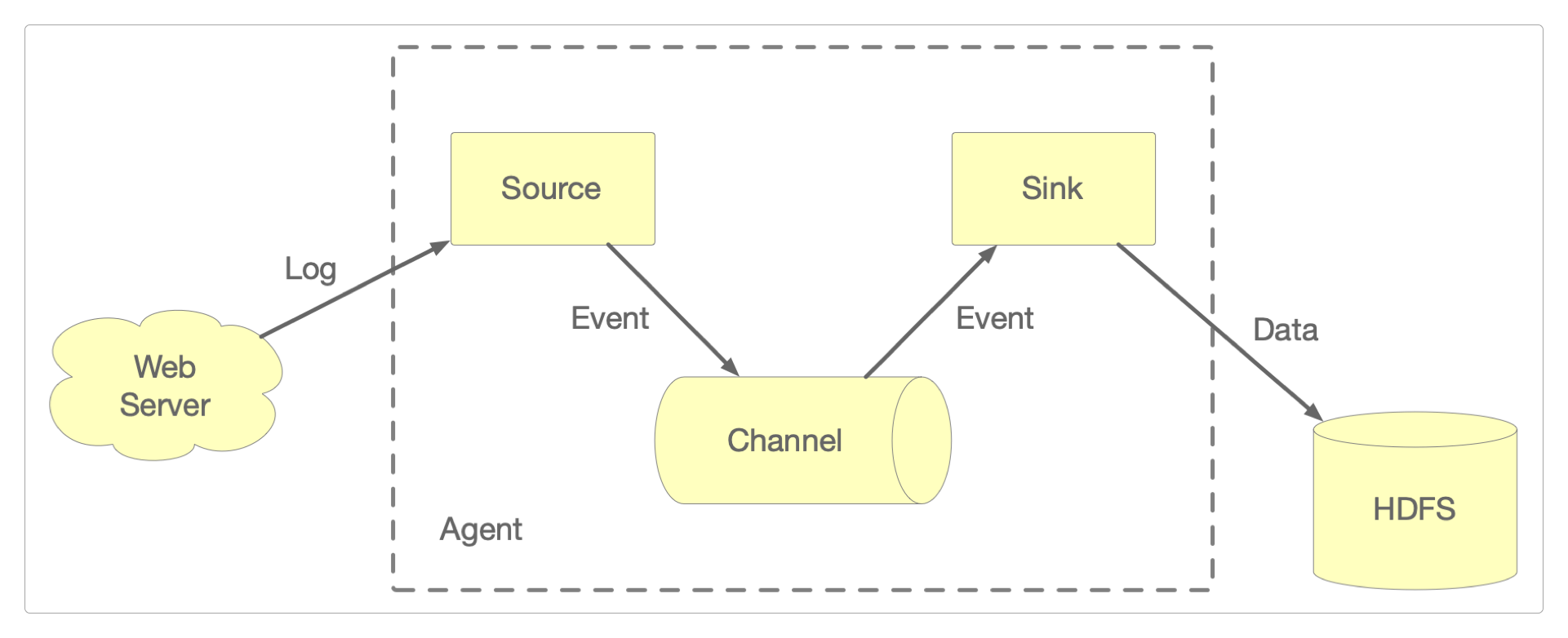
Source
定义数据源,从外界采集各种类型的数据,例如文件、目录、端口、MQ等,并将这些数据传递给Channel。
Flume已经定义了下面几种常用的数据源。
Exec Source:实现对文件的实时监控,文件的任何变化都能作为数据源的输入。NetCat TCP/UDP Source:采集指定端口的数据。Spooling Directory Source:采集指定文件夹中新增的文件。Kafka Source:采集Kafka消息队列中的数据。
