
异步I/O
大约 6 分钟
事件循环
'''
协程编码三要素:
1. 事件循环
2. 回调函数 :驱动生成器运行
3. I/O多路复用 :SELECT、EPOLL
asyncio是python用于解决异步I/O编程的一整套方案
'''
import asyncio
import time
from functools import partial
async def testAsync(*args):
print("this is a test for async")
# 同步阻塞的 time.sleep() 不能用于异步阻塞
# 可以通过循环执行10次来比较 time.sleep() 和 await asyncio.sleep(2)的差别
# time.sleep(2)
await asyncio.sleep(2)
print("test again")
return "lixingyun"
# 必须指定 future 参数,这个 future 就是调用 callback 的那个函数
# 如果回调函数有参数,那么参数必须放在前面,且必须通过 partial 函数封装后再调用
def callback(args, future):
print("callback ==>", future.result(), "another ==>", args)
if __name__ == "__main__":
# 开启事件循环,代替之前写过的 while...selector...
start = time.time()
loop = asyncio.get_event_loop()
# 执行协程代码
loop.run_until_complete(testAsync())
print("耗时:", time.time() - start) # 耗时: 2.001452922821045
# 如果使用 await asyncio.sleep(2) ,即使执行10次,耗时仍然是2秒
# 但如果使用 time.sleep(2),则会耗时20秒
start = time.time()
tasks = [testAsync() for i in range(2)]
loop.run_until_complete(asyncio.wait(tasks))
print("耗时:", time.time() - start) # 耗时: 2.001422166824341
# wait 和 gather 的区别在于
# gather 抽象级别更高,除了可以实现 wait 所有的功能,还可以实现分组
start = time.time()
group1 = [testAsync() for i in range(2)]
group2 = [testAsync() for i in range(2)]
# 两组一起执行
loop.run_until_complete(asyncio.gather(*group1, *group2))
print("耗时:", time.time() - start) # 耗时: 2.000610113143921
# 或者这样执行
start = time.time()
group3 = [testAsync() for i in range(2)]
group4 = [testAsync() for i in range(2)]
group3 = asyncio.gather(*group3)
group4 = asyncio.gather(*group4)
loop.run_until_complete(asyncio.gather(group3, group4))
print("耗时:", time.time() - start) # 耗时: 2.000826835632324
# 获取协程的返回值
# test_future = asyncio.ensure_future(testAsync()) 这条语句和下面的等效,用法也是一模一样
test_future = loop.create_task(testAsync())
# 当运行完成时执行指定的回调函数,不用显式地将 test_future 指定为参数,python会自动传递,类似于传递 self 一样
# 通过偏函数 partial 封装 callback 函数,将参数传递给 callback
# 所谓偏函数,是将所要承载的函数作为 partial 的第一个参数,原函数的各个参数依次作为 partial 函数后续的参数,除非使用关键字参数
test_future.add_done_callback(partial(callback, "wanglin")) # callback ==> lixingyun another ==> wanglin
loop.run_until_complete(test_future)
# 和线程的调用方法一致
print(test_future.result()) # lixingyun
# 取消协程的执行
start = time.time()
task1 = testAsync()
task2 = testAsync()
task3 = testAsync()
tasks = [task1, task2, task3]
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(asyncio.wait(tasks))
except KeyboardInterrupt as e:
all_tasks = asyncio.Task.all_tasks()
for task in all_tasks:
result = task.cancel()
print("cancel task ==>", result)
loop.stop()
# stop 之后要调用 run_forever 方法,否则抛异常
loop.run_forever()
finally:
loop.close()
print("耗时:", time.time() - start) # 耗时: 2.0014379024505615协程嵌套
因为官方文档的更新,之前的图例和协程嵌套代码在最新版本中已经找不到了,只在老版本的文档里才有。
这张图还是不错的,为防止被官方删掉,特意保存下来。
