
Kafka高级特性
可以通过Kafka的配置文件server.properties来扩展它更多的高级功能。
Broker
server.properties中配置Broker的完整参数说明。
其中比较重要的有这么几个。
Log Flush Policy:设置数据的刷盘策略,它们都以log.flush.开头,其中又以log.flush.interval.messages和log.flush.interval.ms这两个比较关键。它们一个指定分区消息的刷盘阈值(也就是当某个分区积压了多少个消息时就将数据写到磁盘中去,server.properties中的默认值是10000),另一个指定刷盘的最大时间间隔,单位为毫秒(server.properties中的默认值是1000,也就是每秒写一次)。Log Retention Policy:设置数据的保存时长,它们都以log.retention.开头。在server.properties中设置了这几个参数:log.retention.hours=168、#log.retention.bytes=1073741824(未生效)和log.retention.check.interval.ms=300000。
Producer
server.properties中配置Producer的完整参数说明。
partitioner.class:根据用户设置的算法来计算将消息发送到哪个分区,默认是随机发送到不同的分区。acks:它决定数据的发送方式是同步(synchronous)还是异步(asynchronous)。它可以设置为三个值:-1、1和0,分别代表完全同步、半异步和完全异步,默认为1。
Consumer
server.properties中配置Consumer的完整参数说明。
group.id:用于指定消费者组,指定之后就要注意组内消费和组间消费之间的区别。
组内消费表示同一个group的消费者都可以消费同一份数据,但只有有一个消费者能真正消费数据,但要分情况。当
消费者数量<分区数量时,一个消费者可以消费多个分区的数据。当
消费者数量>分区数量时,多余的消费者不消费数据。所以对同一个消费者组而言,消费者的数量最好不要大于分区的数量,否则某些消费者将无法消费消息。
组间消费表示多个group可以消费相同Topic的数据,相互不影响。
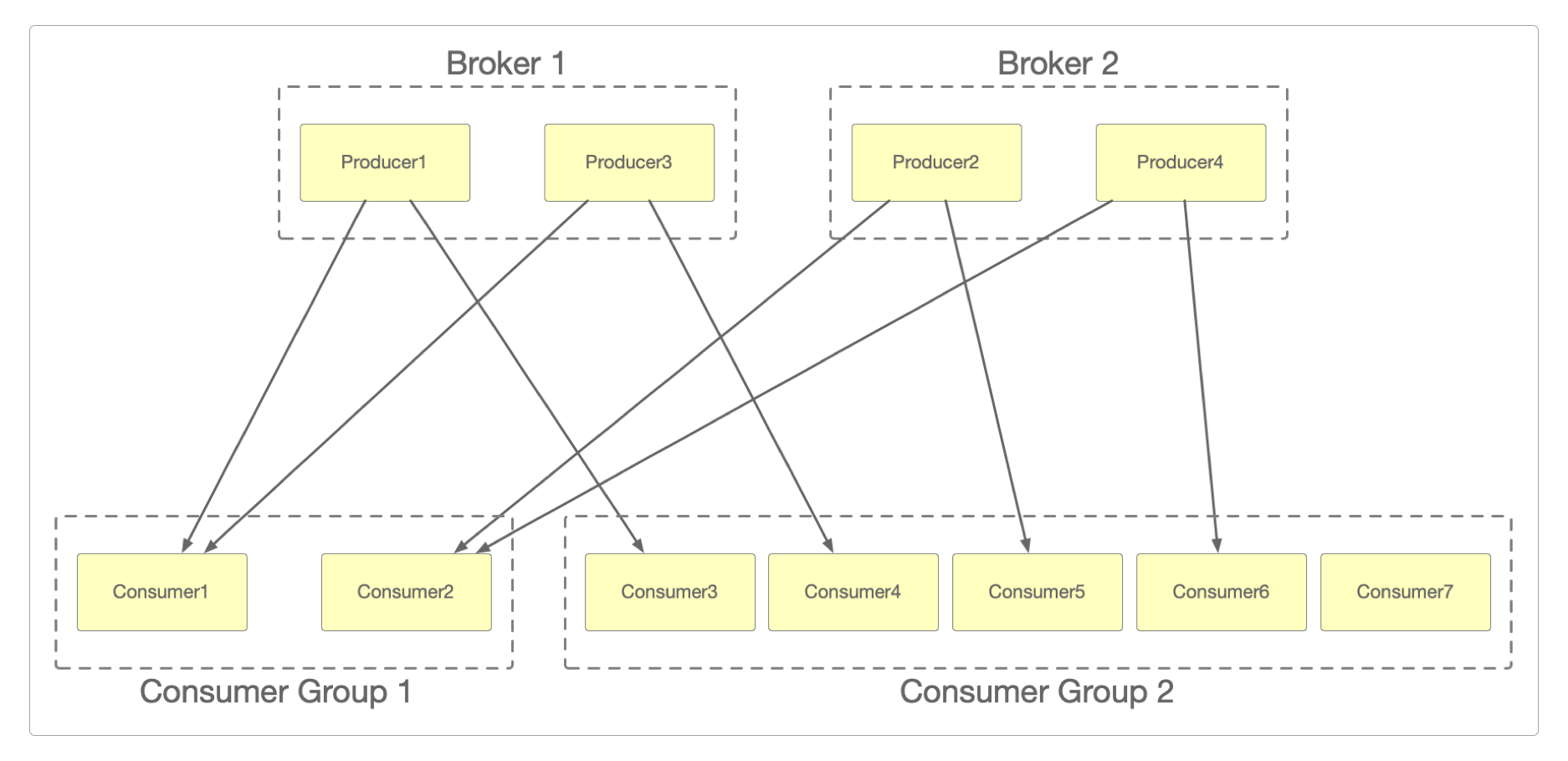
上图中有两个Broker和4个分区,以及两个消费者组:Consumer Group 1和Consumer Group 2。
它们分别展示了消费者数量 < 分区数量(Consumer Group 1)和消费者数量 > 分区数量(Consumer Group 2)时的组内消费情况,以及组间消费情况。
