
Table API & SQL
原创大约 10 分钟
编程范式
和之前的流式大数据处理一样,在Flink中,所有用于批和流的Table API & SQL也都遵循相同的编程范式,也就是代码上的整体结构都基本上同。
package itechthink.table;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.datagen.table.DataGenConnectorOptions;
import org.apache.flink.table.api.*;
/**
* Table API & SQL编程范式
*
*/
public class TableApiAndSQLParadigm {
public static void main(String[] args) throws Exception {
// 1. 创建批或流执行的Table上下文环境
Configuration configuration = new Configuration();
TableEnvironment tableEnv = TableEnvironment.create(configuration);
// 2.1. 创建数据源表
tableEnv.createTemporaryTable("SourceTable", TableDescriptor.forConnector("datagen")
.schema(Schema.newBuilder()
.column("f0", DataTypes.STRING())
.build())
.option(DataGenConnectorOptions.ROWS_PER_SECOND, 100L)
.build());
// 2.2. 或者,从Table API查询中创建一个Table对象
Table table1 = tableEnv.from("SourceTable");
// 2.3. 或者,从SQL查询中创建一个Table对象
Table table2 = tableEnv.sqlQuery("SELECT * FROM SourceTable");
// 3.1. 创建一张保存结果的Sink数据表
tableEnv.executeSql("CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE SourceTable (EXCLUDING OPTIONS) ");
// 3.2. 或者,将查询结果保存到Sink数据表
TableResult tableResult1 = table1.insertInto("SinkTable").execute();
TableResult tableResult2 = table2.executeInsert("SinkTable");
}
}参考的比较多的是这两份文档。
为了方便,下面都以 TAS 来代替 Table API & SQL。
连续查询
官方对于连续查询的说明:连续查询中的动态表
关于连续查询,官方画出来的图把意思描述得非常精准。
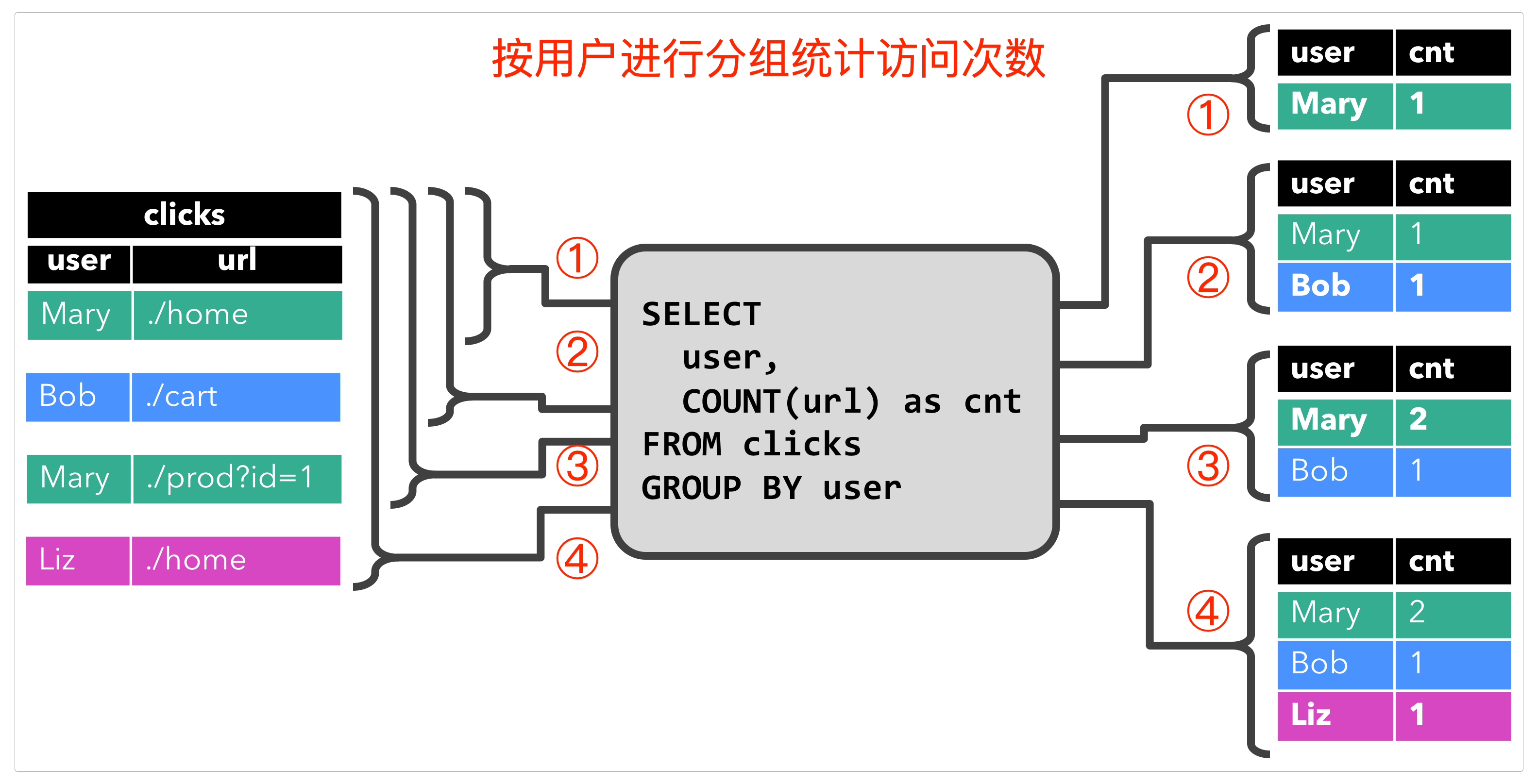
当用户
Mary点击了./home链接时,产生了第一条记录。然后用户
Bob也点击了某条链接。当用户
Mary再次点击了某条链接时,右边的统计结果也更新了。依此类推。
如果要算上时间,例如,每小时统计一次结果的话,就会是下面这样。
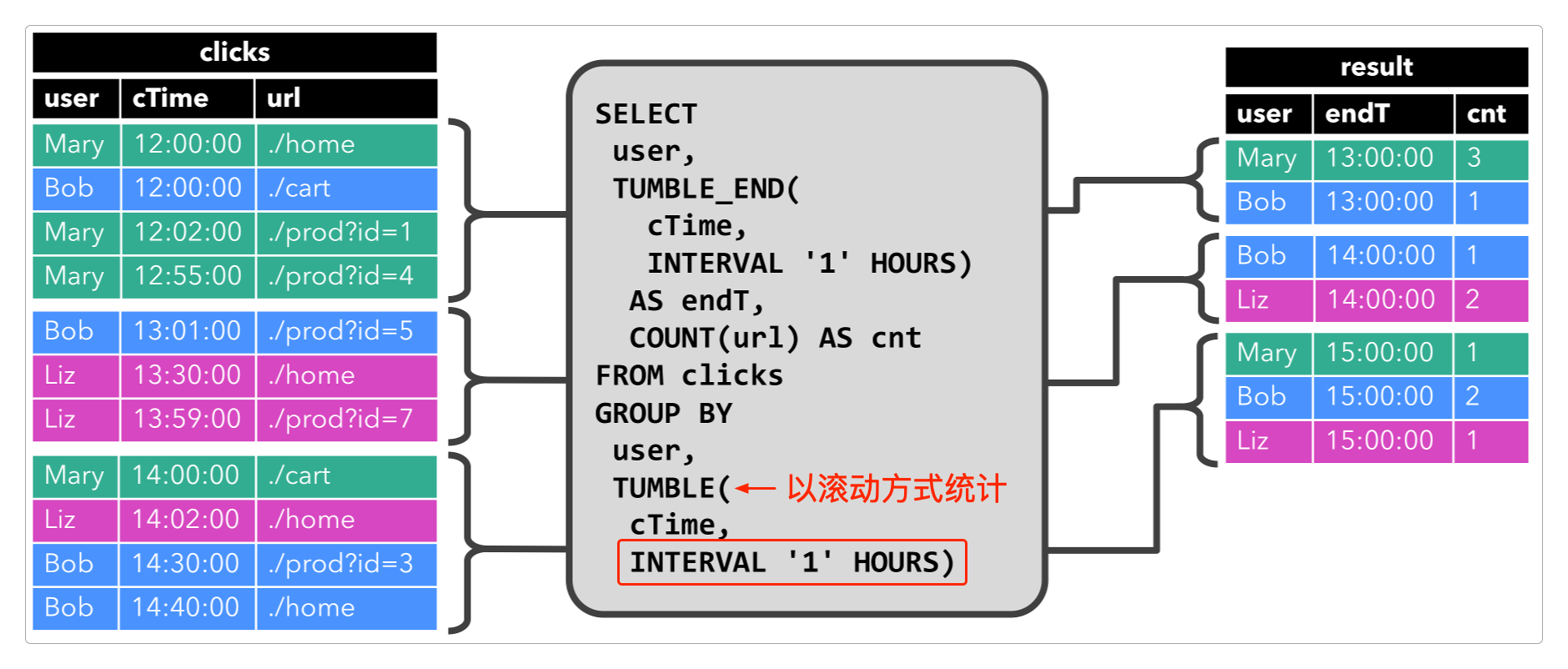
上面这两张表都是动态表,也就是说它们的数据不断累加的,而且因为它是基于流的,所以始终无法查询完。
