
Time时间机制与Watermark
Flink中的时间语义
在现实世界中,数据不可能会像理想中的那样,来一条就处理一条,反而是各种网络故障、数据延迟、乱序等问题更多更常态化一些。
为了更精准地处理数据流,Flink定义了三种不同的时间语义(时间在Flink流处理中的意义)。
处理时间(Processing Time):是执行Flink计算的机器的系统时间,可能是某台独立部署的机器,也可能是集群中的某一台。它不需要和其他机器协调或同步,在哪台机器上,就以哪台机器的时间为准。事件时间(Event Time):是指每条数据记录产生时的自然时间,也就是记录生成的时间,例如监控探头生成的报警记录时间、银行ATM机生成的转账时间,短视频上传时间等。这种时间和Flink所在的机器本身的时间无关,而且它一定是有序的。摄入时间(Ingestion Time):摄入时间,类似于某人吃了东西,虽然吃进嘴里但还没开始消化。摄入就是指东西吃到嘴里的时间,也是指数据进入到Flink但还没开始处理的时间。
官网给出的这幅图非常清楚地指明了这三种时间语义的不同。
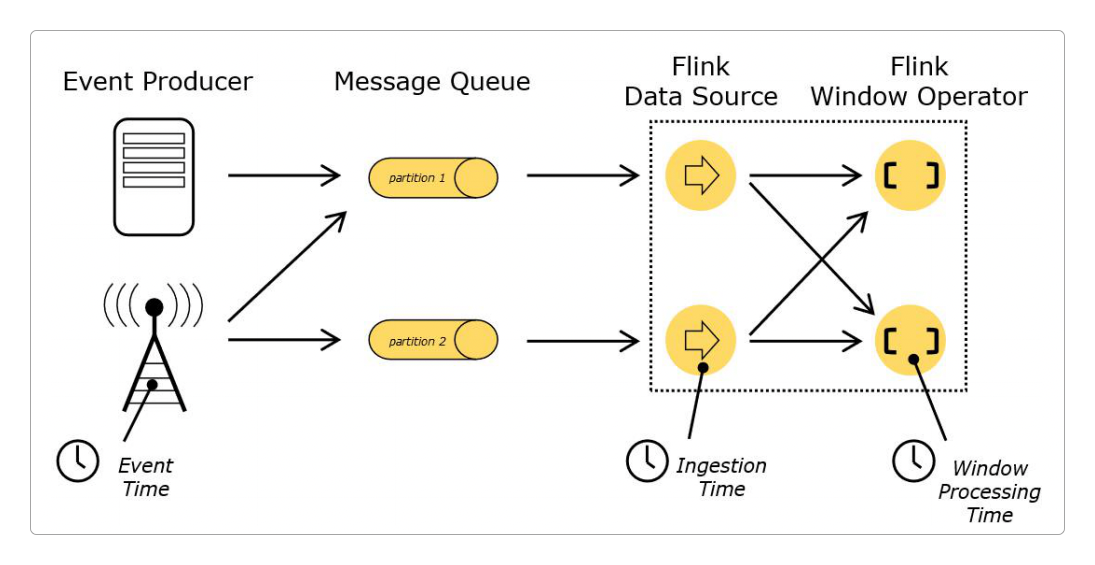
可以明确地在代码中告诉Flink需要采取哪种时间语义执行运算。
package itechthink.window;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Flink三种不同的时间语义
*
*/
public class FlinkTimeExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置事件时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 或者设置接收时间语义
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// 或者设置处理时间语义
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 构建数据流的其余部分
// ...