Topic、Partition和Message
server.properties中配置Topic的完整参数说明。
Topic对应于业务类型,如果有新的业务类型,就需要适当增加Topic。每个
Partition在物理存储上,都是一个Append Log文件,新消息会被直接追加到文件的尾部,而每条消息在文件中的位置称为Offset(偏移量)。Partition越多,能容纳的Consumer也就越多,能有效提升并发消费能力,在server.properties中默认的分区数量设置为1(num.partitions=1)。Partition对应于具体业务中的数据量,当数据量增大时,就要适当增加Partition的数量,实现对数据的分而治之。
每个
Message都对应一条具体的物理数据,它由Offset、MessageSize和data这三部分组成,分别表示偏移量、消息内容长度和消息数据。可以将Offset等同于唯一区分每一条不同Message的id。
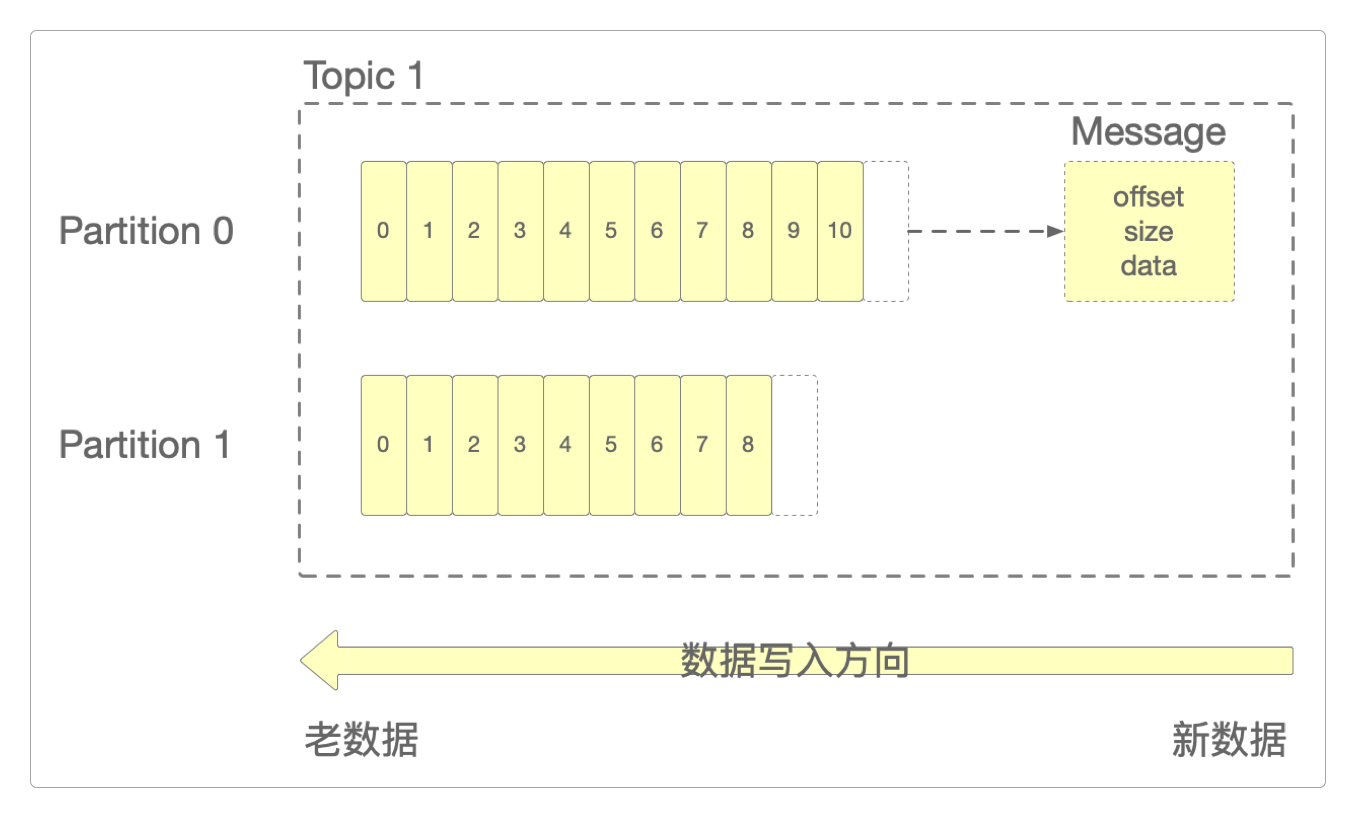
数据存取策略
通过Message的Offset快速查找数据时,Kafka会用到Segment(分段)和Index(索引)技术。
每个
Partition是由若干个不同的Segment组成,每个Segment又存储若干个Message。每个
Partition在内存中都会对应一个Index,Index中会记录每个Segment中第一条数据的Offset。
查询Offset信息
在Kafka0.9版本之前,消费者的Offset信息是保存在ZooKeeper中的。
在Kafka0.9版本开始,使用了新的消费者API,而消费者的Offset等信息会保存在server.properties配置文件设置过的log.dirs=/home/work/volumes/kafka/logs中,Kafka默认会创建50个预定义的__consumer_offsets-x文件夹(x的范围从0~49)。
通过Kafka提供的脚本可以查询消费者的Offset信息。
> cd /home/work/kafka_2.12-3.7.1
# 查看消费者组列表
> ./bin/kafka-consumer-groups.sh --list --bootstrap-server 172.16.185.176:9092
user1
user2
console-consumer-94645