简单样例
先引入依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>1.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.17.1</version>
</dependency>样例代码。
package itechthink.table;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.*;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.$;
/**
* Table API & SQL的简单例子
* (Flink 1.17.1 + Flink Table Planner_2.12 1.17.1 + Flink Table API Java Bridge 1.17.1 + Flink JSON 1.17.1)
*
*/
public class TableApiSQLSimpleJob {
public static void main(String[] args) throws Exception {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment);
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
// 2. 读取数据 - Source
SingleOutputStreamOperator<Tuple3<Integer, String, Integer>> stream = environment.socketTextStream("localhost", 9528)
// 3. 处理数据 - Transform
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, Tuple3<Integer, String, Integer>>() {
@Override
public Tuple3<Integer, String, Integer> map(String s) throws Exception {
String[] split = s.split(",");
return new Tuple3<>(Integer.parseInt(split[0]), split[1], Integer.parseInt(split[2]));
}
});
// tableApiSelect(stream, tableEnvironment);
// tableSqlSelect(stream, tableEnvironment);
tableExecuteSql(stream, tableEnv);
// 5. 启动任务 - Execute
environment.execute("SimpleTableApiSQLJob");
}
/**
* 通过Table API读取数据
*
*/
private static void tableApiSelect(SingleOutputStreamOperator<Tuple3<Integer, String, Integer>> stream,
StreamTableEnvironment tableEnvironment) {
// 将DataStream转换成Table
Table table = tableEnvironment.fromDataStream(stream,
