
Checkpoint检查点
什么是Checkpoint
如果Flink运行时,某个算子出现故障,如何处理?
当故障恢复后,又如何保证数据状态和恢复前保持一致?
Flink通过Checkpoint机制,为程序生成快照(Snapshot),如果程序崩溃,那么就可以有选择地从这些快照中进行恢复。
Checkpoint是Flink可靠性保证的基石,Flink有很好的容错机制和从故障中恢复的策略,不至于一宕机就要人为恢复。
官方提供了比较详细的对这些策略的相关介绍。
下面的代码是对这些策略的简要说明。
package itechthink.checkpoint;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.configuration.RestartStrategyOptions;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
/**
* 故障重启策略
*
*/
public class FailureRestartStrategyJob {
public static void main(String[] args) {
/**
* 以配置类的方式为每个Flink作业单独定义重启策略
*
*/
Configuration config = new Configuration();
// Flink 默认的重启策略就是不尝试重启
// 通过名称指定重启策略
// config.set(RestartStrategyOptions.RESTART_STRATEGY, "none");
config.set(RestartStrategyOptions.RESTART_STRATEGY, "fixed-delay");
// config.set(RestartStrategyOptions.RESTART_STRATEGY, "failure-rate");
// 固定延时重启策略下尝试重启的次数
config.set(RestartStrategyOptions.RESTART_STRATEGY_FIXED_DELAY_ATTEMPTS, 3);
// 固定延时重启策略下的延时
config.set(RestartStrategyOptions.RESTART_STRATEGY_FIXED_DELAY_DELAY, Duration.ofSeconds(10));
// 故障率重启策略下每个时间间隔的最大故障次数
config.set(RestartStrategyOptions.RESTART_STRATEGY_FAILURE_RATE_MAX_FAILURES_PER_INTERVAL, 3);