env.execute("Flink Time Example");
}
}凡事有好有坏,这几种不同的时间语义也各有利弊。
处理时间(Processing Time)
最为简单直接,完全不需要流和机器之间的协调,提供最佳性能和最低延迟。但在时间敏感,尤其是在银行、保险、证券、传媒等这些建立在完全时间序列之上的业务中,这种时间语义是不可接受的。
这种时间语义下的处理结果,有一定的随机性,因为它会受数据到达系统的先后、网络延迟、系统宕机、黑客攻击等各种因素的影响。
这种时间语义下,Flink会按最便于计算的方式来划分时间区间。
例如,如果Flink在9:20开始作业,那么第1个小时的作业区间是[9:20, 10:00),下一个作业的时间区间会是[10:00, 11:00),再下一个是[11:00, 12:00),依此类推。
[和)是数学集合中的概念,表示区间的开闭。[表示左闭区间,它包含下界数字,)表示右开区间,它不包含上界数字,[9:20, 10:00)表示处理9:20时间点上的数据,但不处理10:00时间点上的数据。
以下均同。
事件时间(Event Time)
这种时间会随着数据一同进入Flink参与计算,Flink可以单独提取它。在理想情况下,Flink可以按照这个时间顺序来依次处理每一条数据。
但现实世界是不确定的,各种性能损耗、网络延迟都会影响数据达到的顺序,比如在时间上先发生的事件反而最后到达。
这就导致Flink为了保持事件时间的自然顺序,而不得不中断处理进程,等待后续数据的到达,影响程序性能。
摄入时间(Ingestion Time)
这个时间语义用途不大,和前两者相比,它的作用几乎可以忽略不计。
Watermark
为了处理好事件时间(Event Time)的带来的影响,Flink采用了一种称为Watermark(水印)的机制。
所谓Watermark(水印),本质上是一个逻辑时钟,用来 衡量事件时间进度的机制,它让Flink等待指定的时间,当满足水位线要求后立即进行计算。
解释一下这句话。
例如,现在需要让Flink统计从10:00开始的10分钟内的登录用户数。
- 理想情况下,用户登录的时间有先有后,数据进入到Flink中也是完全有序的,就像这样。