// 因为没有用JavaBean,所以只能以Tuple的fx方式来表示字段名称
// 如果用JavaBean,那就是其中成员变量的名字
Schema.newBuilder()
.column("f0", DataTypes.INT())
.column("f1", DataTypes.STRING())
.column("f2", DataTypes.INT())
.build());
// 查询数据
// 等价于:SELECT f0, f1, f2 FROM TABLE WHERE f0 = 1 AND f2 >= 10
Table result = table.select($("f0"), $("f1"), $("f2"))
.where($("f0").isEqual(1)
.and($("f2").isGreaterOrEqual(10)));
// 4. 输出结果 - Sink
// 将Table转换成DataStream
tableEnvironment.toDataStream(result, Row.class).print().setParallelism(1);
}
/**
* 通过Table SQL读取数据
*
*/
public static void tableSqlSelect(SingleOutputStreamOperator<Tuple3<Integer, String, Integer>> stream,
StreamTableEnvironment tableEnvironment) throws Exception {
// 将DataStream转换成Table
Table table = tableEnvironment.fromDataStream(stream,
// 因为没有用JavaBean,所以只能以Tuple的fx方式来表示字段名称
// 如果用JavaBean,那就是其中成员变量的名字
Schema.newBuilder()
.column("f0", DataTypes.INT())
.column("f1", DataTypes.STRING())
.column("f2", DataTypes.INT())
.build());
tableEnvironment.createTemporaryView("t_user", table);
// 查询数据
Table result = tableEnvironment.sqlQuery("SELECT * FROM t_user WHERE f0 = 1;");
// 4. 输出结果 - Sink
// 将Table转换成DataStream
tableEnvironment.toDataStream(result, Row.class).print().setParallelism(1);
}
/**
* 通过TableEnvironment更新和查询数据
* 新版本的UPDATE语句仅支持批模式,无法使用StreamTableEnvironment,只用使用TableEnvironment
*
* 数据可以正确地保存到Kafka里去
* 但执行查询 tableEnv.executeSql("SELECT...") 会抛出异常:
* org.apache.flink.table.api.ValidationException: Querying an unbounded table 'default_catalog.default_database.t_department' in batch mode is not allowed. The table source is unbounded.