// 故障率重启策略下测量故障率的时间间隔
config.set(RestartStrategyOptions.RESTART_STRATEGY_FAILURE_RATE_FAILURE_RATE_INTERVAL, Duration.ofMinutes(5));
// 两次重启尝试之间的延迟
config.set(RestartStrategyOptions.RESTART_STRATEGY_FAILURE_RATE_DELAY, Duration.ofSeconds(10));
// 指数延迟重启策略下的延迟时间翻倍因子,表示每次重试的延迟时间乘以这个值
config.set(RestartStrategyOptions.RESTART_STRATEGY_EXPONENTIAL_DELAY_BACKOFF_MULTIPLIER, 1.1);
// 指数延迟重启策略下当作业第一次发生异常时会延迟 1 秒后进行重试
config.set(RestartStrategyOptions.RESTART_STRATEGY_EXPONENTIAL_DELAY_INITIAL_BACKOFF, Duration.ofSeconds(1));
// 指数延迟重启策略下每次的延迟时间会加减一个随机值,随机值的范围在 0.1 的比例内
config.set(RestartStrategyOptions.RESTART_STRATEGY_EXPONENTIAL_DELAY_JITTER_FACTOR, 0.1);
// 指数延迟重启策略下重试的延迟时间最多为 10 秒(上限)
config.set(RestartStrategyOptions.RESTART_STRATEGY_EXPONENTIAL_DELAY_MAX_BACKOFF, Duration.ofSeconds(10));
// 指数延迟重启策略下如果连续两次重试的间隔时间超过这个阈值,那么就会重置这个阈值
config.set(RestartStrategyOptions.RESTART_STRATEGY_EXPONENTIAL_DELAY_RESET_BACKOFF_THRESHOLD, Duration.ofSeconds(3));
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
/**
* 通过上下文环境指定重启策略
*
*/
// 固定延时重启策略按照给定的次数尝试重启作业。如果尝试超过了给定的最大次数,作业将最终失败
// 在连续的两次重启尝试之间,重启策略等待一段固定长度的时间
