
State状态管理
原创大约 5 分钟
状态分类
根据是否保存中间计算结果,Flink分为有状态计算和无状态计算两种不同的大类,而且它的根本概念之一就是有状态的流处理。
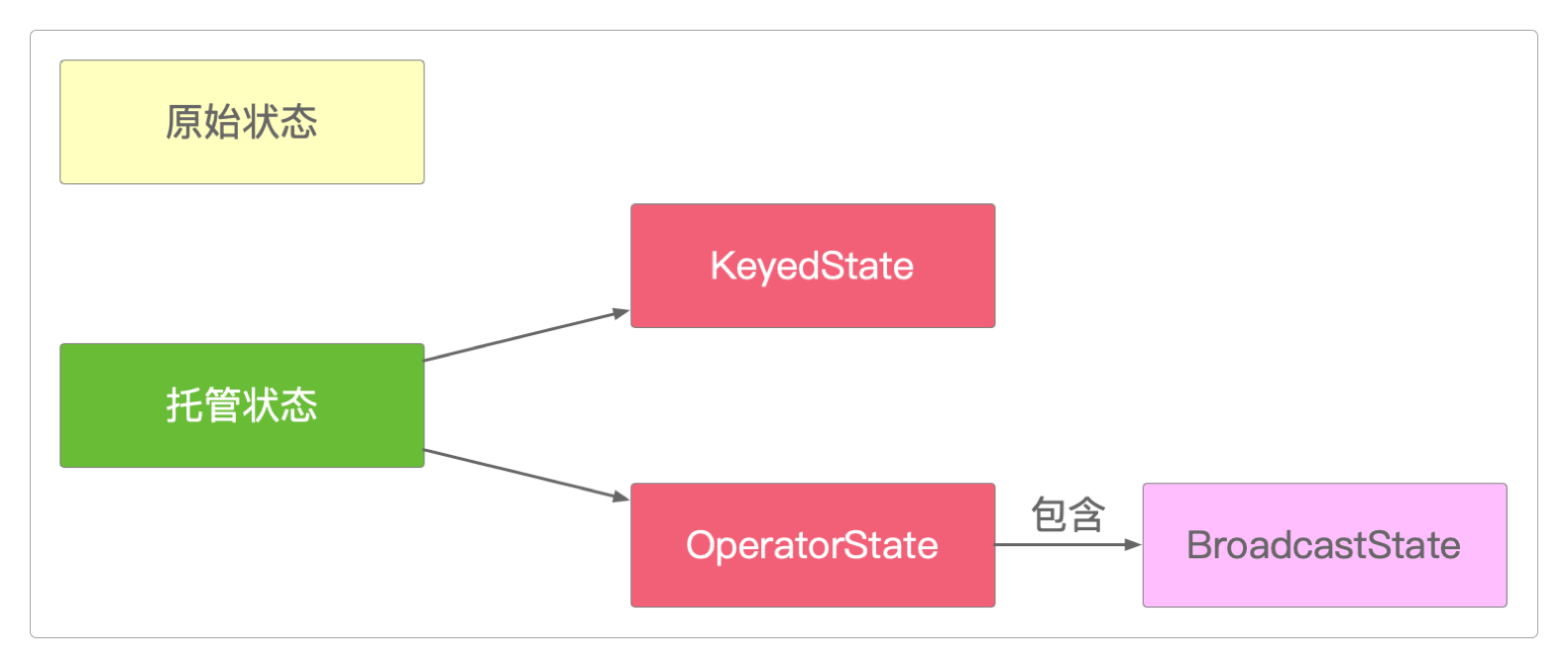
而对状态的管理又分为Flink管理和用户管理,分别对应于托管状态和原始状态。
托管状态
由Flink管理的状态,又称为托管状态。它由Flink管理,可以自动存储、恢复,内存管理经过Flink的优化,支持已知的数据结构,适用于大部分场景。托管状态又分为KeyedState和OperatorState这两类。
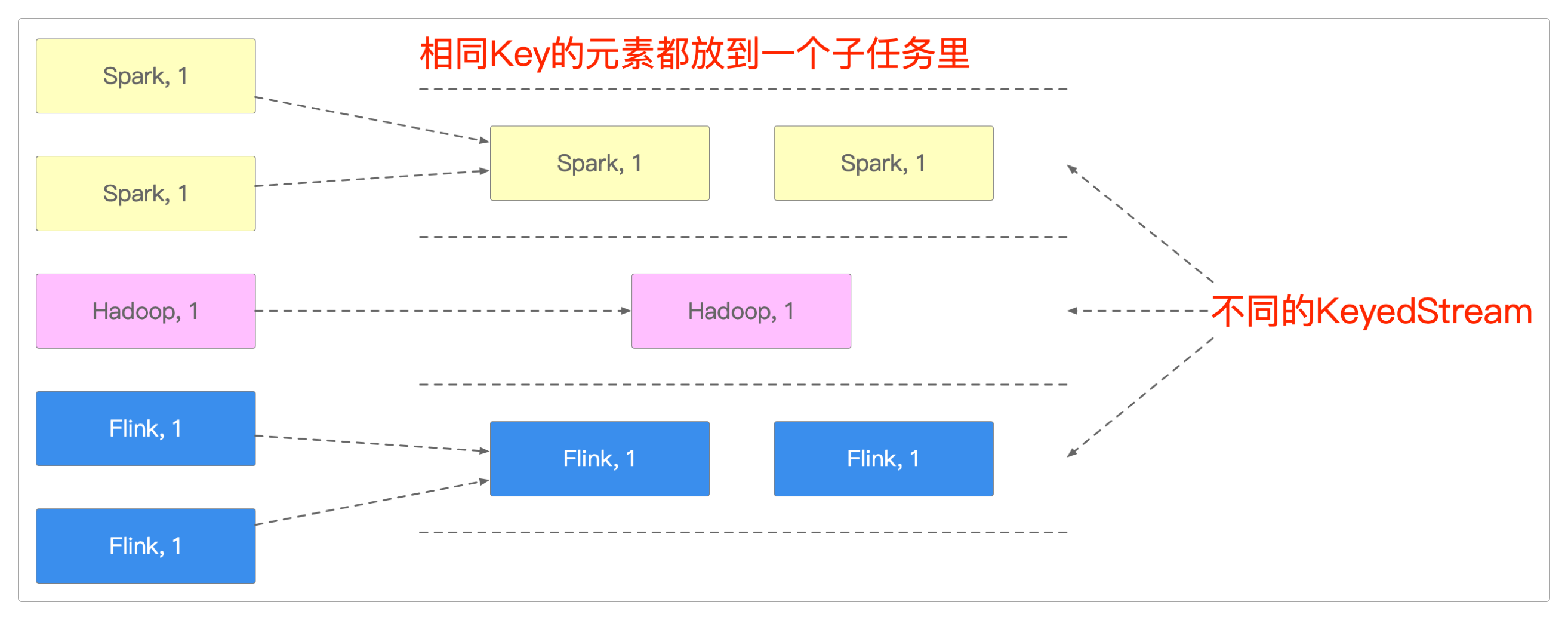
KeyedState对应于KeyedStream,它是把Key相同的元素都放在同一个计算任务里,类似于SQL中的Group By分组。
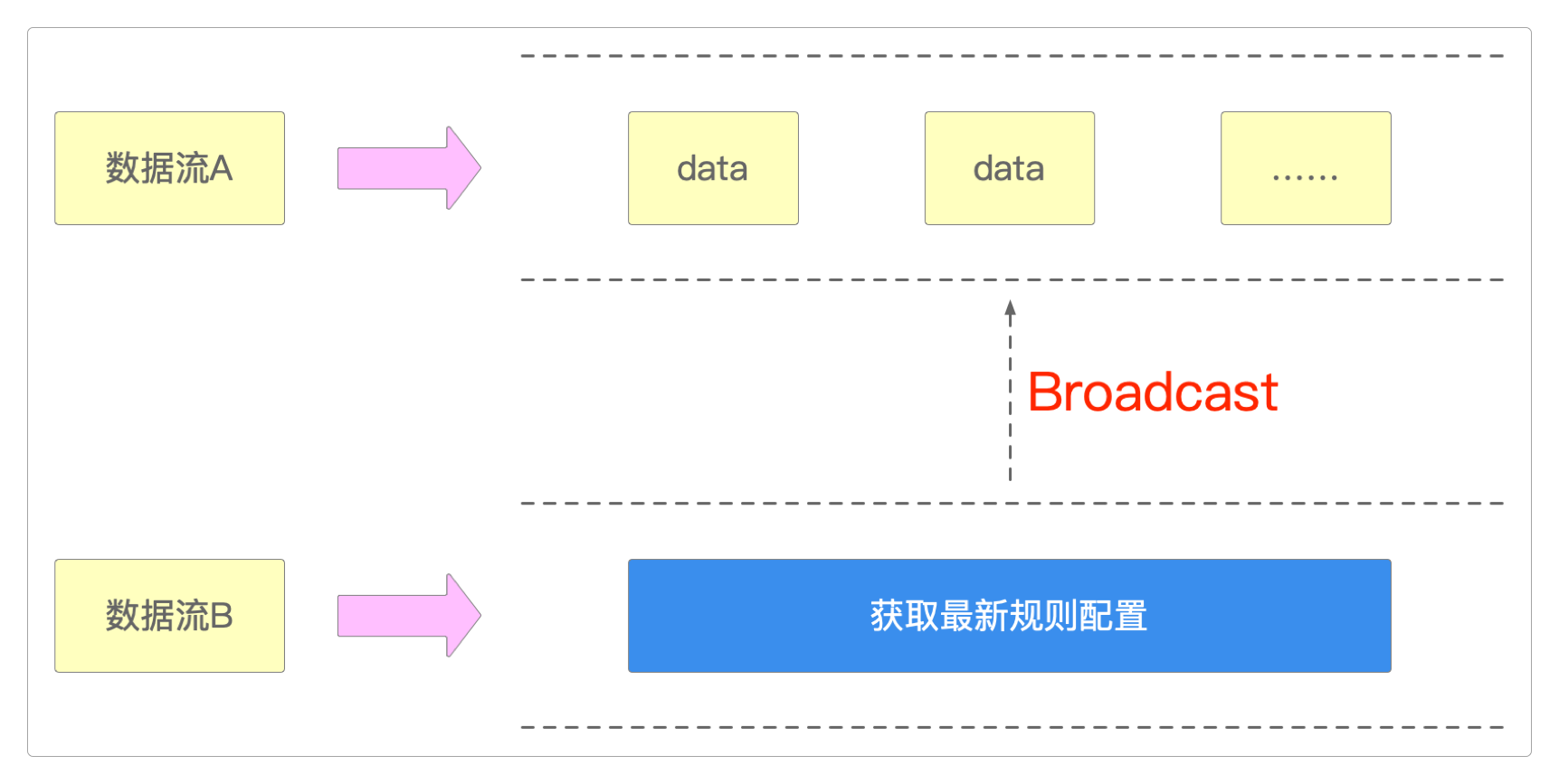
对于需要动态更新的应用来说,可以使用BroadcastState来实现。
可以使用这几种不同Keyed State的类型来实现有状态的计算任务。
ValueState<T>。ListState<T>。ReducingState<T>。AggregatingState<IN, OUT>。MapState<UK, UV>。
原始状态
由用户管理的状态,又称为原始状态。它由用户自己管理,需要用户自行存储、恢复及实现序列化和反序列化工作,只支持字节数组,只在用户自定义算子时使用。
它们在状态处理API里面有说明。
示例代码
通过KeyedState求平均数
package itechthink.state;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.*;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
/**
* 通过Keyed State求平均数
*
*/
public class CountAverageStateJob {
private static List<Tuple2<Long,Long>> list = new ArrayList<>();
public static void main(String[] args) {
list.add(Tuple2.of(1L, 3L));
list.add(Tuple2.of(1L, 7L));
list.add(Tuple2.of(2L, 4L));
list.add(Tuple2.of(1L, 5L));
list.add(Tuple2.of(2L, 2L));
list.add(Tuple2.of(2L, 5L));
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
// 使用 ValueState<T> 计算平均数
test01(environment);
test02(environment);
test03(environment);
// 5. 启动任务 - Execute
try {
environment.execute("CountAverageStateJob");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 通过ValueState<T> 计算平均数
*
*/
public static void test01(StreamExecutionEnvironment environment) {
environment.fromCollection(list)
.keyBy(data -> data.f0)
.flatMap(new CountAverageWithValueState())
.print();
}
/**
* 通过MapState<T> 计算平均数
*
*/
public static void test02(StreamExecutionEnvironment environment) {