- 但实际上,虽然用户登录的时间有先有后,由于各种网络延迟、上游系统宕机、系统运行缓慢等因素,让有些数据
晚点抵达。例如,10:01的数据抵达Flink的时间比10:02的更晚。

晚点:10:01的数据比10:02的数据要更晚抵达这也还算正常,毕竟它还在10分钟的统计范围内。
- 但是有的数据就晚得有点离谱了,过了10分钟之后竟然还没有到。比如,
10:11之后,10:08的数据才姗姗来迟。更离谱的是它后面竟然不是10:12的数据,而是10:07的数据。
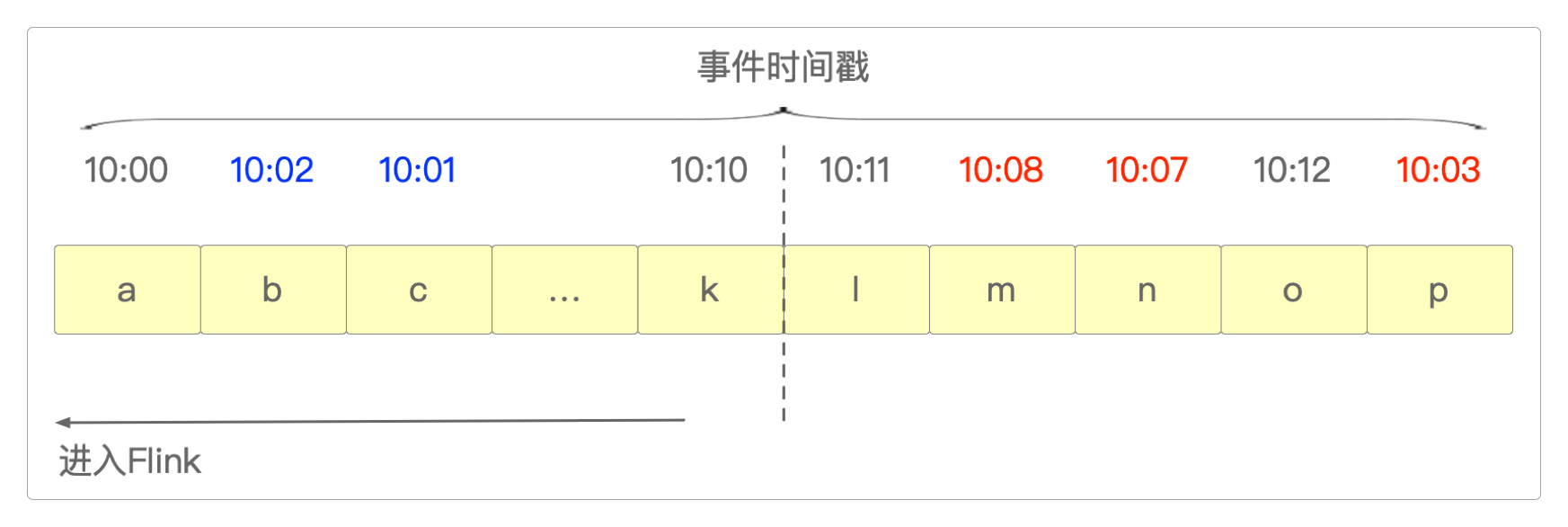
所以,现在面临三种选择。
一是直接丢弃掉这些已经错过发车时间的数据。
二是为了数据尽可能地完整,无限期地等下去。
三是给出最后通牒:再等2分钟,如果还不来就直接发车。
这三种不同的等待延迟数据的处理机制,就称为Watermark水印
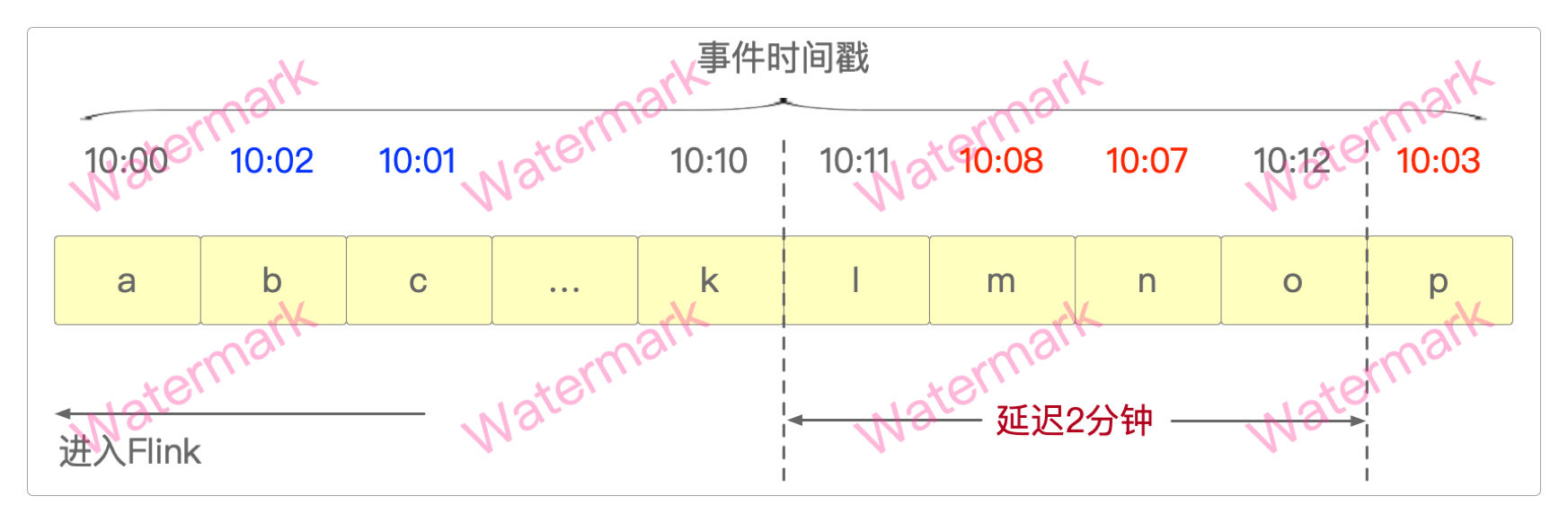
所以,再重复一下前面的话:Watermark水印本质上就是一种 衡量事件时间进度的机制,它让Flink等待指定的时间,当满足水位线要求后立即进行计算。
可以这么理解Watermark水印和Flink触发机制的关系。
水位线 = 进入Flink的最大事件时间 ‒ 最大延迟时间。
水位线 >= 窗口结束时间,立即触发计算(发车)。
在上面的Watermark水印机制图中。
进入Flink的最大事件时间:10:12(它并不一定是最后一个进入Flink的,但一定是最大的)。最大延迟时间:2分钟。窗口结束时间:10:10。触发条件:水位线(10:12-10:10) >=2分钟。丢弃数据:即使后面还有10:03的迟到数据,Flink也不等了,如果窗口内有数据 则立即触发计算任务。
下面的两张图是官方给出的对于Watermark水印机制的解释。
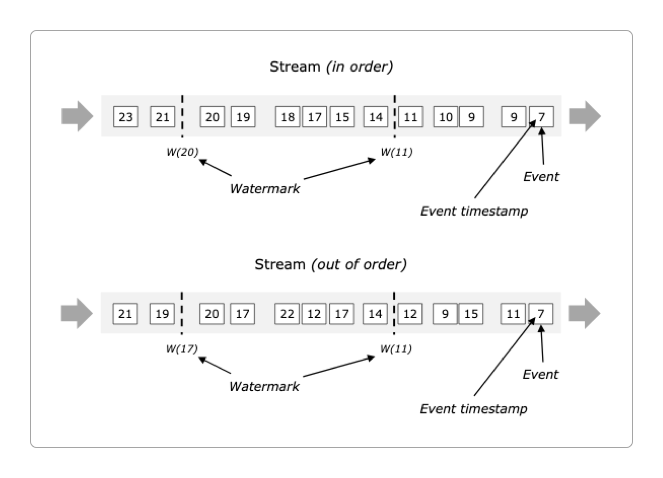
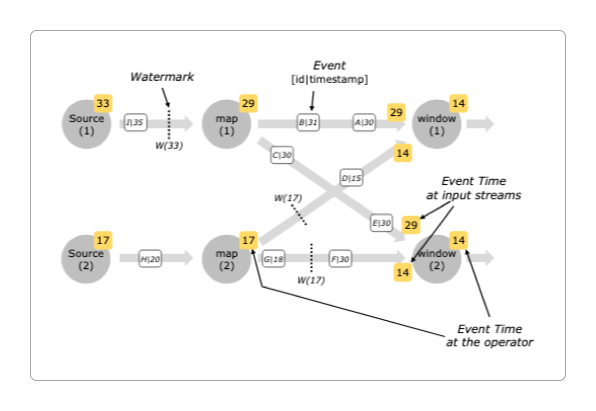
但实话说,它们并没有很清楚很完整地表达出Watermark水印意思。
感谢支持
更多内容,请移步《超级个体》。