// environment.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.seconds(10)));
environment.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000));
// 指数延迟重启策略在两次连续的重新启动尝试之间,重新启动的延迟时间不断呈指数增长,直到达到最大延迟时间。然后,延迟时间将保持在最大延迟时间
environment.setRestartStrategy(RestartStrategies.exponentialDelayRestart(
// initial-backoff:表示当作业第一次发生异常时会延迟 1 秒后进行重试
Time.seconds(1),
// max-backoff:表示重试的延迟时间最多为 10 秒(上限)
Time.seconds(10),
// backoff-multiplier:表示每次重试的延迟时间乘以这个值
1.1,
// reset-backoff-threshold:表示如果连续两次重试的间隔时间超过这个阈值,那么就会重置这个阈值
Time.seconds(2),
// jitter-factor:表示每次的延迟时间会加减一个随机值,随机值的范围在 0.1 的比例内
0.1
));
// 故障率重启策略在故障发生之后重启作业,但是当故障率(每个时间间隔发生故障的次数)超过设定的限制时,作业会最终失败
// 在连续的两次重启尝试之间,重启策略等待一段固定长度的时间
environment.setRestartStrategy(RestartStrategies.failureRateRestart(
// max-failures-per-interval:表示在每个时间间隔中,允许的最大故障次数
3,
// failure-rate-interval:表示故障率的测量时间间隔
Time.seconds(10),
// delay:两次重启尝试之间的延迟
Time.seconds(60)));
/**
* 如果没开启Checkpoint:失败不重启
* 如果开启了Checkpoint:
* 1. 如果没有配置重启策略,在最新的Flink版本中,那么连接未开启时,默认是既不抛出异常,也不重启,而是一直等待
* 如果此时连接恢复,则直接正常输出
* 2. 如果配置了重启策略,就是用配置的覆盖默认的
*
* 重启策略的配置:
* 1. 在代码中配置
* 2. 在yml文件中配置
*
* 所有的重启策略不仅对Flink系统运行本身生效,而且也对作业的运行生效
* 意思就是当当作也出现异常时,也会遵循配置的重启策略
*
*/