* 原因貌似是因为TableEnvironment不能使用使用批模式,而如果改用流模式,也会抛出异常:
* [SourceCoordinator-Source: t_department[3]] ERROR org.apache.flink.runtime.source.coordinator.SourceCoordinatorContext - Exception while handling result from async call in SourceCoordinator-Source: t_department[3]. Triggering job failover.
* 所以这里注释掉了 tableEnv.executeSql("SELECT...") 查询
* 没有继续深究原因,暂时跳过
*
*/
public static void tableExecuteSql(SingleOutputStreamOperator<Tuple3<Integer, String, Integer>> stream,
TableEnvironment tableEnv) throws Exception {
// 创建数据表并插入数据 - Source
tableEnv.executeSql("CREATE TABLE t_department (" +
"`id` INT, " +
"`name` STRING, " +
"`location` STRING" +
") " +
" WITH (" +
"'connector' = 'kafka', " +
"'topic' = 'test', " +
"'properties.bootstrap.servers' = '172.16.185.176:9092', " +
"'format' = 'json', " +
"'scan.startup.mode' = 'earliest-offset'" +
");");
// 4. 输出结果 - Sink
tableEnv.executeSql("INSERT INTO t_department VALUES (1, 'Apple', 'beijing'), (2, 'Banana', 'shanghai');");
// 查询数据
// tableEnv.executeSql("SELECT * FROM t_department;");
}
}窗口编程
Table API可以和Flink的窗口(Window)结合,可以实现基于窗口的滚动(Tumbling)、滑动(Sliding)或会话(Session)等更灵活且复杂的功能。
官方指南:Table API结合窗口编程。
它们的模式和语法就像下面代码模板这样。
/**
* 滚动窗口
*
*/
// 基于事件时间的滚动窗口
.window(Tumble.over(lit(10).minutes()).on($("rowtime")).as("w"));
// 基于处理时间的滚动窗口 (假定处理时间属性为"proctime")
.window(Tumble.over(lit(10).minutes()).on($("proctime")).as("w"));
// 基于行计数的滚动窗口 (假定处理时间属性为"proctime")
.window(Tumble.over(rowInterval(10)).on($("proctime")).as("w"));
/**
* 滑动窗口
*
*/
// 基于事件时间的滑动窗口
.window(Slide.over(lit(10).minutes())
.every(lit(5).minutes())
.on($("rowtime"))
.as("w"));
// 基于处理时间的滑动窗口 (假定处理时间属性为"proctime")
.window(Slide.over(lit(10).minutes())
.every(lit(5).minutes())
.on($("proctime"))
.as("w"));
// 基于行计数的滑动窗口 (假定处理时间属性为"proctime")
.window(Slide.over(rowInterval(10)).every(rowInterval(5)).on($("proctime")).as("w"));
/**
* 会话窗口
*
*/
// 基于事件时间的会话窗口
.window(Session.withGap(lit(10).minutes()).on($("rowtime")).as("w"));
// 基于处理时间的会话窗口 (假定处理时间属性为"proctime")
.window(Session.withGap(lit(10).minutes()).on($("proctime")).as("w"));而Table SQL结合窗口编程的内容在这里:Table SQL Group Window。
-- 样例表
CREATE TABLE Orders (
user BIGINT,
product STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '1' MINUTE
) WITH (...);
-- 在SQL中使用窗口的模板
SELECT
user,
-- 返回相应滚动、滑动或会话窗口的包含下界的时间戳,也就是包含左闭区间的时间戳
TUMBLE_START(order_time, INTERVAL '1' DAY) AS wStart,
-- HOP_START(order_time, INTERVAL '1' DAY) AS wStart,
-- SESSION_START(order_time, INTERVAL '1' DAY) AS wStart,
-- 返回相应滚动、滑动或会话窗口的不包含上界的时间戳,也就是不包含右开区间的时间戳
TUMBLE_END(order_time, INTERVAL '1' DAY) AS wEnd,
-- HOP_END(order_time, INTERVAL '1' DAY) AS wEnd,
-- SESSION_END(order_time, INTERVAL '1' DAY) AS wEnd,
-- 返回相应滚动、滑动或会话窗口的包含上界的时间戳,也就是包含右开区间的时间戳
TUMBLE_ROWTIME(order_time, INTERVAL '1' DAY) AS wRowtime,
-- HOP_ROWTIME(order_time, INTERVAL '1' DAY) AS wRowtime,
-- SESSION_ROWTIME(order_time, INTERVAL '1' DAY) AS wRowtime,
-- 返回可用于后续基于时间的操作的proctime属性,如间歇性联接、窗口分组或跨窗口聚合
TUMBLE_PROCTIME(order_time, INTERVAL '1' DAY) AS wProctime,
-- HOP_PROCTIME(order_time, INTERVAL '1' DAY) AS wProctime,
-- SESSION_PROCTIME(order_time, INTERVAL '1' DAY) AS wProctime,
SUM(amount) FROM Orders
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY),
user当使用Flink 1.17.1版本时,出现了一个 Flink的BUG,即使升级到1.18.0和1.19.1版本,这个 BUG 依然存在。
