
连接器、触发器与驱逐器
连接器:Joining
Flink中的连接Joining,类似于SQL中的JOIN连接,它可以对来自不同的流中的数据进行计算,但是又有不同。官网在连接器中讲得比较清楚。
窗口连接器
窗口连接器将具有相同Key且在同一个窗口中的不同的流元素连接起来。这其中有三个关键字,也就是需要满足三个条件:相同Key、来自不同的流和在同一个窗口。
窗口连接器依据窗口本身的不同又分为三类。
- 滚动窗口连接器,当两个不同的流滚动窗口做连接时,会对流中的元素执行笛卡尔积运算。
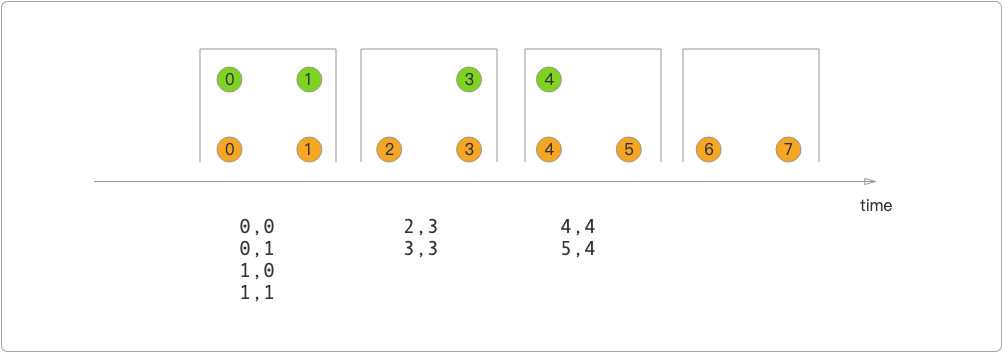
在滚动窗口连接器中,橙色和绿色是两种不同的数据流,在同一个窗口内,橙色的流作为左表,连接的结果就是两个流的笛卡尔积。
- 滑动窗口连接器,和滚动窗口一样,唯一不同的是结果会受到事件时间的影响。
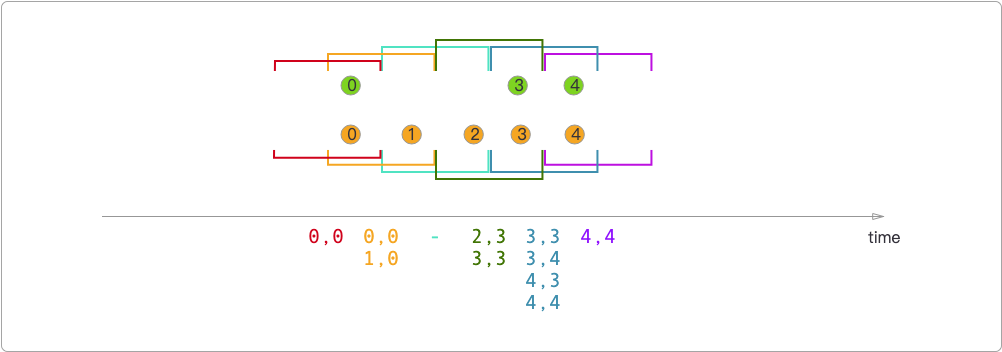
而在滑动窗口连接器中,只有0和0,所以结果是[0, 0];而在红色和橙色窗口的重叠部分,结果是[0, 0]和[1, 0]。其他窗口的结果依此类推。
- 会话窗口连接器,结果取决于会话状态,在同一个会话中对不同的数据流进行连接。
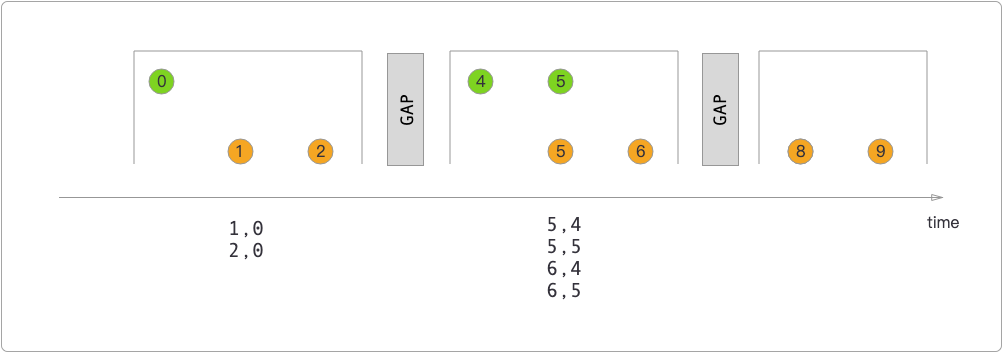
下面是通过代码模拟滚动窗口连接器的结果。
先引入依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.1</version>
</dependency>编写示例代码。
package itechthink.joining;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichJoinFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
/**
* 滚动窗口连接器
*
*/
public class TumblingWindowJoiningJob {
public static void main(String[] args) {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
/*
* 绿色流
*
*/
SingleOutputStreamOperator<Tuple2<Integer, Integer>> greenStream = environment.fromElements(
"1,0",
"1,1",
"6,3",
"11,4"
)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(Integer.parseInt(split[0]), Integer.parseInt(split[1]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<Integer, Integer>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<Integer, Integer>>() {
@Override
public long extractTimestamp(Tuple2<Integer, Integer> element, long record) {
return element.f0;
}
}
)
);
/*
* 橙色流
*
*/
SingleOutputStreamOperator<Tuple2<Integer, Integer>> orangeStream = environment.fromElements(
"1,0",
"1,1",
"6,2",
"6,3",
"11,4",
"11,5",
"16,6",
"16,7"