environment.fromCollection(list)
.keyBy(data -> data.f0)
.flatMap(new CountAverageWithMapState())
.print();
}
/**
* 通过ListState<T> 计算平均数
*
*/
public static void test03(StreamExecutionEnvironment environment) {
environment.fromCollection(list)
.keyBy(data -> data.f0)
.flatMap(new CountAverageWithListState())
.print();
}
}
class CountAverageWithValueState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Double>> {
// 记录求平均数的状态,需要记录条数和总和
private transient ValueState<Tuple2<Long, Long>> valueState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 初始化valueState
valueState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple2<Long, Long>>("valueState",
Types.TUPLE(Types.LONG, Types.LONG)));
}
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Double>> output) throws Exception {
// 将 条数 和 总和 放到state中去
Tuple2<Long, Long> currentState = valueState.value();
if (null == currentState) {
currentState = Tuple2.of(0L, 0L);
}
// 次数
currentState.f0 += 1;
// 总和
currentState.f1 += input.f1;
// 更新状态
valueState.update(currentState);
// 达到3条数据求平均数
if (currentState.f0 >= 3) {
output.collect(Tuple2.of(input.f0, currentState.f1 / currentState.f0.doubleValue()));
// 清空状态
valueState.clear();
}
}
}
class CountAverageWithMapState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Double>> {
// 记录求平均数的状态,需要记录条数和总和
private transient MapState<String, Long> mapState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 初始化mapState
mapState = getRuntimeContext().getMapState(new MapStateDescriptor<String, Long>("mapState", Types.STRING, Types.LONG));
}
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Double>> output) throws Exception {
// 初始化mapState
mapState.put(UUID.randomUUID().toString(), input.f1);
// 拿到map中所有的值
