
Kafka集成Flume
原创大约 3 分钟
为了避免执行时不互相混淆,可以将Flume的conf目录拷贝多份,让每个Agent单独执行。
将数据写入Kafka
负责实时采集日志文件,将采集到的数据写入到Kafka。
> cd /home/work/flume-1.11.0
> mkdir conf-log-to-kafka
> cd conf-log-to-kafka
> vi log-to-kafka.conf
# 指定source和sink到channel
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/work/logs/user_api.log
# 配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = user_api_r1p2
a1.sinks.k1.kafka.bootstrap.servers = 172.16.185.176:9092
# 每次向kafka中写多少条数据,默认值为100,在这里为了演示方便,改为1
a1.sinks.k1.kafka.flumeBatchSize = 1
a1.sinks.k1.kafka.producer.acks = 1
# 表示一个Batch被创建之后,做多过多久,不管这个Batch有没有写满,都必须发送出去
# 这个参数和前面的flumeBatchSize哪个先满足就先按哪个规则执行,这个值默认是0
# 设置为1表示每隔1毫秒就将这一个Batch中的数据发送出去
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# 绑定source和sink到channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1从Kafka消费数据
> cd /home/work/flume-1.11.0
> mkdir conf-kafka-to-hdfs
> cd conf-kafka-to-hdfs
> vi kafka-to-hdfs.conf
# 指定source和sink到channel
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
# 这个值表示每次向channel中写入的最大数据条数
# 这个数值应该小于等于a1.channels.c1.transactionCapacity设置的值,否则会报错,无法写入数据
# 为了演示,将它设置为1
a1.sources.r1.batchSize = 1
# 多长时间向channel写一次数据
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = 172.16.185.176:9092
a1.sources.r1.kafka.topics = user_api_r1p2
a1.sources.r1.kafka.consumer.group.id = user_api
# 配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop:9000/kafka
a1.sinks.k1.hdfs.filePrefix = ue-
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# 绑定source和sink到channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动Agent
启动Agent之前要记得将两个配置目录中log4j2.xml里面的日志文件名改一下,不然log-to-kafka.conf和kafka-to-hdfs.conf日志会混在一起。
而且启动的是时候最好是从后往前启动。
也就是先启动从Kafka中读取数据并将它们写入到HDFS的服务。
> ./bin/flume-ng agent -n a1 -c conf-kafka-to-hdfs -f conf-kafka-to-hdfs/kafka-to-hdfs.conf
# 或者
> ./bin/flume-ng agent --name a1 --conf conf-kafka-to-hdfs --conf-file conf-kafka-to-hdfs/kafka-to-hdfs.conf再启动将从文件中读取到的日志数据写入到Kafka的服务。
> ./bin/flume-ng agent -n a1 -c conf-log-to-kafka -f conf-log-to-kafka/log-to-kafka.conf
# 或者
> ./bin/flume-ng agent --name a1 --conf conf-log-to-kafka --conf-file conf-log-to-kafka/log-to-kafka.conf启动之后稍微等个十几秒钟,然后到HDFS中查看是否有数据被写进来。
> hdfs dfs -cat /kafka/*也可以进到CMAK中查看相应Topic的分区数据。
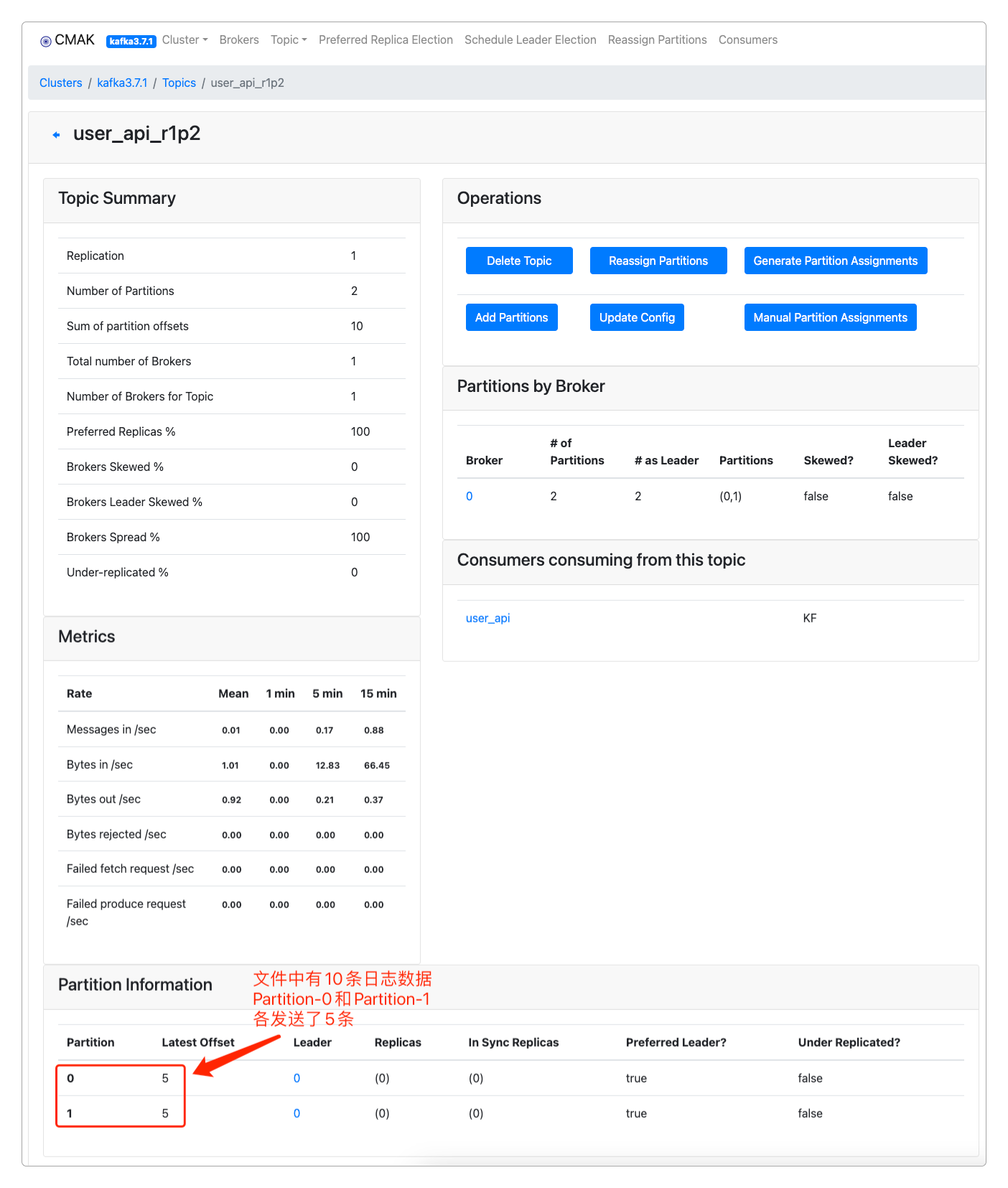
还可以模拟实时的日志文件录入。
> echo this is an new data >> /home/work/logs/user_api.log
# 再到hdfs中查看
> hdfs dfs -cat /kafka/*
this is an new data感谢支持
更多内容,请移步《超级个体》。