
执行计划(下)
查询成本的计算
全表扫描的成本计算
不管是单表关联还是多表关联,对于SQL查询优化器来说,其实都是有多种执行计划可供选择的,那么如何能够保证MySQL选择一个成本最低,效率最佳的执行计划呢?
但问题是,怎么确定成本呢?
MySQL首先会对查询计算一个全表扫描的成本,计算方法如下。
通过
SHOW TABLE STATUS LIKE "表名"得到表的统计信息,其中data_length为表的聚簇索引字节数,而表的数据页数量 = data_length / 1024 / 16(每页默认16KB大小)。I/O成本:数据页数量 + 微调值。CPU成本:行记录数 * 0.2。扫描总成本=I/O成本+CPU成本。
索引的成本计算
计算完全表扫描成本后,当有多个索引可以使用时,需要通过比较成本来确定应该使用哪个索引。
二级索引的成本计算,都是本身的查询成本 + 回表操作成本,MySQL会估算从二级索引里能查出多少行数据。
查询成本= 估算查询出的数据条数 * 0.2。回表成本(回表到聚簇索引查询) = 数据条数(一条按一页算) + 微调值。比较成本(对查询到的完整数据进行判断) = 数据条数 * 0.2。索引总成本= 查询成本 + 回表成本 + 比较成本。
每个索引都会计算一遍查询成本,然后从中选择成本最低的执行。
基于多表的成本计算
单表查询时,MySQL会对这张表的多种访问方式(全表扫描或索引查询)进行计算,算出每种访问方式的成本,然后再选择一个成本最低的方式,多表查询和这类似。
多表查询时在每张表上都执行成本计算方法,确定每张表上成本最低的访问方法,然后汇总在一起,就完成了多表关联查询。
优化执行计划
常量替换
仅仅对查询做成本计算,然后选择其中一种来执行还是不够的,MySQL在执行一些较为复杂的SQL语句时可能会对查询进行重写,以便优化具体的执行计划。
其中一个优化方法就是常量替换。
将
f1 > 1 AND f2 > f1替换为f1 > 1 AND f2 > 1。删除一些无意义的
SQL子句,比如f1 = f1。SELECT * FROM t1, t2 WHERE t1.id = x AND t1.f1 = t2.f1执行时可能会先查出t1中id=x的那行数据,然后将*号中t1表的部分全部替换为这行数据字段中的值,再来和t2关联。
> SELECT t1中id=x数据行中个字段值, t2.* FROM t1, t2 WHERE t1.id = x AND id=x的t1表f1字段值 = t2.f1;子查询优化
对于简单子查询SELECT * FROM t1 WHERE f1 = (子查询),无非就是先执行子查询里面的单表查询,然后再执行子查询之外的单表查询,也就是分成了两个单表查询,索引规则、成本计算、优化规则等方式和单表没什么不同。
但如果用IN来执行SELECT * FROM t1 WHERE f1 IN (子查询),就会和之前的方式不太一样。
MySQL依然会先执行子查询(和单表查询优化方式一样),但会把子查询的结果都写到一个临时中间表中,并且会对这个临时表创建索引(重点:临时表有索引)。
然后会比较外层表
t1和这个临时表的数据量,如果外层表和临时表数据量差不多,就可以到外层表中查询每行数据中的f1字段值是否在临时表中。反过来,如果外层