Channel
输送数据的管道,接收从Source发出的数据,并将数据输送到Sink。
和Source一样,Channel也有多种不同的类型,例如内存、文件、JDBC等,常用的Channel有下面几种。
Memory Channel:使用内存作为输送数据的管道。File Channel:使用文件作为输送数据的管道。Spillable Memory Channel:同时使用内存和文件作为输送数据的管道。数据会先到内存中,如果内存数据达到预设的阈值再Flush到文件。
直到数据被成功保存到Sink所指定的目的地后,Channel中的数据才会被删除。而且,当Sink写入失败后,Flume会通过事务的方式保证自动重写,所以它不会有数据丢失问题。
Sink
定义数据发送的目的地,它从Channel接收输送过来的数据,并存储到指定的目的地,例如控制台、HDFS、Kafka等。
Flume也定义了下面几种常用的Sink。
典型应用场景
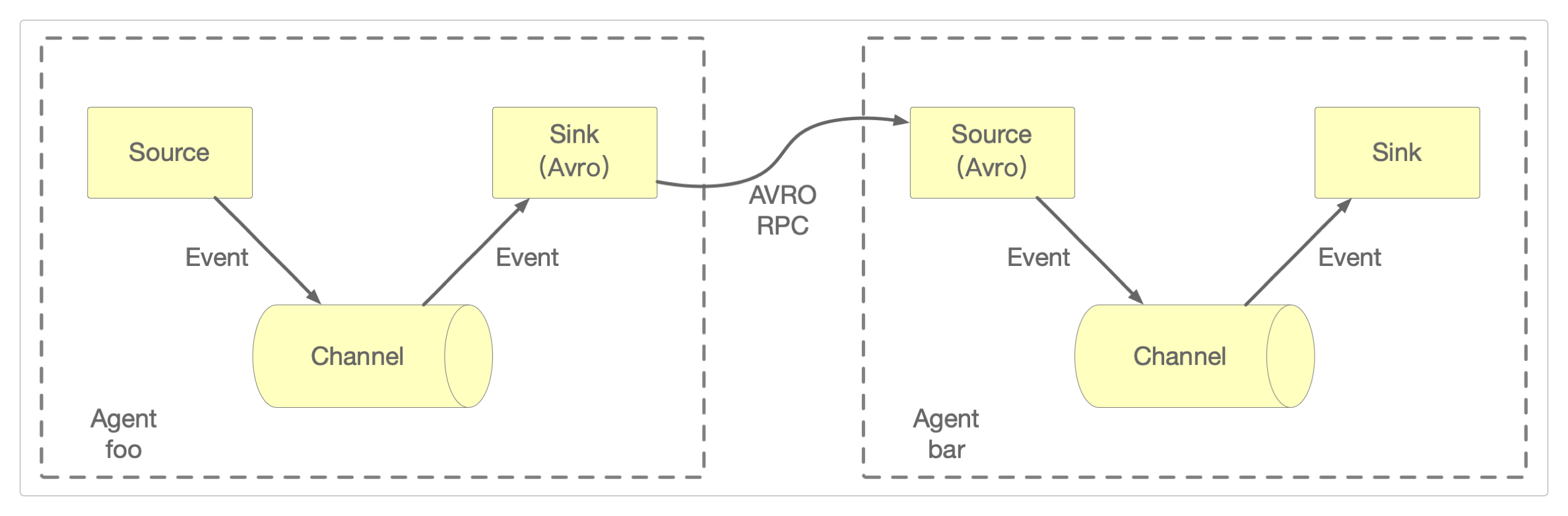
多Agent流