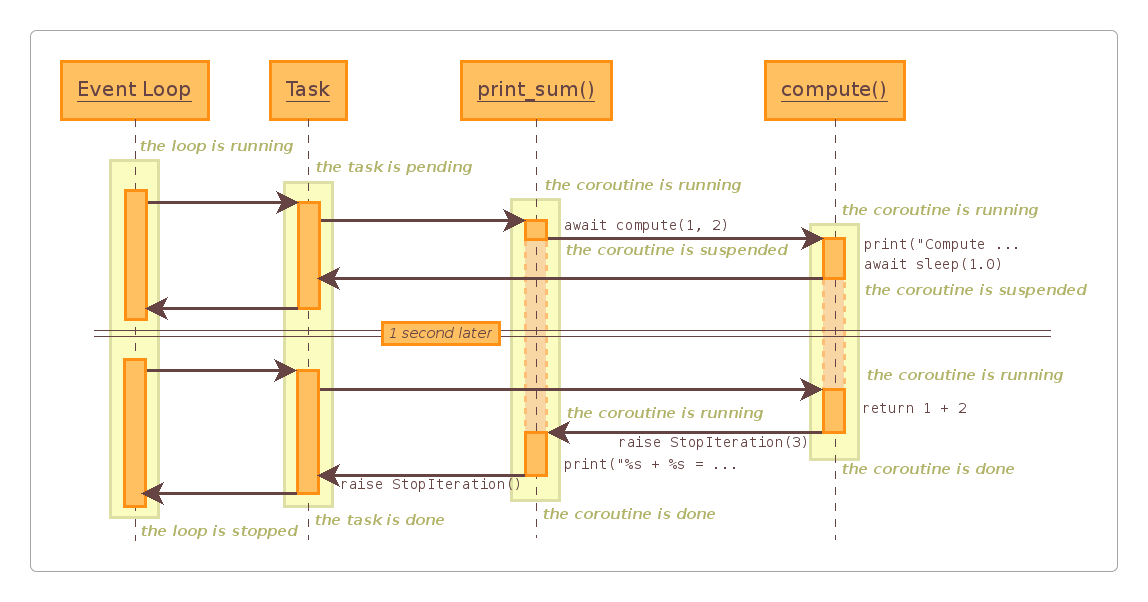
协程嵌套代码:https://docs.python.org/3.6/library/asyncio-task.html#example-chain-coroutines。
从上面的图中可以清楚地看到,它的执行过程是完全符合yield from的。
# 协程嵌套:https://docs.python.org/3.6/library/asyncio-task.html#example-chain-coroutines
import asyncio
import time
async def compute(x, y):
print("计算 %s + %s" % (x, y))
await asyncio.sleep(2)
return x + y
async def print_sum(x, y):
print("打印 %s + %s" % (x, y))
# 嵌套 compute 协程
result = await compute(x, y)
print("%s + %s = %s" % (x, y, result))
if __name__ == "__main__":
start = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
loop.close()
print("耗时:", time.time() - start) # 耗时: 2.000816822052002call_*
# call_*系列方法
import asyncio
def callback(method, sleep_times):
print(f"{method} ==> {sleep_times}")
if __name__ == '__main__':
loop = asyncio.get_event_loop()
# 这里不能使用 run_until_complete,因为 callback 方法不是一个协程
# call_later 的执行顺序并不是代码顺序,而是根据延迟调用的时间排序,越早的越先执行
# 延迟2秒后执行
loop.call_later(2, callback, "call_later", 2)
# 延迟1秒后执行
loop.call_later(1, callback, "call_later", 1)
# 延迟3秒后执行
loop.call_later(3, callback, "call_later", 3)
# 等到下一个循环时立即执行
loop.call_soon(callback, "call_soon", 5)
# 在指定的时间执行,它的执行顺序也和 call_later 一样
now = loop.time()
loop.call_at(now + 2, callback, "call_at", 2)
loop.call_at(now + 1, callback, "call_at", 1)
loop.call_at(now + 3, callback, "call_at", 3)
# 线程安全的 call_soon
loop.call_soon_threadsafe(callback, "call_soon_threadsafe", 2)
# 通过调用 stoploop 方法,可以停止 loop,否则它会一直执行下去
# 如果这里调用 loop.stop() 方法,那么 call_later 和 call_at 的方法都不会被执行
# loop.stop()
loop.run_forever()ThreadPoolExecutor
# 将线程池 ThreadPoolExecutor 和 asyncio 结合起来使用
import asyncio
import socket
import time
from urllib.parse import urlparse
from concurrent.futures import ThreadPoolExecutor
def get_html(url):
# 通过socket请求html
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = "/"
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 80))
client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf-8"))
data = b""
while True:
recv = client.recv(1024)
if recv:
data += recv
else:
break
data = data.decode("utf-8")
html_data = data.split("\r\n\r\n")[1]
print(html_data)
client.close()
if __name__ == "__main__":
start = time.time()
loop = asyncio.get_event_loop()
# 当线程数量与任务数量一致时,性能最好
executor = ThreadPoolExecutor(2)
results = []
for i in range(10):
url = "https://baike.baidu.com/item/{}".format(i)
# 在线程池中执行
result = loop.run_in_executor(executor, get_html, url)
results.append(result)
loop.run_until_complete(asyncio.wait(results))
print("耗时:", time.time() - start) # 耗时: 0.09127497673034668
# 查看以普通方式运行时的耗时
start = time.time()
for i in range(10):
url = "https://baike.baidu.com/item/{}".format(i)
get_html(url)
