
服务消息积压处理
原创大约 3 分钟
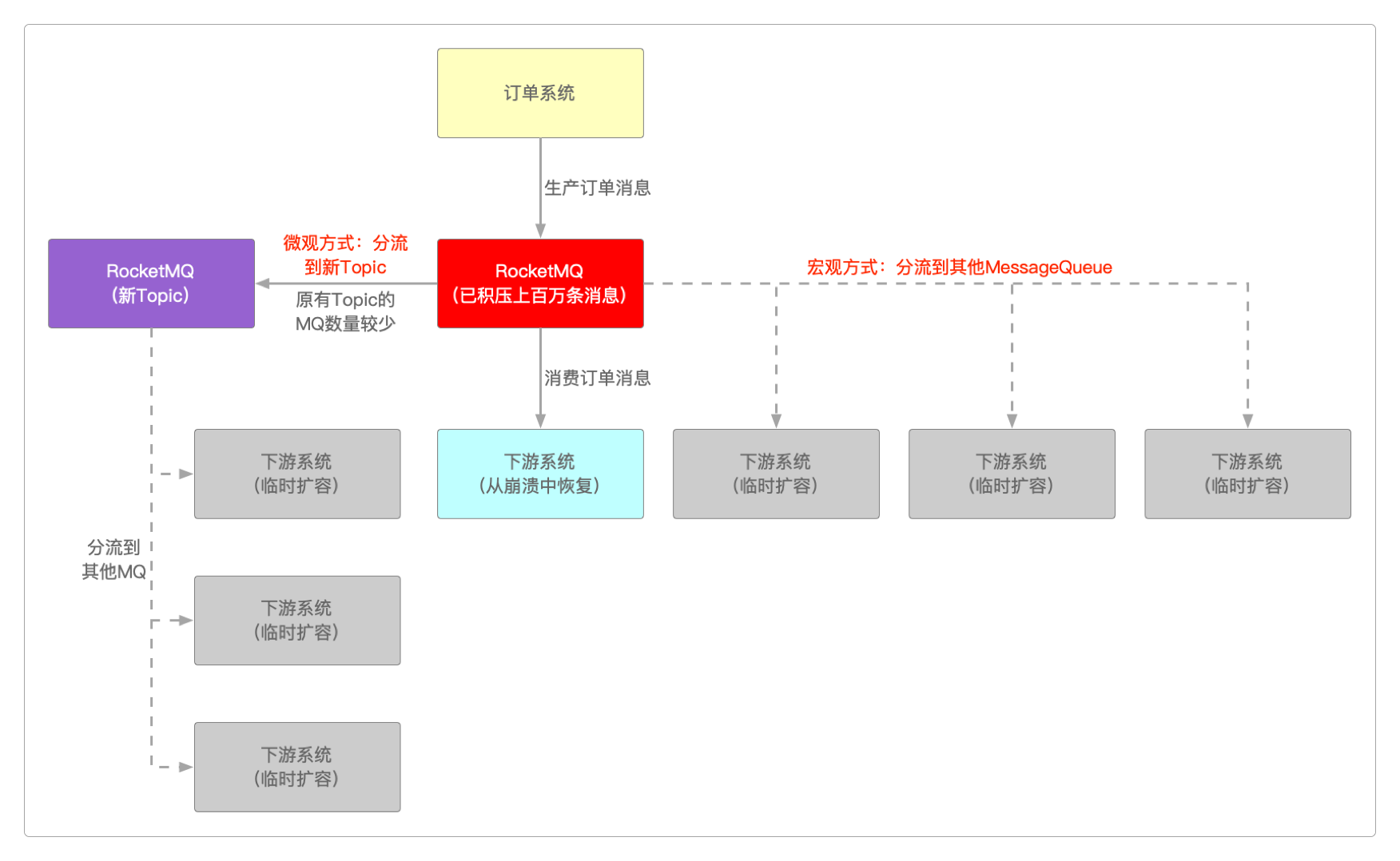
当RocketMQ的消费者终端崩溃而生产者依旧在不停地写入并发送消息时,就会产生消息积压问题。
如果仅仅只是几百上千,哪怕上万的消息积压,倒也不是什么问题,但如果积压的消息量一旦达到某个数量级,就会对RocketMQ和业务系统造成冲击。
可以通过宏观 + 微观结合的方式来解决这个问题。
所谓宏观的方式就是通过临时部署更多的机器来分流这么多的消息内容,让每台机器都在所能承受的流量压力范围内。当积压的服务消息都处理完后,就可再下线这些临时部署的机器。
这种方式要求Topic在创建时就显式地配置了较多的MessageQueue数量可用于分流,否则要么删除重新创建,要么就只能重新编译RocketMQ的源码,用Broker的配置信息覆盖defaultTopic的配置信息,但很明显,生产环境不可能这么做。
而微观的方式则是通过一种类似于管道的方法,变相地为RocketMQ和业务系统减压。使用这种方式是因为之前创建的Topic的MessageQueue数量有限,无法通过宏观的方式进行扩容。
首先,这种方式不会对消息做任何处理,而是仅仅只做中转,将它转发到另外的Topic中,这个新的Topic有较多的可用于分流的MessageQueue。
然后在新的Topic机器中再套用宏观的方式。
另外,作为消息生产者的订单系统,是需要提前准备好应对RocketMQ崩溃这种情况的,否则又会退化到一个订单系统应对十几个下游系统的情况。
可以通过这种下面这种方式来防止并应对RocketMQ崩溃的情况。
/**
* 支付订单伪代码
*
*/
@Transactional
public void payOrder() {
SendResult result = null;
try {
// 发送消息更新数据
result = producer.sendMessage(data);
if (null != result) {
// TODO Somthing...
}
} catch (Exception e) {
// 如果消息发送失败,就重试3次
for (int i = 0; i < 3; i++) {
// 重试发送消息
result = producer.sendMessage(data);
// 重试多次失败后抛出异常回滚本地事务
if (null == result) {
continue;
} else {
// TODO Somthing...
return;
}
}
// MQ已经彻底崩溃,将订单相关数据保存到本地磁盘或NoSQL中,一旦MQ恢复立即取出执行
// 可以按照ID或时间顺序来保存,总之,要有序
saveData2File(data, timestamp);
// saveData2Elasticsearch(data, timestamp)
}
}
......
/**
* 后台进程扫描伪代码
*
*/
public void handleSavedData() {
SendResult result = null;
// 定时任务线程池
ScheduledExecutorService scheduleService = Executors.newScheduledThreadPool(m);
// 异步执行任务,无需返回值
CompletableFuture.runAsync(() -> {
try {
// 先发送一个消息看看MQ是否已经恢复
result = producer.sendMessage("Are you OK ?");
if (null != result) {
// 从本地文件或者从NoSQL中读取数据
Data data = readDataFromFile(filePath);
// 将数据发送给MQ
result = producer.sendMessage(data);
if (null != result) {
// TODO Somthing...
}
}
} catch (InterruptedException e) {
// 这里依旧遵循消息发送失败重试的逻辑
for (int i = 0; i < 3; i++) {
// 重试发送消息
result = producer.sendMessage(data);
// 重试多次失败后抛出异常
if (null == result) {
continue;
} else {
// TODO Somthing...
return;
}
}
// MQ再次崩溃,因为数据之前已经保存过,所以这里不用再次保存
}, scheduleService
);
}从上面伪代码的逻辑结构中可以清楚地看到当RocketMQ崩溃时的应对方法,只是要注意写入和读取时的数据有序问题。