为了使数据能够在多个服务间流动,可以将多个Agent首尾相连,形成一条数据链。
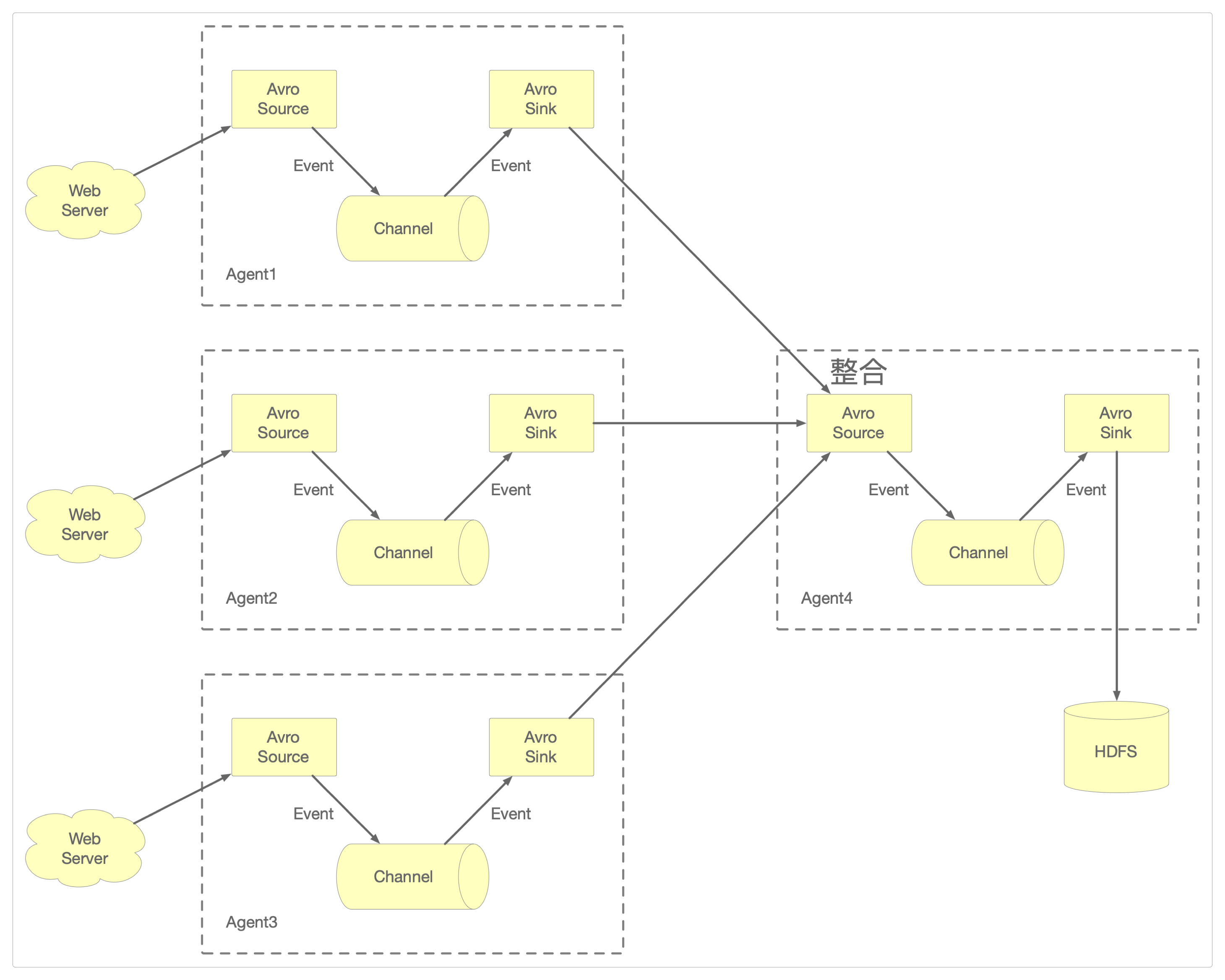
多流汇聚
可以将大量生成日志的Web服务输出,汇聚到一个统一的连接数据存储系统(例如HDFS)的输入上。
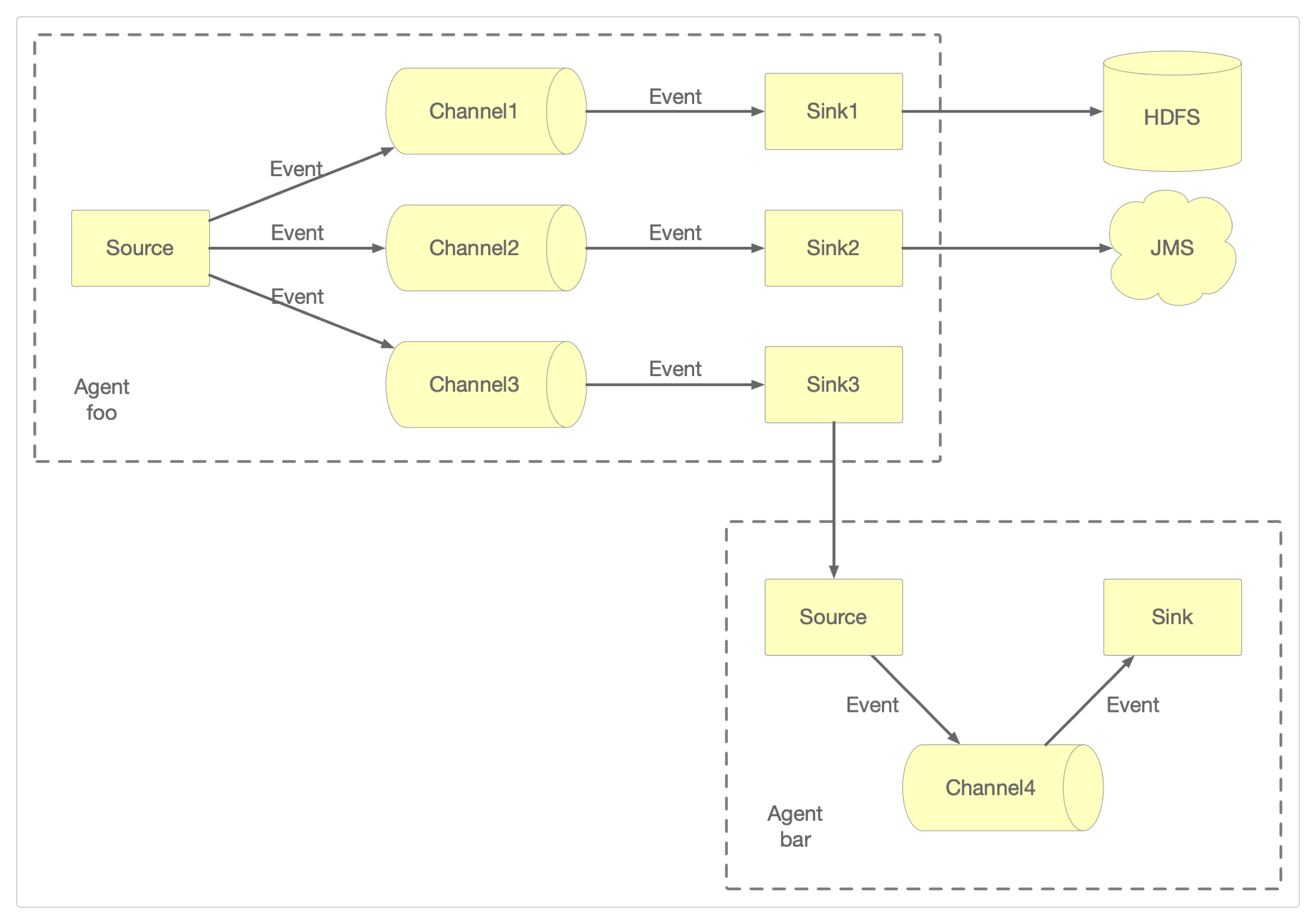
多路复用
通过定义流多路复用器,可以有选择性地将事件路由到一个或者多个Channel。
感谢支持
更多内容,请移步《超级个体》。