
流批一体大数据系统
大数据“范式”
目前已知的主流的大数据系统,在进行大数据相关应用开发时,都遵循三段论(如果包括上下文环境以及启动执行的话就是五段论)的编程范式。
Flink也遵循了这一点,因为它没有脱离Hadoop大数据的计算架构与生态体系。
| 大数据平台 | 初始化上下文 | 数据源(映射) | 执行算子逻辑 | 输出结果 |
|---|---|---|---|---|
| Hadoop | JobInstance | Map | Reduce | Output |
| Spark | Environment | RDD | Transformation | Action/Output |
| Flink | Environment | Source | Transformation | Sink |
如果用伪代码来表示的话就像是下面这样的。
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据 - Source
DataStreamSource<T> source = environment.addSource(...);
// 3. 处理数据 - Transformation
source.flatMap(...);
// 4. 输出数据 - Sink
source.addSink(...).print();
// 5. 启动任务 - Execute
environment.execute();只有Clickhouse另起炉灶,自成一派(它也是流批一体的)。
而所有大数据的算子,都可以利用Java函数式编程中流式编程的那一套,完全就是无缝迁移。
所以我在《Java深度探索:开发基础》的第5章 函数式编程里专门提到过,如果流式编程很熟练的话,搞大数据非常容易上手——不是几乎,而是瞬间秒懂。
所以说,基础很重要。
“流式”与“批式”
传统的大数据系统,例如Hadoop和HDFS,它们更加侧重于大数据的存储和同步,对于实时计算的支持比较有限。
所以它们处理的通常都是静态的数据集,例如几个GB(甚至是PB)的交通事件数据、天气变化数据、用户行为数据、实时生产数据等。而且它可以先处理过去的数据,再处理当前的数据。
对于这种大数据系统,可以说它是有界的。
所谓有界,就是一定会有绝对的起始和结束,因为哪怕这个静态的数据文件再大,哪怕是EB级别的文件,也一定存在绝对的开头和结尾。
这种大数据系统就被称为批式大数据系统,因为它处理的是一批批的文件。
在Hadoop之后,Spark和Flink相继出现,它们则引入了新的大数据处理方式:流式处理。之所以会出现新的流式处理,是因为互联网应用对大数据系统的实时性要求越来越高。
对于流来讲,它最大的特点就是无界,也就是没有明显的开始和结束时间点。例如,对于一场在线直播的演唱会来说,用户可以在任意一个时间点进去观看,也可以在任意一个时间点退出。这个进入和退出的时间点都不算流的开始和结束,但对于每一个用户来说又都是。
而且它只能处理当前的数据,无法回头去处理过去的数据。
所以流只有相对的开始和结束——即使它再小,即使只输入一个字符,只要它是以流的形式存在并且一直着持续的,那么都可以认为它是无界的。
这种能过够实时处理流的大数据系统也被称为流式大数据系统。
如果说Spark是介于批和流之间的话(对于Spark来说,流只是批的一种特例),那么Flink就是纯粹的流式大数据系统(Flink则刚好相反,批只是流的一种特例),Flink诞生的时间更晚,吸收借鉴的经验更多,所以它也更纯粹。
所以,对于Spark来说,一切皆是批;而对于Flink来说,一切皆是流。
以Flink为例,这种不同的数据处理方式也反映在代码的运行结果上。
/**
* 原始输入:bigdata,bigdata,flink,flink,clickhouse
*
*/
// 声明批式处理执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
......
// 批式处理运行后立即结束,结果为:
(flink,2)
(clickhouse,1)
(bigdata,2)
// 声明流式处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
......