t1表的数据量远远大于临时表,那么MySQL会逆向思考,在临时表查询每行数据是否都在外层t1表的索引树里。也就是说,一个是对t1表做全表扫描,然后去和临时表做比较,一个是对临时表做全表扫描,然后去和t1表做比较,当两张表数据量相差巨大的时候,性能提升是很明显的。
这一点可以通过实验来说明。
--- 删除表
> DROP TABLE IF EXISTS t_test_5;
-- 复制表
> CREATE TABLE t_test_5 AS SELECT * FROM t_test;
-- 指定主键
> ALTER TABLE t_test_5 MODIFY id INT(11) NOT NULL PRIMARY KEY;
-- 增加字段
> ALTER TABLE t_test_5 ADD COLUMN sort TINYINT(1) NOT NULL DEFAULT '0';
-- 创建索引
> CREATE INDEX t_test_5_name ON t_test_5 (name);
-- 删除表
> DROP TABLE IF EXISTS t_test_6;
-- 复制表
> CREATE TABLE t_test_6 AS SELECT * FROM t_test;
-- 指定主键
> ALTER TABLE t_test_6 MODIFY id INT(11) NOT NULL PRIMARY KEY;
-- 增加字段
> ALTER TABLE t_test_6 ADD COLUMN sort TINYINT(1) NOT NULL DEFAULT '0';
-- 创建索引
> CREATE INDEX t_test_6_name ON t_test_6 (name);再执行下面的SQL语句。
> EXPLAIN SELECT * FROM t_test_5 WHERE name IN (SELECT name FROM t_test_6 WHERE id = 1);
> EXPLAIN SELECT * FROM t_test_5 WHERE name IN (SELECT name FROM t_test_6 WHERE id IN (1,2,3));然后观察执行结果。
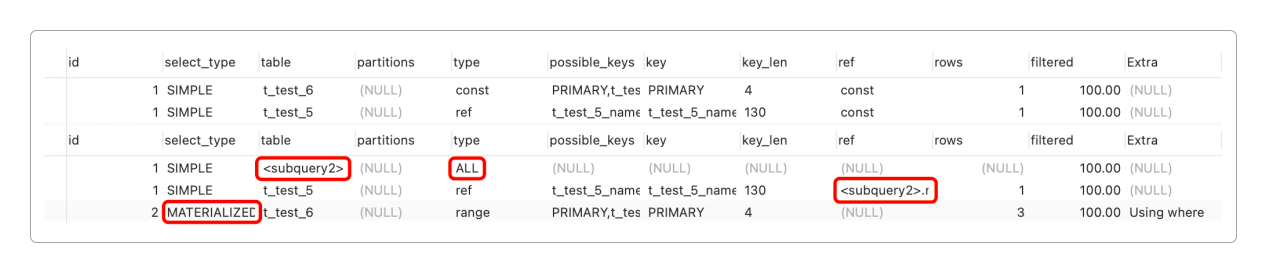
结果非常清楚地显示了子查询是如何优化的。
子查询结果被
物化成了临时表(type = MATERIALIZED),物化表名为<subquery2>。对物化表
<subquery2>做全表扫描,来匹配外层t_test_5数据。
半连接
SQL查询中有左连接、右连接、内连接和外连接,但还有一种连接方式,称为半连接(Semi Join),它可能会将一个子查询转化为另一种形式。
> SELECT * FROM t1 WHERE f1 IN (SELECT f2 FROM t2 WHERE f3 = "x");
# 转化为
> SELECT t1.* FROM t1 SEMI JOIN t2 ON t1.f1 = t2.f2 AND t2.f3 = "x";SEMI JOIN并不是提供给开发者的,而是MySQL内核中的优化方式,就是把IN子查询转变成两表关联语义。
半连接并不是所有场景都适用,甚至还会造成性能的下降,可以通过指令关闭半连接。