List<Long> list = Lists.newArrayList(mapState.values());
if (list.size() >= 3) {
// 求平均数
Long count = 0L;
Long sum = 0L;
for (Long value : list) {
count += 1;
sum += value;
}
output.collect(Tuple2.of(input.f0, sum / count.doubleValue()));
// 清空状态
mapState.clear();
}
}
}
class CountAverageWithListState extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Double>> {
private transient ListState<Long> listState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 初始化mapState
listState = getRuntimeContext().getListState(new ListStateDescriptor<Long>("listState", Types.LONG));
}
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Double>> output) throws Exception {
// 初始化mapState
listState.addAll(Lists.newArrayList(input.f1));
// 得到全部数据
Iterable<Long> iterable = listState.get();
// 遍历listState
Long count = 0L;
Long sum = 0L;
for (Long value : iterable) {
count += 1;
sum += value;
if (count >= 3) {
output.collect(Tuple2.of(input.f0, sum / count.doubleValue()));
// 清空状态
listState.clear();
}
}
}
}通过BroadcastState关联数据流
package itechthink.broadcast;
import itechthink.twojoin.OrderInfo;
import itechthink.twojoin.OrderItem;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* 通过广播关联数据流
*
*/
public class BroadcastStreamJob {
public static void main(String[] args) {
// 1. 准备环境 - Environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
/*
* OrderInfo订单数据流
*
*/
SingleOutputStreamOperator<OrderInfo> orderInfoStream = environment.socketTextStream("localhost", 9528)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, OrderInfo>() {
@Override
public OrderInfo map(String input) throws Exception {
String[] split = input.split(",");
return new OrderInfo(Long.parseLong(split[0].trim()),
split[1].trim(),
Long.parseLong(split[2].trim()),