// 流式处理会一直持续运行,结果为:
(bigdata,1)
(bigdata,2)
(flink,1)
(flink,2)
(clickhouse,1)仔细对比上面的结果就能发现批与流的不同:批结束后会立即汇总结果;而流因为没有边界,所以无法立即汇总结果。
API抽象
虽然Flink为批和流的开发提供了不同级别的抽象,整个Flink中最重要的几个概念也在下面这两层:Stateful Stream Processing和DataStream / DataSet API。
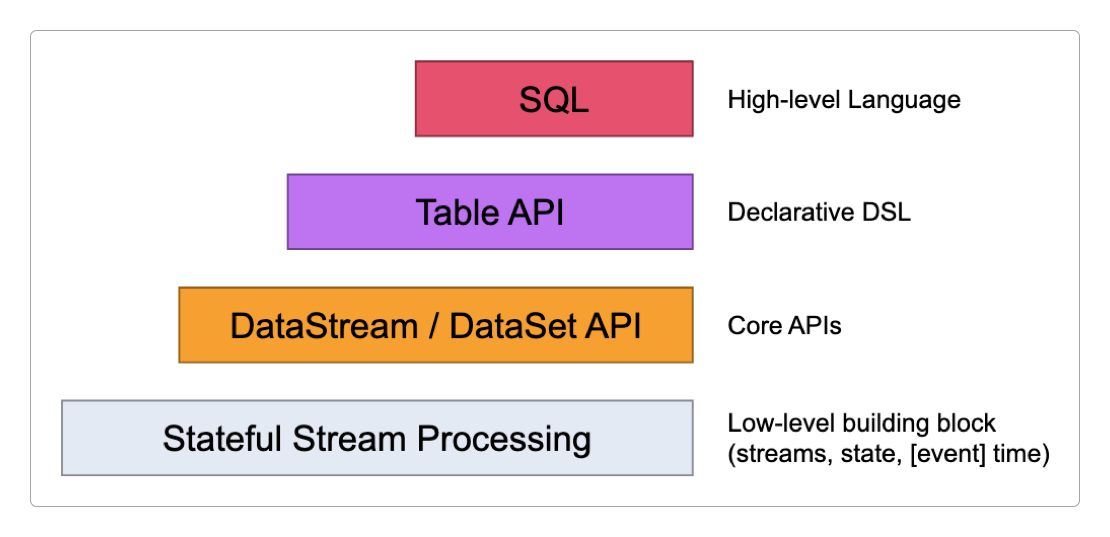
但Flink 1.14版本之后DataSet已经被废弃,和DataStream整合为一体。
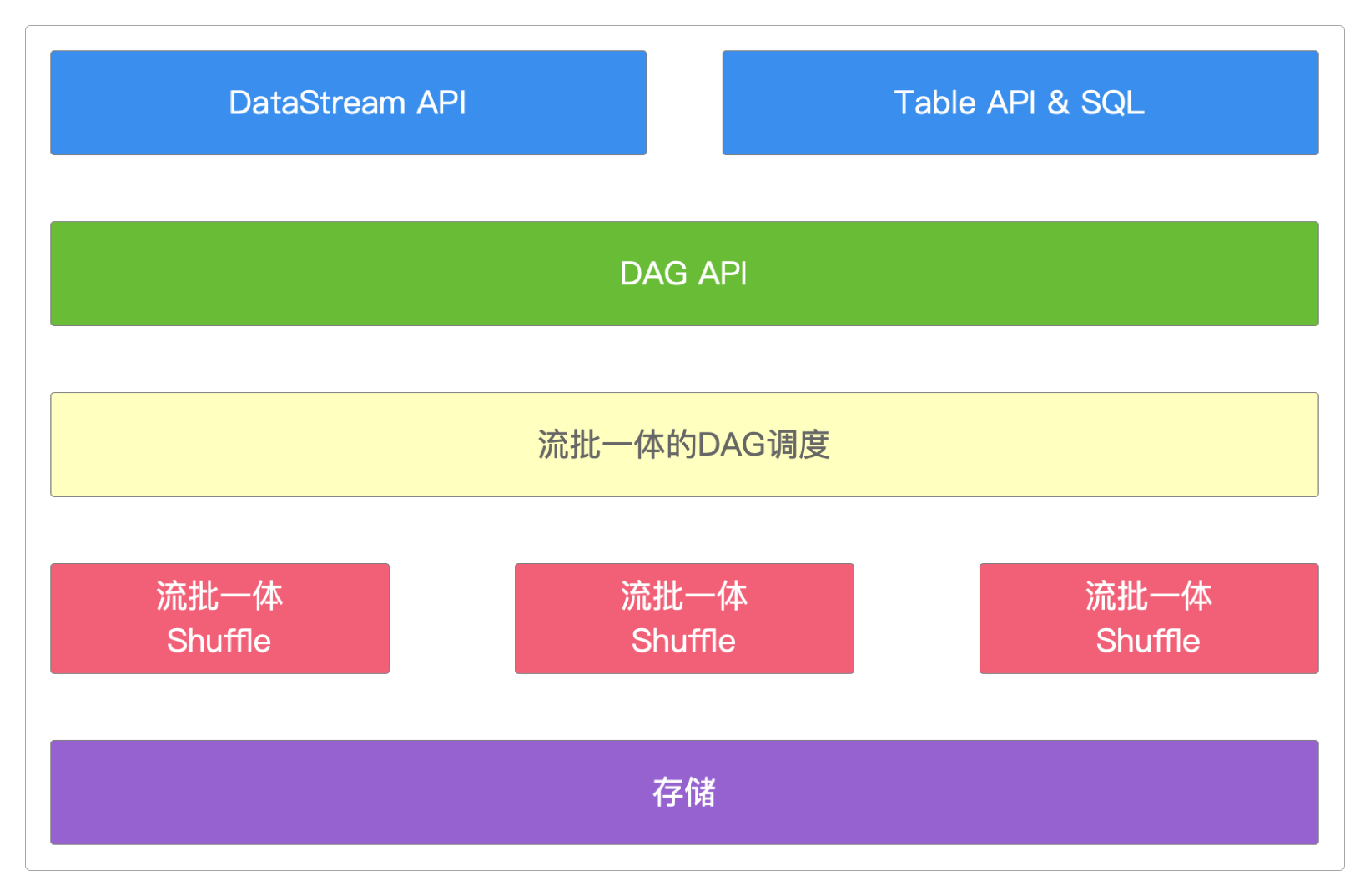
Flink之所以可以实现批流一体,是因为它有一套批流一体的调度模式:基于Pipeline Region的统一调度。
批流一体的API。批流一体的DAG调度。批流一体的Shuffle。批流一体的容错策略。
学习方法
其实,要想学好Flink并不难,只要善用下面这些免费资源就足够了。
官方教程指南
官方测试用例
安装部署
安装好Docker,然后执行下面的脚本。
version: '3.7'
services:
jobmanager:
image: flink:1.17.1-scala_2.12
command: jobmanager
ports:
- "8081:8081"
volumes:
- /home/work/volumes/flink/settings/:/settings
- /home/work/volumes/flink/data/:/data
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
restart: always
taskmanager:
image: flink:1.17.1-scala_2.12
command: taskmanager
depends_on:
- jobmanager
scale: 1
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager.numberOfTaskSlots: 8
volumes:
- /home/work/volumes/flink/settings/:/settings
- /home/work/volumes/flink/data/:/data
restart: always在浏览器中访问http://172.16.185.176:8081/就能看到Flinkjobmanager节点的基本信息。
作业提交
通过命令行提交作业后,可以再通过命令查看作业运行情况。
> ./bin/flink list -a进入运行work-jobmanager-1的Docker容器,以命令行启动两个测试作业。
./bin/flink run [-Dexecution.runtime-mode=BATCH] --detached -p 1 ./examples/streaming/StateMachineExample.jar
./bin/flink run [-Dexecution.runtime-mode=BATCH] --hostname localhost --port 9090 -p 1 org.apache.flink.streaming.examples.socket.SocketWindowWordCount ./examples/streaming/SocketWindowWordCount.jar然后在Flink提供的Web UI中观察。
或者,将Flink官方自带的测试作业拷贝下来。
> docker cp <容器ID>:/opt/flink/examples/ /usr/local/然后再手动上传到Web UI中测试也是一样。
关注公众号后回复 flink 即可获得Flink栏目剩余文章的访问密码。