> SET optimizer_switch='semijoin=off';关闭之后再次执行之前的实验SQL,观察执行结果。

结果显示:外层表做了全表扫描,子查询变化不大。
更多的type类型
之前已经通过实验展示了const、ref、range、index、index_merge等查询方式,下面的SQL语句展示了更多的查询方式。
-- NULL
> EXPLAIN SELECT min(id) FROM t_test;
-- const
> EXPLAIN SELECT * FROM t_test where id = 1;
> EXPLAIN SELECT * FROM t_test_5 where name = "1242740190540349440";
-- PRIMARY/DEPENDENT SUBQUERY、index_subquery、func
-- index_subquery也是用来替换非唯一索引的IN子查询
> EXPLAIN SELECT * FROM t_test_5 WHERE name IN (SELECT name FROM t_test_6) OR id = 22;
> SHOW WARNINGS;
-- UNION/UNION RESULT、<union1, 2>
> EXPLAIN SELECT * FROM t_test_5 UNION SELECT * FROM t_test_6;
-- DEPENDENT SUBQUERY/DEPENDENT UNION/UNION RESULT、<union2,3>、func
> EXPLAIN SELECT * FROM t_test WHERE name IN (SELECT name FROM t_test_5 UNION SELECT name FROM t_test_6);
> SHOW WARNINGS;
-- DERIVED、<derived2>、Using temporary; Using filesort
> EXPLAIN SELECT * FROM (SELECT id, COUNT(0) AS count FROM t_test GROUP BY id) AS t WHERE count > 0;在之前的实验中可以看出,日常开发工作中尽量写简单的SQL,复杂的逻辑最好通过应用层代码,比如Java来实现,能用单表查询的就不要用多表关联查询,能多表关联就尽量不用子查询。
一般的系统,只要SQL语句能够尽量简单、建好必要的索引,性能往往不是问题。
在了解了一些简单、常用的优化规则之后,就可以来稍稍总结一下MySQL的执行计划了。
执行计划总结
explain命令
学习了解EXPLAIN并对执行计划做了简单分析,是SQL调优的必经之路。
之前一直使用EXPLAIN命令来查看执行计划的内容,其实就是一张表,记录执行过程中的各种状态、数据及额外信息,但并没有作出比较详细的说明,现在来看看EXPLAIN命令以及它展示出来的结果的各个字段的详细含义。