print("耗时:", time.time() - start) # 耗时: 0.5704450607299805模拟http请求
# 模拟 http 请求
import asyncio
import time
from urllib.parse import urlparse
async def get_html(url):
# 通过socket请求html
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = "/"
reader, writer = await asyncio.open_connection(host, 80)
writer.write("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf-8"))
# 读取数据
all_lines = []
async for raw_line in reader:
data = raw_line.decode("utf8")
all_lines.append(data)
html = "\r\n".join(all_lines)
return html
async def main(loop):
tasks = []
for i in range(20):
url = "https://baike.baidu.com/item/{}".format(i)
# 通过 ensure_future 方法获取返回值
tasks.append(asyncio.ensure_future(get_html(url)))
for task in asyncio.as_completed(tasks):
result = await task
print(result)
if __name__ == "__main__":
start = time.time()
loop = asyncio.get_event_loop()
tasks = []
for i in range(20):
url = "https://baike.baidu.com/item/{}".format(i)
# 通过 ensure_future 方法获取返回值
tasks.append(asyncio.ensure_future(get_html(url)))
loop.run_until_complete(asyncio.wait(tasks))
for task in tasks:
print(task.result())
print("耗时:", time.time() - start) # 耗时: 0.10125184059143066
# 执行一个打印一下的方式
start = time.time()
loop.run_until_complete(main(loop))
print("耗时:", time.time() - start) # 耗时: 0.09747982025146484同步和通信
'''
将需要线程锁的代码改用协程 async 来执行
'''
import asyncio
from asyncio import Lock, Queue
import aiohttp
counter = 0
cache = {}
'''
无需同步执行
'''
async def inc():
global counter
for i in range(1000000):
counter += 1
async def dec():
global counter
for i in range(1000000):
counter -= 1
'''
需要同步机制控制两个方法的执行
当一个方法执行 get_html 的时候
另一个需要被阻塞,等待锁释放后才能执行 get_html 方法
'''
lock = Lock()
queue = Queue()
# 使用 queue 在协程间通信的时候,同样需要加上 await
# await queue.put(1)
async def get_html(url):
# # 使用 acquire() 和 release()
# await lock.acquire()
# if url in cache:
# return cache[url]
# staff = await aiohttp.request('GET', url)
# cache[url] = staff
# lock.release()
# return staff
# 或者使用 with await lock / async with lock:
async with lock:
if url in cache:
return cache[url]
staff = aiohttp.request('GET', url)
cache[url] = staff
return staff
lock.release()
async def parse_html(url):
staff = await get_html(url)
print("从网络获取结果 ==>", staff)
await queue.put(staff)
return queue
async def use_html(url):
staff = await queue.get()
print("从队列拿到结果 ==>", staff)
return staff
if __name__ == '__main__':
tasks1 = [inc(), dec()]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks1))
# 不管执行多少次,结果总是正确的
print(counter) # 0
tasks2 = [asyncio.ensure_future(parse_html("http://www.baidu.com")),
asyncio.ensure_future(use_html("http://www.baidu.com"))]
loop.run_until_complete(asyncio.wait(tasks2))
for task in tasks2:
print(task.result())
loop.close()感谢支持
更多内容,请移步《超级个体》。