environment.enableCheckpointing(5000);
// ExecutionConfig,它允许在运行时设置作业特定的配置值
// 要更改影响所有作业的默认值,可以通过conf/config.yml实现(从Flink-1.19版本开始,默认的配置文件已更名为config.yml)
ExecutionConfig executionConfig = environment.getConfig();
System.out.println("executionConfig = " + executionConfig.toString());
ReadableConfig readableConfig = environment.getConfiguration();
System.out.println("readableConfig = " + readableConfig.toString());
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
environment.setParallelism(1);
source.print();
// 5. 启动任务 - Execute
try {
environment.execute("FailureRestartStrategyJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}需要注意的是,既然State可以保存状态,Checkpoint也可以保存状态,那它们之间有什么区别呢?
State是指某个算子的数据状态,而Checkpoint是所有算子的数据状态。State保存在堆内存,而Checkpoint保存在持久化内存。
Checkpoint
如果每次宕机,所有的计算都要从头再来,这个代价恐怕有点大。
所以,Flink也提供了从最近一次计算状态(或结果)中恢复并继续执行的能力,这就是Checkpoint机制和与之相关的StateBackend。
自1.13版本开始,Flink将StateBackend与CheckpointStorage进行了拆分。Flink提供了两种开箱即用的存储类型。
JobManagerCheckpointStorage。FileSystemCheckpointStorage。
而在最新的版本中,MemoryStateBackend、StateBackend和RockctDBStateBackend也已经被两种新的StateBackend替代。
HashMapStateBackend。EmbeddedRocksDBStateBackend。