)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(Integer.parseInt(split[0]), Integer.parseInt(split[1]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<Integer, Integer>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<Integer, Integer>>() {
@Override
public long extractTimestamp(Tuple2<Integer, Integer> element, long record) {
return element.f0;
}
}
)
);
/*
* 数据格式:时间戳,数据
*
* 绿色流输入:
* 第1个5秒:(1, 0), (1, 1)
* 第2个5秒:(6, 3)
* 第3个5秒:(11, 4)
* 第4个5秒:无数据
*
* 橙色流输入:
* 第1个5秒:(1, 0), (1, 1)
* 第2个5秒:(6, 2), (6, 3)
* 第3个5秒:(11, 5), (11, 5)
* 第4个5秒:(16, 6), (16, 7)
*
* 输出结果:
* (0,0)
* (0,1)
* (1,0)
* (1,1)
* (4,4)
* (5,4)
* (2,3)
* (3,3)
*/
orangeStream.join(greenStream)
.where(new KeySelector<Tuple2<Integer, Integer>, Integer>() {
@Override
public Integer getKey(Tuple2<Integer, Integer> input) throws Exception {
return input.f0;
}
})
.equalTo(new KeySelector<Tuple2<Integer, Integer>, Integer>() {
@Override
public Integer getKey(Tuple2<Integer, Integer> input) throws Exception {
return input.f0;
}
})
// 滚动窗口大小5秒
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//.apply((left, right) -> Tuple2.of(left.f1, right.f1))
.apply(new RichJoinFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> join(Tuple2<Integer, Integer> left, Tuple2<Integer, Integer> right) throws Exception {
return Tuple2.of(left.f1, right.f1);
}
})
.print().setParallelism(1);
// 5. 启动任务 - Execute
try {
environment.execute("TumblingWindowJoinJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}代码运行之后可以看到,结果正如官方给出来的那样。
区间连接器
区间连接器的作用与窗口类似,也是将相同Key和来自不同流的数据连接在一起。但它的不同在于:两个流中的元素的时间戳是相对的。
官方画的图也比较清楚地解释了这一点。
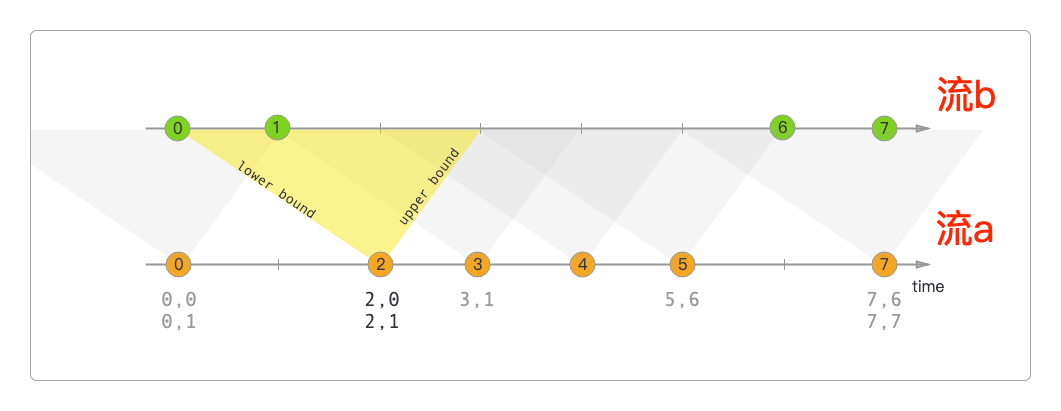
上面这张图可以更形象地表示为下面的数学公式。
b.timestamp ∈[a.timestamp + 下限, a.timestamp + 上限]