EXPLAIN对SELECT完全有效,对UPDATE弱有效(能用到索引),分析不了INSERT、DELETE(如果想让EXPLAIN对INSERT起作用,可以将它转化为SELECT ...... INTO)。EXPLAIN无法分析存储过程、触发器和函数的执行计划,也不显示各种Cache对查询的影响,虽然实际执行时会有不同。EXPLAIN不区分名字相同的事物,比如内存和磁盘中的文件排序都是filesort,而内存和磁盘中的临时表都是Using temporary,也区分不出单个字段的索引和联合索引。EXPLAIN不显示MySQL对执行计划所做的每一个优化,比如临时表中的索引,也无法显示出查询的成本高低,总体上而言就是一个观察窗口有限的白盒。
执行计划各字段含义
| 字段 | 说明 |
|---|---|
| id | 显示查询序号,id值越大优先级越高,越先被执行(值也可以是NULL) |
| select_type | 用于区别普通查询、多表关联查询、子查询等不同类型的查询 |
| table | 当前正在执行查询的是哪张表,取值也可能是<union1,2>联合表、<derivedN>或<subqueryN>临时表等 |
| partitions | 5.7版之前是explain partitions显示的选项,5.7后成为了默认选项,如果table是分区表,那么显示的是分区表命中的分区,非分区表该字段为null |
| type | 表示查询在表中是怎么找到所需数据行的,跟性能强相关,从最好到最差依次是:NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,但常见的就只有:system > const > eq_ref > ref > range > index > all |
| possible_keys | 可能应用在正在执行查询的表中的索引,为null表示没有可能用到的索引,这个字段需要与type结合起来看 |
| key | 实际使用的索引,为null表示没有使用任何索引 |
| key_len | 索引里最大值的字节长度,长度是可截取的,越短越好 |
| ref | 在使用到的索引中,所用到的查找方式,常见的有常量(const)、字段名(例如<subquery2>.name)、func或NULL |
| rows | 根据表统计信息及索引选用情况,大致估算出找到记录所需要读取并检测的行数(不是结果集里的行数) |
| filtered | 5.7版之前是explain extended显示的选项,5.7后成为了默认选项,表示经过搜索条件过滤后返回的数据行数占需要读取的行数(rows列的值)的百分比 |
| extra | 查询的额外信息,比如Using index、Using where |
explain命令总结
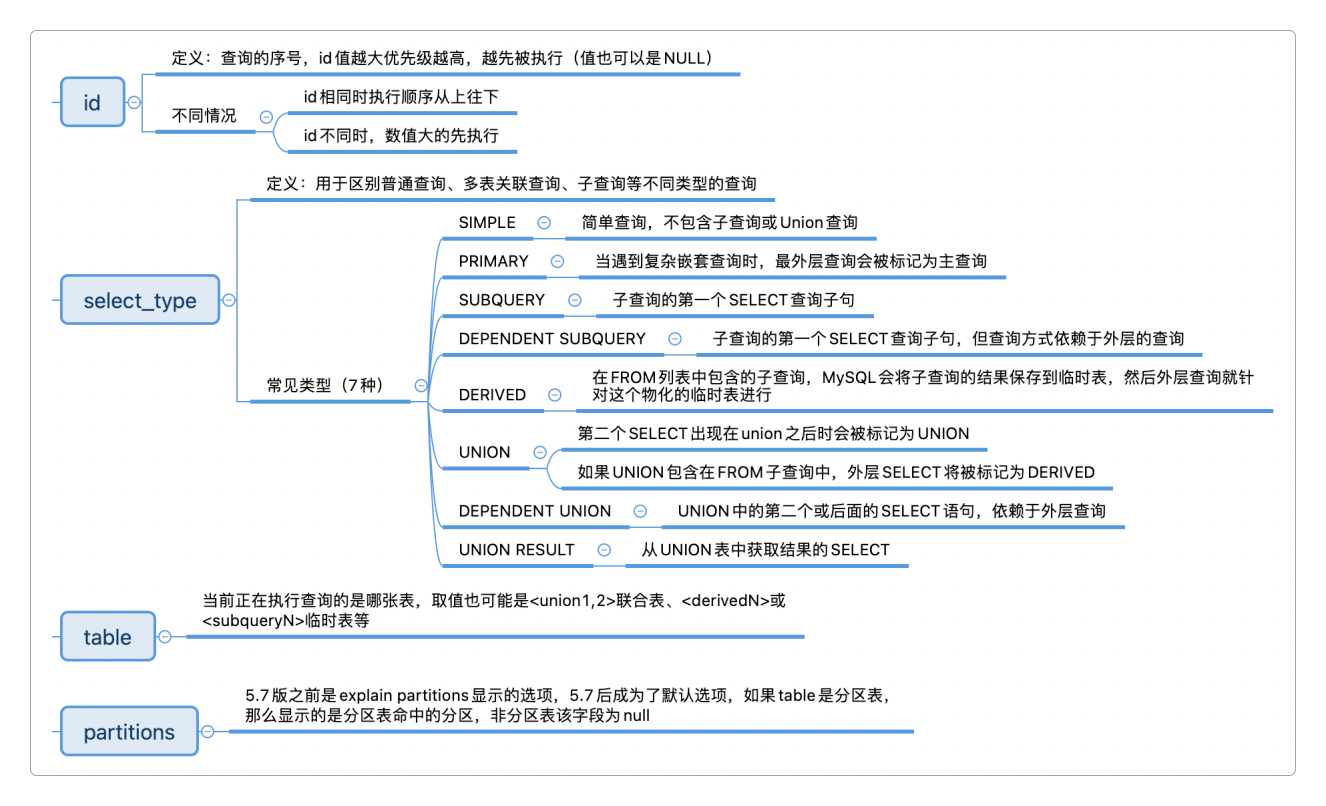

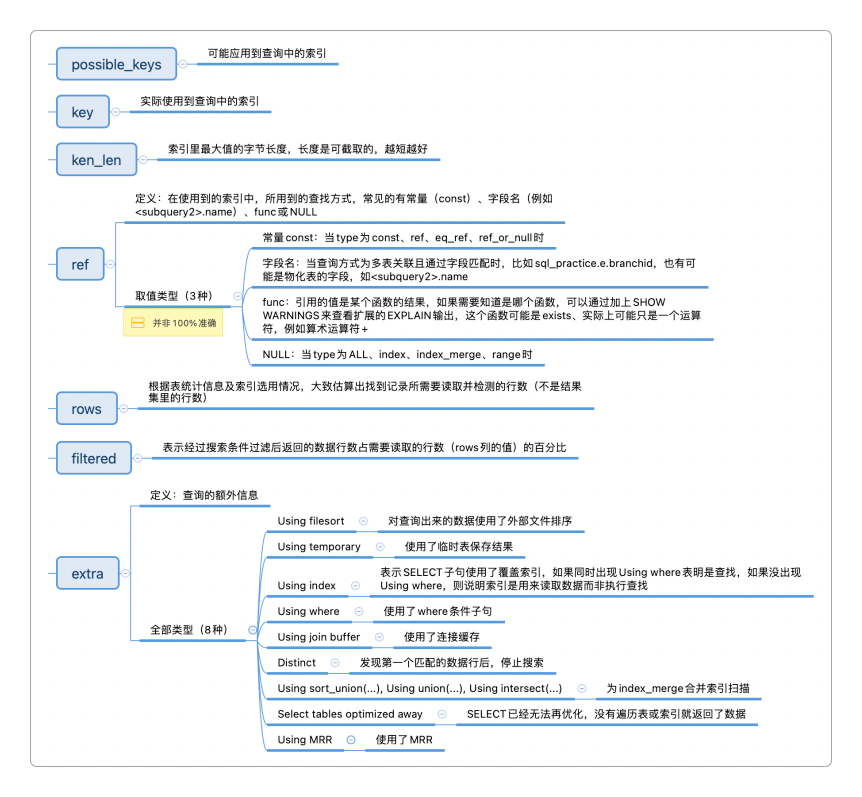
千万不要死记硬背每个字段的各种可能取值的含义,因为毫无必要——常用的取值可能就那么几个,即使是特别复杂的SQL查询,也不会所有的取值都出现,见招拆招就行了。
而且explain表中的字段也不是每个都需要关注,比较重要的也就是select_type、type、ref这三列,尤其是type,非常关键,它直接决定了查询是如何从表里面拿到数据的,和性能的好坏紧密相关。
EXPLAIN最权威的官方解释在这里。
感谢支持
更多内容,请移步《超级个体》。