# 查看某一个消费者组的详细信息
> ./bin/kafka-consumer-groups.sh --describe --bootstrap-server 172.16.185.176:9092 --group user2
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
user2 test 0 3 3 0
user2 test 1 5 5 0Consumer消费顺序
有以下发送数据、Topic、Partition和Consumer。
# 发送有序数据
1 2 3 4 5 6 7
# Topic
test
# 数据进入Partition的顺序(从左往右)
Partition-0:← 1 ← 3 ← 5 ← 7
Partition-1:← 2 ← 4 ← 6
# 消费者
消费者组A
Consumer-0
Consumer-1
消费者组B
Consumer-2- 当
Consumer和Partition是一一对应的时候,Consumer的消费顺序和Partition的生产顺序是一致的。
Consumer-0 消费 Partition-0的顺序:← 1 ← 3 ← 5 ← 7
Consumer-1 消费 Partition-1的顺序:← 1 ← 3 ← 5 ← 7- 当一个
Consumer消费多个Partition的时候,会轮流消费每个Partition中的数据。例如,会先从Partition1中消费一条数据,然后再从Partition2中消费一条数据,接着再回头消费Partition1的一条数据,哪个先到就消费哪个,这样轮番进行。
# 得到的结果是随机的,取决于Partition-0或Partition-1中的数据哪个先被Consumer-2消费
# 但对于每个Partition来说,Consumer-2消费它们的数据是有序的
Consumer-2 消费数据后的顺序:← 2 ← 1 ← 4 ← 3 ← 5 ← 7 ← 6所以要想实现生产数据的顺序和消费数据的顺序完全一致,只需要创建一个Partition和一个Consumer就行了,不过这样效率和性能都会大打折扣。
三种语义
从Consumer数据消费的结果来看,Kafka支持实现三种语义。
At-Least-Once:表示至少一次,它保证Consumer至少会消费一次数据,也可能会重复消费多次。At-Most-Once:表示至多一次,它保证Consumer最多只消费一次数据,有可能会丢失数据,这是Kafka默认的设置。Exactly-Once:表示精确一次,它保证Consumer仅消费一次数据,且数据不会丢失,它需要自己手动指定Partition和offset信息。
这三种不同的语义适用于不同的业务场景。
感谢支持
更多内容,请移步《超级个体》。