或者是:
a.timestamp + 下限 <= b.timestamp <= a.timestamps + 上限
注意
区间连接器只能使用事件时间。
它的时间区间两边都是闭合的,不像窗口那样
左闭右开(但可以用loerBoundExclusive()和opperBoundExclude()这两个方法来改变)。
下面用代码来实现区间连接器。
package itechthink.joining;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* 区间连接器
*
*/
public class IntervalJoiningJob {
public static void main(String[] args) {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
/*
* 绿色流(b流)
*
*/
SingleOutputStreamOperator<Tuple2<Integer, Integer>> greenStream = environment.fromElements(
"-5,0",
"0,1",
"25,6",
"30,7"
)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(Integer.parseInt(split[0]), Integer.parseInt(split[1]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<Integer, Integer>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<Integer, Integer>>() {
@Override
public long extractTimestamp(Tuple2<Integer, Integer> element, long record) {
return element.f0;
}
}
)
);
/*
* 橙色流(a流)
*
*/
SingleOutputStreamOperator<Tuple2<Integer, Integer>> orangeStream = environment.fromElements(
"-5,0",
"5,2",
"10,3",
"15,4",
"20,5",
"30,7"
)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple2.of(Integer.parseInt(split[0]), Integer.parseInt(split[1]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<Integer, Integer>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<Integer, Integer>>() {
@Override
public long extractTimestamp(Tuple2<Integer, Integer> element, long record) {
return element.f0;
}
}
)
);
/*
* 数据格式:时间戳,数据
*
* 绿色流(b流)输入:
* 第-5秒:(-5, 0)
* 第0秒:(0, 1)
* 第25秒:(25, 6)
* 第30秒:(30, 7)
*
* 橙色流(a流)输入:
* 第-5秒:(-5, 0)
* 第5秒:(5, 2)
* 第10秒:(10, 3)
* 第15秒:(15, 4)
* 第20秒:(20, 5)
* 第30秒:(30, 7)
*
* 输出结果:
* 完全按照官方的指南写出来的代码,却得不到结果,这是不是又一个bug?