我已经向官方提交了包含完整内容的issue,感兴趣的可以看看。
看来比较新版本的不能随便用,如果是生产环境就会非常麻烦。
所以只好降级到了Flink 1.12.1。
引入依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.1</version>
</dependency>下面是一个基于事件时间(EventTime)的滚动窗口,其他的都类似。
package itechthink.table;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
/**
* Table API & SQL结合窗口编程
* Flink 1.17.1版本抛出的BUG:
*
* Caused by: org.apache.flink.util.FlinkRuntimeException: org.apache.flink.api.common.InvalidProgramException: Table program cannot be compiled. This is a bug. Please file an issue.
* at org.apache.flink.table.runtime.generated.CompileUtils.compile(CompileUtils.java:94)
* at org.apache.flink.table.runtime.generated.GeneratedClass.compile(GeneratedClass.java:101)
* at org.apache.flink.table.runtime.generated.GeneratedClass.newInstance(GeneratedClass.java:68)
* ... 13 more
* Caused by: org.apache.flink.shaded.guava30.com.google.common.util.concurrent.UncheckedExecutionException: org.apache.flink.api.common.InvalidProgramException: Table program cannot be compiled. This is a bug. Please file an issue.
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2051)
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache.get(LocalCache.java:3962)
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache$LocalManualCache.get(LocalCache.java:4859)
* at org.apache.flink.table.runtime.generated.CompileUtils.compile(CompileUtils.java:92)
* ... 15 more
* Caused by: org.apache.flink.api.common.InvalidProgramException: Table program cannot be compiled. This is a bug. Please file an issue.
* at org.apache.flink.table.runtime.generated.CompileUtils.doCompile(CompileUtils.java:107)
* at org.apache.flink.table.runtime.generated.CompileUtils.lambda$compile$0(CompileUtils.java:92)
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache$LocalManualCache$1.load(LocalCache.java:4864)
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache$LoadingValueReference.loadFuture(LocalCache.java:3529)
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache$Segment.loadSync(LocalCache.java:2278)
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache$Segment.lockedGetOrLoad(LocalCache.java:2155)
* at org.apache.flink.shaded.guava30.com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2045)
*
* 升级到Flink 1.18.0版本和Flink 1.19.1版本这个问题依然存在
* 只能选择降级到1.12.1
* (Flink 1.12.1 + Flink Table Planner Blink_2.12 1.12.1 + Flink Table API Java Bridge 1.12.1 + Flink Clients_2.12 1.12.1)
*
*/
public class TableApiSQLWindowsJobV1121 {
public static final List<User> USER_LIST = Arrays.asList(
new User(1000, "user1", "手机", 6999),
new User(2000, "user1", "电脑", 8999),
new User(2000, "user2", "运动鞋", 128),
new User(3000, "user1", "电子书", 65),
new User(8000, "user2", "饮料", 3),
new User(19000, "user1", "食用油", 82)
);
public static void main(String[] args) throws Exception {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment);
/*
* 数据格式:时间戳,用户名,商品名,价格
* 窗口大小10s,不允许延迟
*
* 输出:
* api> (true,user2,131,1970-01-01T00:00,1970-01-01T00:00:10)
* api> (true,user1,16063,1970-01-01T00:00,1970-01-01T00:00:10)
* api> (true,user1,82,1970-01-01T00:00:10,1970-01-01T00:00:20)
* sql> (true,1970-01-01T00:00,1970-01-01T00:00:10,user2,131)
* sql> (true,1970-01-01T00:00,1970-01-01T00:00:10,user1,16063)
* sql> (true,1970-01-01T00:00:10,1970-01-01T00:00:20,user1,82)