Double.parseDouble(split[3].trim())
);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<OrderInfo>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(
new SerializableTimestampAssigner<OrderInfo>() {
@Override
public long extractTimestamp(OrderInfo orderInfo, long record) {
return orderInfo.getTime();
}
}
)
);
/*
* OrderItem订单详情数据流
*
*/
SingleOutputStreamOperator<OrderItem> orderItemStream = environment.socketTextStream("localhost", 9529)
.filter(StringUtils::isNoneBlank)
.map(new MapFunction<String, OrderItem>() {
@Override
public OrderItem map(String input) throws Exception {
String[] split = input.split(",");
return new OrderItem(Long.parseLong(split[0].trim()),
Long.parseLong(split[1].trim()),
Long.parseLong(split[2].trim()),
split[3].trim(),
Integer.parseInt(split[4].trim()),
Double.parseDouble(split[5].trim())
);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.<OrderItem>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(
new SerializableTimestampAssigner<OrderItem>() {
@Override
public long extractTimestamp(OrderItem orderItem, long record) {
return orderItem.getTime();
}
}
)
);
// 将OrderInfo流(维表)定义为广播流
final MapStateDescriptor<Long, OrderInfo> orderInfoBroadcastDescriptor = new MapStateDescriptor<>("OrderInfoBroadcastState", Long.class, OrderInfo.class);
/*
* 由非广播流来进行调用
* 输入订单OrderInfo数据:
* 1,order1,1000,300
* 2,order2,2000,500
* 3,order3,3000,800
* 输入订单详情OrderItem数据:
* 1,1,1000,A,1,200
* 2,1,2000,B,1,100
* 3,2,5000,A,1,200
* 4,2,6000,A,1,200
* 5,3,11000,B,1,100
* 输出结果:
* 收到广播数据:{orderId=1, name='order1', time=1000, money=300.0}
* 收到广播数据:{orderId=2, name='order2', time=2000, money=500.0}
* 收到广播数据:{orderId=3, name='order3', time=3000, money=800.0}
* ({itemId=1, orderId=1, time=1000, sku='A', amount=1, money=200.0},order1)