引入依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>1.17.1</version>
</dependency>编写示例代码。
package itechthink.checkpoint;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.StateBackendOptions;
import org.apache.flink.runtime.state.storage.FileSystemCheckpointStorage;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Checkpoint与State备份存储
*
*/
public class CheckpointAndStateBackendJob {
public static void main(String[] args) {
/**
* 可以通过Configuration设置Checkpoint和StateBackend
*
*/
// 如果什么都不设置,默认使用HashMapStateBackend
Configuration configuration = new Configuration();
// 除了hashmap,还有jobmanager和rocksdb
// configuration.set(StateBackendOptions.STATE_BACKEND, "hashmap"); // 效果等同于environment.setStateBackend(new HashMapStateBackend());
// configuration.set(StateBackendOptions.STATE_BACKEND, "jobmanager");
configuration.set(StateBackendOptions.STATE_BACKEND, "rocksdb"); // 效果等同于environment.setStateBackend(new EmbeddedRocksDBStateBackend());
// configuration.set(CheckpointingOptions.CHECKPOINT_STORAGE, "filesystem");
// configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, "hdfs:///checkpoints-data/");
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
/**
* 也可以直接通过environment设置Checkpoint和StateBackend
*
*/
// environment.setStateBackend(new HashMapStateBackend());
// environment.setStateBackend(new EmbeddedRocksDBStateBackend());
// 启用Checkpoint并且配置StateBackend
environment.enableCheckpointing(5000);
// 除了配置StateBackend,还需要设置Checkpoint的StateBackend存储方式:JobManagerCheckpointStorage或者FileSystemCheckpointStorage
CheckpointConfig checkpointConfig = environment.getCheckpointConfig();
// checkpointConfig.setCheckpointStorage(new JobManagerCheckpointStorage(""));
checkpointConfig.setCheckpointStorage(new FileSystemCheckpointStorage("file:///Users/bear/home/work/checkpoint"));
// 配置Checkpoint的清理方式:保留Savepoint文件
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
DataStreamSource<String> source = environment.socketTextStream("localhost", 9528);
source.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> output) throws Exception {
String[] words = input.split(",");
for (String word : words) {
output.collect(Tuple2.of(word, 1));
}
}
}).keyBy(x -> x.f0)
.sum(1).print();
// 5. 启动任务 - Execute
try {
environment.execute("CheckpointAndStateBackendJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}运行之后,可以发现本地多了checkpoint/${job-id}/chk-10这样的文件。这就是Flink保存在外部的任务状态。