*
*/
// // 2. 读取数据 - Source
// SingleOutputStreamOperator<User> stream = environment.fromCollection(USER_LIST)
// // 3. 处理数据 - Transform
// // 添加时间戳和Watermark
// .assignTimestampsAndWatermarks(
// WatermarkStrategy.<User>forBoundedOutOfOrderness(Duration.ZERO)
// .withTimestampAssigner(
// new SerializableTimestampAssigner<User>() {
// @Override
// public long extractTimestamp(User user, long record) {
// return user.getTime();
// }
// }
// )
// );
// 2. 读取数据 - Source
SingleOutputStreamOperator<Tuple4<Long, String, String, Long>> stream = environment.fromElements(
"1000,user1,手机,6999",
"2000,user1,电脑,8999",
"2000,user2,运动鞋,128",
"3000,user1,电子书,65",
"8000,user2,饮料,3",
"19000,user1,食用油,82"
)
// 3. 处理数据 - Transform
.filter(new FilterFunction<String>() {
@Override
public boolean filter(String input) throws Exception {
String[] split = input.split(",");
return StringUtils.isNotBlank(input) &&
4 == split.length &&
StringUtils.isNumeric(split[0]) &&
StringUtils.isNumeric(split[3]) &&
StringUtils.isNotBlank(split[1]);
}
})
.map(new MapFunction<String, Tuple4<Long, String, String, Long>>() {
@Override
public Tuple4<Long, String, String, Long> map(String s) throws Exception {
String[] split = s.split(",");
return Tuple4.<Long, String, String, Long>of(Long.parseLong(split[0]), split[1], split[2], Long.parseLong(split[3]));
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple4<Long, String, String, Long>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple4<Long, String, String, Long>>() {
@Override
public long extractTimestamp(Tuple4<Long, String, String, Long> input, long l) {
return input.f0;
}
}
)
);
tableApiWindow(stream, tableEnvironment);
// 5. 启动任务 - Execute
environment.execute("TableApiSQLWindowsJobV1121");
}
/**
* 通过Table API读取数据
*
*/
private static void tableApiWindow(SingleOutputStreamOperator<Tuple4<Long, String, String, Long>> stream, StreamTableEnvironment tableEnvironment) {
// 将DataStream转换成Table
Table table = tableEnvironment.fromDataStream(stream,
$("f0").as("time"),
$("f1").as("name"),
$("f2").as("product"),
$("f3").as("price"),
// Flink内置的时间
$("rowtime").rowtime()
);
// 查询数据
// Table result = table.select($("time"), $("name"), $("product"), $("price"), $("rowtime")).where($("name").isEqual("user1").and($("price").isGreaterOrEqual(10)));
// tableEnvironment.toRetractStream(result, Row.class).print("api").setParallelism(1);
/*
* 使用Table API + Windows
*
*/
Table result = table
.window(Tumble
.over(lit(10).second())
.on($("rowtime")).as("win")
)
.groupBy($("name"), $("win"))
.select($("name"), $("price").sum().as("total"), $("win").start(), $("win").end());
tableEnvironment.toRetractStream(result, Row.class).filter(x -> x.f0).print("api").setParallelism(1);
/*
* 使用Table SQL + Windows
*
*/
tableEnvironment.createTemporaryView("users", stream, $("time"), $("name"), $("product"), $("price"), $("rowtime").rowtime());
Table resultTable = tableEnvironment.sqlQuery("SELECT TUMBLE_START(rowtime, interval '10' second) AS win_start, TUMBLE_END(rowtime, interval '10' second) AS win_end, name, sum(price) " +
"FROM users GROUP BY TUMBLE(rowtime, interval '10' second), name");
tableEnvironment.toRetractStream(resultTable, Row.class).filter(x -> x.f0).print("sql").setParallelism(1);
}
}感谢支持
更多内容,请移步《超级个体》。