*/
orangeStream
.keyBy(new KeySelector<Tuple2<Integer, Integer>, Integer>() {
@Override
public Integer getKey(Tuple2<Integer, Integer> input) throws Exception {
return input.f0;
}
})
.intervalJoin(
greenStream.keyBy(new KeySelector<Tuple2<Integer, Integer>, Integer>() {
@Override
public Integer getKey(Tuple2<Integer, Integer> input) throws Exception {
return input.f0;
}
})
)
.between(Time.seconds(-10), Time.seconds(5))
.process(new ProcessJoinFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>>() {
@Override
public void processElement(Tuple2<Integer, Integer> left,
Tuple2<Integer, Integer> right,
Context context,
Collector<Tuple2<Integer, Integer>> output) throws Exception {
output.collect(Tuple2.of(left.f1, right.f1));
}
})
.print().setParallelism(1);
// 5. 启动任务 - Execute
try {
environment.execute("IntervalJoiningJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}触发器:Triggers
触发器可以触发函数执行预定的行为。
官方的介绍比较简单,可以拿一个例子来说明。
每个景点都有摆渡车,只要满足下面两个条件中的任意一个,摆渡车就出发。
游客满了,例如一辆摆渡车最多坐满10人。
时间到了,每辆摆渡车最多等待15分钟,时间一到,不管有没有游客,它都会出发。
package itechthink.triggers;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.Trigger;
import org.apache.flink.streaming.api.windowing.triggers.TriggerResult;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import java.time.Duration;
/**
* 景点摆渡车触发器,满足任意一种情形,摆渡车就出发:
* 1. 游客满了,约定一辆摆渡车最多坐满3人(测试方便)
* 2. 时间到了,每辆摆渡车最多停留5秒(测试方便)
*
*/
public class ShuttleTriggerJob {
// 摆渡车最大人数
private static final int MAX_CAPACITY = 3;
// 摆渡车最多停留时间
private static final int MAX_DURATION = 5;
public static void main(String[] args) {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
environment.socketTextStream("localhost",9528)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple3<Long, String, String>>() {
@Override
public Tuple3<Long, String, String> map(String input) throws Exception {
String[] split = input.split(",");
return Tuple3.of(Long.parseLong(split[0].trim()), split[1].trim(), split[2].trim());
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<Long, String, String>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<Long, String, String>>() {
@Override
public long extractTimestamp(Tuple3<Long, String, String> input, long record) {
return input.f0;
}
}))
.keyBy(x -> x.f1)
// 每辆摆渡车最多停留5秒
.window(TumblingEventTimeWindows.of(Time.seconds(MAX_DURATION)))
.trigger(new Trigger<Tuple3<Long, String, String>, TimeWindow>() {
private ReducingStateDescriptor<Integer> reducingStateDescriptor = new ReducingStateDescriptor<Integer>("reducing", new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer t1, Integer t2) throws Exception {
return t1 + t2;
}
}, Integer.class);
/**
* 窗口中每进入一个元素,就计算一次
*
* @param element 进入的元素
* @param timestamp 元素到达的时间
* @param window 元素添加到窗口的实例
* @param context 触发器的上下文信息
*
* @return 窗口触发方法返回结果的类型TriggerResult
* TriggerResult.CONTINUE :不进行操作,等待
* TriggerResult.FIRE :触发计算且数据保留
* TriggerResult.PRUGE :窗口内部数据清除且不触发计算
* TriggerResult.FIRE_AND_PURGE :触发计算并清除对应的数据
*
* 按人数输入数据:
* 1000,car1,test1
* 1000,car1,test2
* 1000,car1,test3
* 输出结果:
* 已坐满游客,准备出发...
* 摆渡车窗口开始时间:0 窗口结束时间:5000
* (3000,car1,test1)
*
* 按时间输入数据:
* 1000,car1,test1
* 5000,car1,test2
* 输出结果:
* 已到发车时间,准备出发...