只要通过命令行或在UI在线提交作业的方式,就能接着上一次的状态继续运行。
Savepoint
Savepoint是依据Flink的Checkpoint机制所创建的流作业执行状态的一致镜像,就是指定FileSystemCheckpointStorage()时所指定的存储路径。
它可以让Flink从崩溃中恢复,并接着上一次的状态继续执行。
它也可以从Checkpoint中恢复。
通过命令行来触发Savepoint。
> ./bin/flink savepoint :jobId [目标路径]
# 或者
> ./bin/flink savepoint :jobId [目标路径] -yid :yarnAppId通过命令行来恢复作业执行,并从最近一次状态中恢复。
> ./bin/flink run -s <savepoint路径> [:runArgs]
# 或者从Checkpoint恢复
> ./bin/flink run -c <主类路径限定名> -s <Checkpoint路径> <jar包路径>
# 例如
> ./bin/flink run -c itechthink.checkpoint.CheckpointAndStateBackendJob -s file:///Users/bear/home/work/checkpoint/c3920c90505dbf51d716135e008657e2/chk-7 /home/work/CheckpointAndStateBackendJob.jarCheckpoint和Savepoint的区别
Checkpoint是容错恢复机制,而Savepoint是某个时间点的全局状态镜像。Checkpoint是由Flink系统触发,而Savepoint由用户手动触发。Checkpoint默认会删除数据,而Savepoint默认会一直保存。
Slot和并行度
Flink中的Slot和并行度是紧密相关的。
Slot是TaskManager的一个子集,用于控制每个worker能接收的子任务数量。Slot的数量代表了所能支持的子任务的数量,也就是整个任务的最高并发度。并行度是指TaskManager运行程序时实际使用的并发能力,它决定了任务可以同时执行的算子操作数量。Flink任务的
Slot数量与作业中最高的并行度保持一致。
所以当设置了较高的并行度而没有足够的Slot时,程序性能可能会显著降低。
所以,设置合理的并行度可以优化Flink的计算性能,加快数据的处理,而Flink的每个算子都可以设置并行度。