* ({itemId=2, orderId=1, time=2000, sku='B', amount=1, money=100.0},order1)
* ({itemId=3, orderId=2, time=5000, sku='A', amount=1, money=200.0},order2)
* ({itemId=4, orderId=2, time=6000, sku='A', amount=1, money=200.0},order2)
* ({itemId=5, orderId=3, time=11000, sku='B', amount=1, money=100.0},order3)
*/
orderItemStream
.connect(orderInfoStream.broadcast(orderInfoBroadcastDescriptor))
.process(new JoinBroadcastProcessFunction(orderInfoBroadcastDescriptor))
.print()
.setParallelism(1);
// 5. 启动任务 - Execute
try {
environment.execute("TwoDataStreamJoinJob");
} catch (Exception e) {
e.printStackTrace();
}
}
}
class JoinBroadcastProcessFunction extends BroadcastProcessFunction<OrderItem, OrderInfo, Tuple2<OrderItem, String>> {
// 用于存储规则名称与规则本身的map
private MapStateDescriptor<Long, OrderInfo> broadcastDesc;
JoinBroadcastProcessFunction(MapStateDescriptor<Long, OrderInfo> broadcastDesc) {
this.broadcastDesc = broadcastDesc;
}
// 负责处理广播流的元素
@Override
public void processBroadcastElement(OrderInfo orderInfo,
BroadcastProcessFunction<OrderItem, OrderInfo, Tuple2<OrderItem, String>>.Context ctx,
Collector<Tuple2<OrderItem, String>> out) throws Exception {
System.out.println("收到广播数据:" + orderInfo);
// 得到广播流的存储状态
ctx.getBroadcastState(broadcastDesc).put(orderInfo.getOrderId(), orderInfo);
}
// 处理非广播流关联维度
@Override
public void processElement(OrderItem orderItem,
BroadcastProcessFunction<OrderItem, OrderInfo, Tuple2<OrderItem, String>>.ReadOnlyContext ctx,
Collector<Tuple2<OrderItem, String>> out) throws Exception {
// 得到广播流的存储状态
ReadOnlyBroadcastState<Long, OrderInfo> state = ctx.getBroadcastState(broadcastDesc);
out.collect(new Tuple2<>(orderItem, state.get(orderItem.getOrderId()).getName()));
}
}感谢支持
更多内容,请移步《超级个体》。