* 摆渡车窗口开始时间:0 窗口结束时间:5000
* (1000,car1,test1)
*/
@Override
public TriggerResult onElement(Tuple3<Long, String, String> element, long timestamp, TimeWindow window, TriggerContext context) throws Exception {
// 基于事件时间处理
context.registerEventTimeTimer(window.maxTimestamp());
ReducingState<Integer> reducingState = context.getPartitionedState(reducingStateDescriptor);
if (null == reducingState.get()) {
reducingState.add(1);
return TriggerResult.CONTINUE;
} else {
int count = reducingState.get();
// 因为初始化时已经+1,所以这里要再减回来
if (count < MAX_CAPACITY - 1) {
reducingState.add(1);
return TriggerResult.CONTINUE;
}
System.out.println("已坐满游客,准备出发...");
System.out.println("摆渡车窗口开始时间:" + window.getStart() + " 窗口结束时间:" + window.getEnd());
reducingState.clear();
return TriggerResult.FIRE_AND_PURGE;
}
}
/**
* 计时触发:处理时间
*
* @param timestamp 触发器触发时间
* @param window 元素添加到Window对象实例
* @param context 触发器的上下文信息
*
*/
@Override
public TriggerResult onProcessingTime(long timestamp, TimeWindow window, TriggerContext context) throws Exception {
return TriggerResult.CONTINUE;
}
/**
* 计时触发:事件时间
*
* @param timestamp 触发器触发时间
* @param window 素添加到Window对象实例
* @param context 触发器的上下文信息
*
*/
@Override
public TriggerResult onEventTime(long timestamp, TimeWindow window, TriggerContext context) throws Exception {
System.out.println("已到发车时间,准备出发...");
System.out.println("摆渡车窗口开始时间:" + window.getStart() + " 窗口结束时间:" + window.getEnd());
return TriggerResult.FIRE_AND_PURGE;
}
@Override
public void clear(TimeWindow window, TriggerContext context) throws Exception {
context.getPartitionedState(reducingStateDescriptor).clear();
context.deleteProcessingTimeTimer(window.maxTimestamp());
}
})
.sum(0)
.print().setParallelism(1);
// 5. 启动任务 - Execute
try {
environment.execute("ShuttleTriggerJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}驱逐器:Evitors
除了连接器和触发器 外,还有驱逐器——它可以在执行函数之前或之后从窗口中删除指定的元素。
CountEvictor,数量驱逐器,在窗口中保留指定数量的元素,并丢弃从窗口缓冲区头部的剩余元素。DeltaEvictor,阈值驱逐器,计算窗口中最后一个元素与其余元素之间的增量,丢弃增量大于或等于阈值的元素。TimeEvictor,时间驱逐器,保留窗口中最近一段时间内的元素,并丢弃其余元素。
但经过实际验证,好像并不像文档中所说的那样。
package itechthink.evictors;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.evictors.CountEvictor;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* 清除元素
*
*/
public class ListEvictorJob {
public static void main(String[] args) {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
environment.socketTextStream("localhost",9528)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple3<Long, String, String>>() {
@Override
public Tuple3<Long, String, String> map(String input) throws Exception {
String[] split = input.split(",");
return Tuple3.of(Long.parseLong(split[0].trim()), split[1].trim(), split[2].trim());
}
})
// .assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<Long, String, String>>forBoundedOutOfOrderness(Duration.ZERO)
// .withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<Long, String, String>>() {
// @Override
// public long extractTimestamp(Tuple3<Long, String, String> input, long record) {
// return input.f0;
// }
// }))
.keyBy(x -> x.f1)
.window(TumblingProcessingTimeWindows.of(Time.milliseconds(5)))
/*
* 要求只保留3个,但好像并没有执行
*
* 输入:
* 1000,test,1
* 2101,test,2
* 3022,test,3
* 4003,test,4
* 5000,test,5
* 6000,test,6
* 7000,test,7
* 8000,test,8
* 9000,test,9
* 10000,test,10
* 11000,test,11
* 输出:
* (21126,test,1) <-- 这个应该是 1000 ~ 6000 相加的结果
* (45000,test,7) <-- 这个应该是 7000 ~ 11000 相加的结果
*/
.evictor(CountEvictor.of(3, true))
.sum(0)
.print().setParallelism(1);
// 5. 启动任务 - Execute
try {
environment.execute("ListEvictorJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}从代码运行结果来看,evictor()完全没起作用,它并未驱逐任何元素。
可能是对它还有误解,官方的介绍也不多,所以先跳过。
感谢支持
更多内容,请移步《超级个体》。