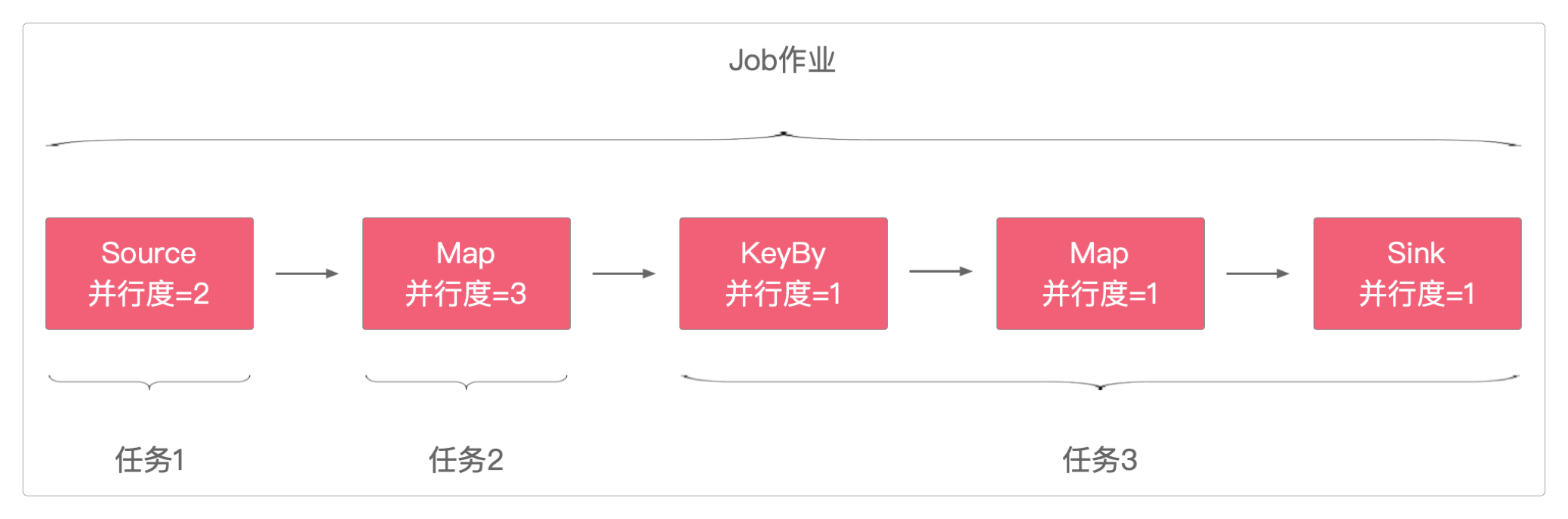
从Source到Sink,每当并行度发生变化或者数据分组(例如keyBy)。就会产生任务。
一个并行度为N的任务,会产生N个子任务。
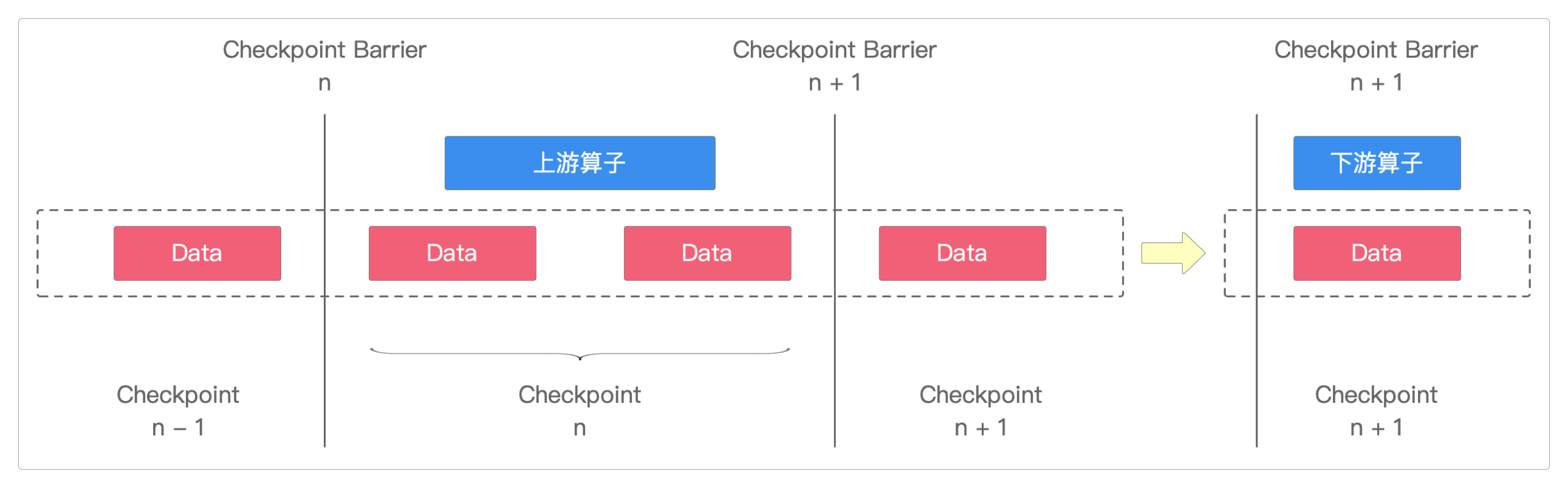
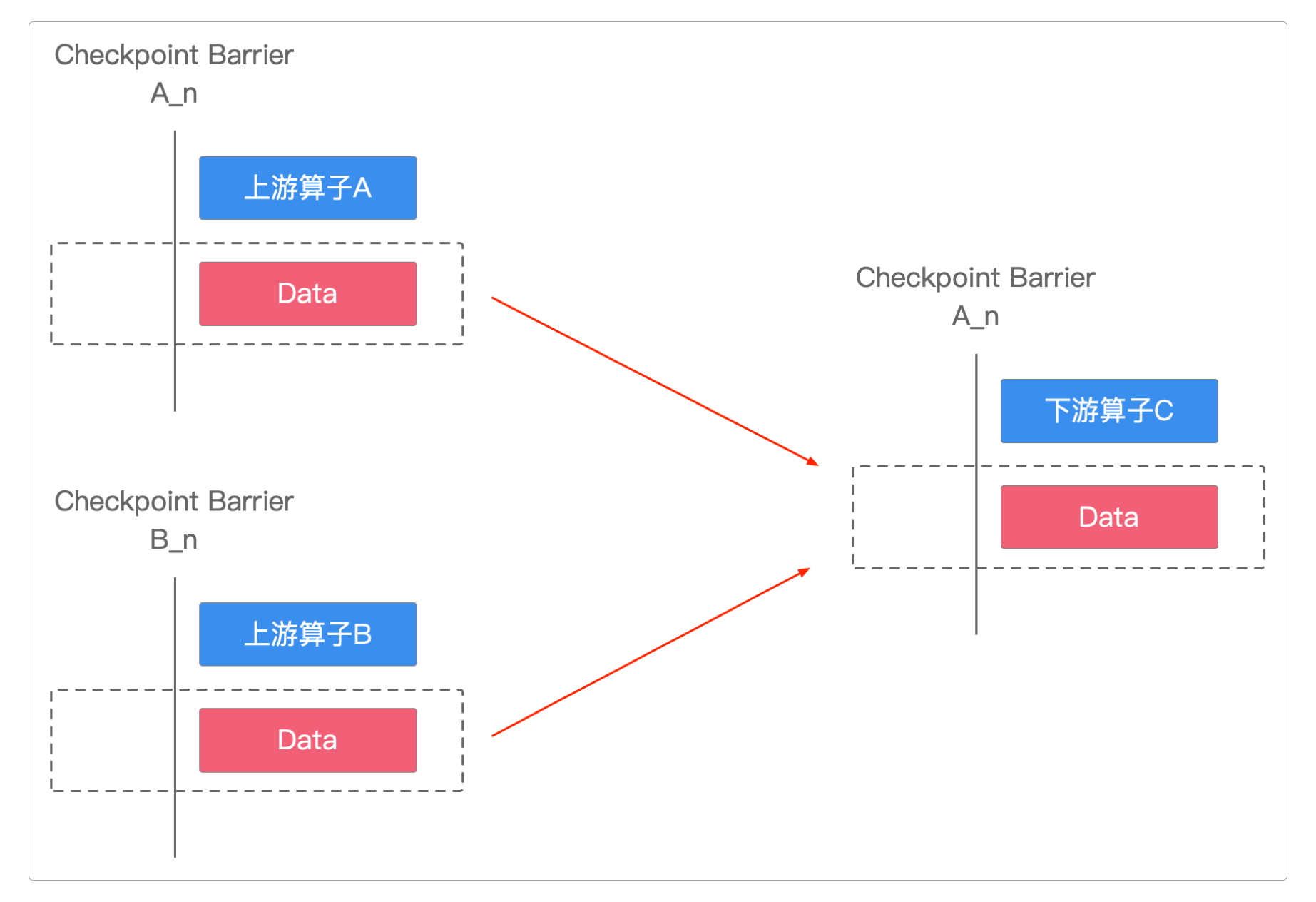
分布式快照流程
要实现分布式快照,最关键的就是要能够将数据流进行切分。
Flink使用Checkpoint Barrier来切分数据流。
Flink也是通过它才实现Excatly-Once的语义处理。
分布式快照流程第一步
当Source子任务收到Checkpoint请求,该算子就会对自己的数据状态保存到快照。
它会向自己的下一个算子发送Checkpoint Barrier请求。下游算子只有收到上游算子广播过来的Checkpoint Barrier请求,才会进行快照。
分布式快照流程第二步
当Sink算子已经收到了所有上游的Checkpoint Barrier请求时,会进行两步操作。
保存自己的数据状态。
通知
Checkpoint协调器。
Checkpoint协调器在收集所有的任务通知后,就认为此次的Checkpoint全部完成了。
At-Least-Once
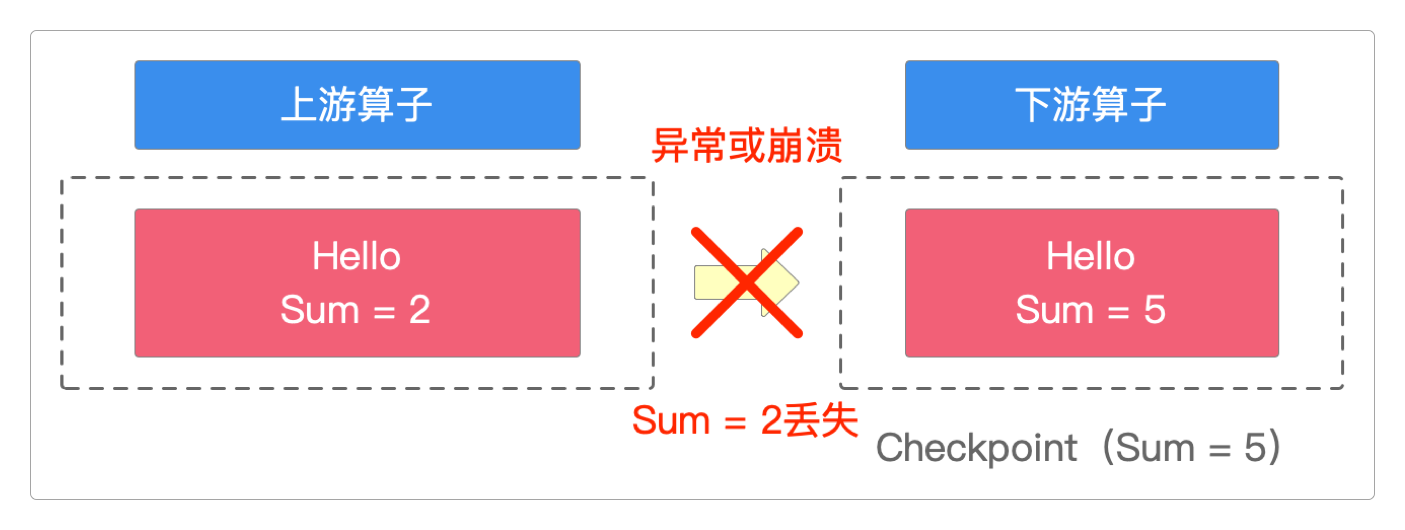
At-Least-Once的意思则是至少一次,在这种模式下,Flink即使发生故障,它也能够 保证不丢失数据,但可能会出现重复数据。
Excatly-Once
Excatly-Once的意思是精确一次,用大白话来说就是在这种模式下,Flink即使发生故障,它也能够 保证不丢失数据,而且也不会出现重复数据。
在T1时间点时算子1的执行状态如下图。
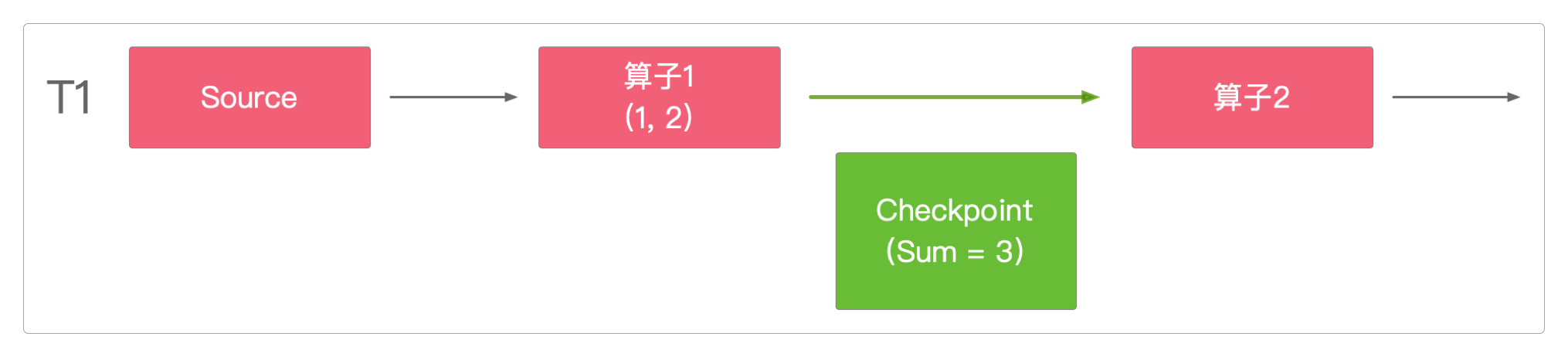
但在T2时间点时,算子1执行异常,任务失败。
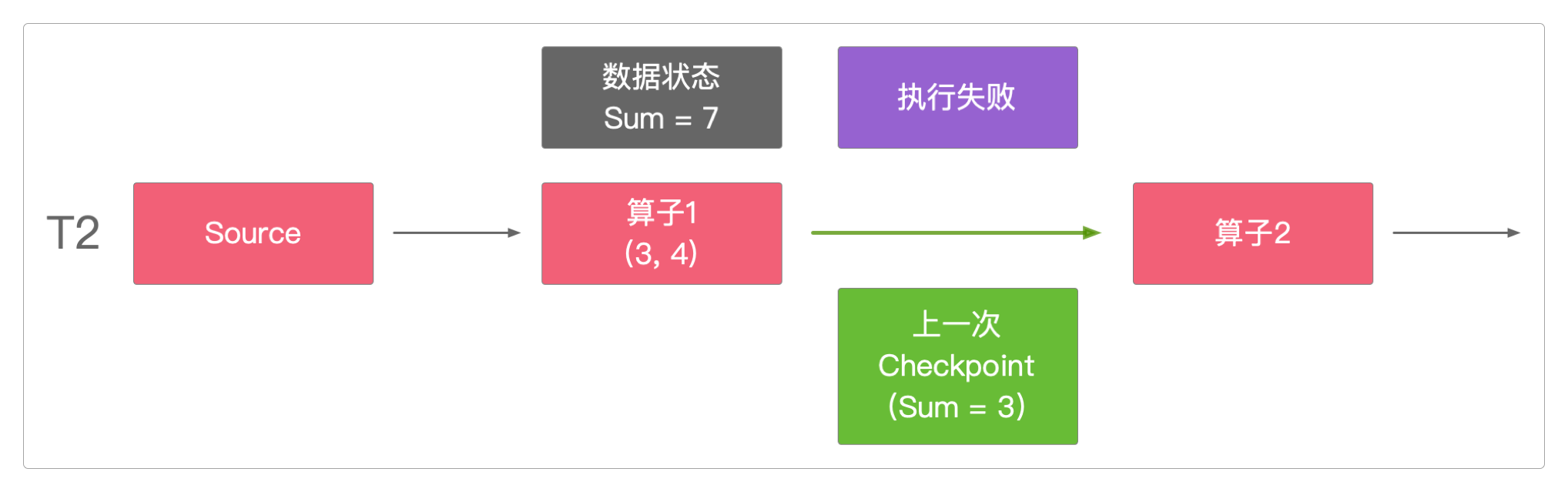
Checkpoint将T2时间点的算子1状态回滚到上一次执行成功时的数据值(也就是Sum = 3)。
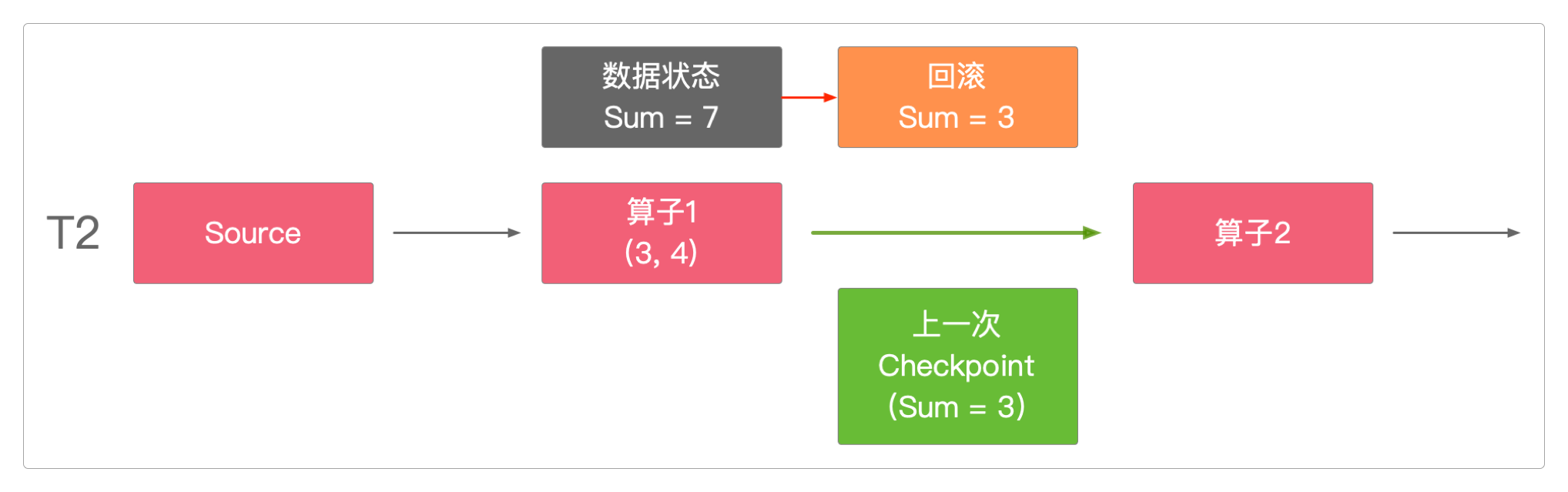
这种回滚就是通过Checkpoint Barrier机制实现的, Checkpoint Barrier保证了Checkpoint数据状态的精确一致。
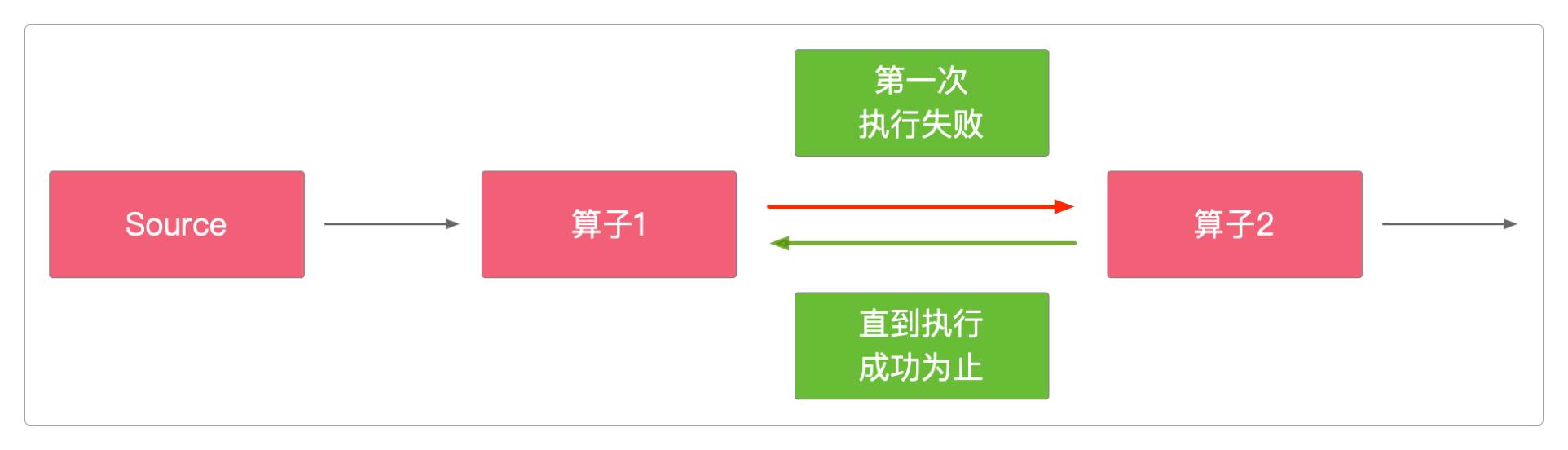
对于Excatly-Once的分析,推荐老外写的这篇文章Excatly-Once的两阶段提交。
感谢支持
更多内容,请移步《超级个体》。