
索引实践
设计原则一
在设计完表结构之后,不用马上就加索引,因为此时根本不知道会经常查询哪些数据,也就不知道怎么加索引合适。
当系统差不多开发完毕了,功能都跑通了,就可以考虑该如何创建索引了。
设计索引的第一条原则:针对SQL查询语句中的WHERE条件子句、ORDER BY排序子句和GROUP BY分组子句中出现的字段设计索引。
尽量利用联合索引,联合索引尽量包含WHERE、ORDER BY和GROUP BY中出现的字段,而且遵循最左列匹配原则、等值匹配原则和范围匹配原则。
设计原则二
字段基数是指某个字段的取值范围,比如对于某些状态字段,可能就只能取0或1两个值,所以它的基数就是2。
给这种基数极少的字段建立索引,还不如做全表扫描——也就是说,建立索引的时候,尽量使用基数较大的字段,这样才能发挥出B+树快速二分查找的优势。
尽量针对那些字段类型比较小的列来设计索引——因为字段类型小,所以占用磁盘空间小,搜索时性能也比较好一点——即便是对于像varchar(256)这样有一定长度的字段,可以仅仅针对这类字段的前若干个字符建立前缀索引,减少数据长度(只不过这种截取长度的字段是不能用到ORDER BY或者GROUP BY之中的)。
设计原则三
查询时语句中的字段如果参与函数或者计算,是没法利用索引的。
由于不停的增删改,聚簇索引和相应的二级索引也会不停更新,因此二级索引不要太多,如果通过两三个联合索引就能覆盖掉所有需要索引的字段就最理想了。
主键最好用MySQL自增字段,或者用自增长整型,禁止使用像UUID这类字符串主键,因为自增主键不会频繁地分裂而且有序,但UUID既会频繁分裂增加数据库压力,本身也是无序的。
社交APP的索引设计
当用户注册时,需要录入一系列个人信息,然后可能会通过一定的算法给用户推荐符合的交友对象,比如附近的人、陌生人社交等。
在筛选匹配对象的时候,就需要通过一系列的条件进行过滤,这就会查询存储在MySQL用户表中的各个字段数值了。
假设user表中需要存储这些字段:用户名、密码、真实姓名、性别、年龄、身份证号、身高、体重、民族、省份、城市、区县、爱好、性格、头像、最后一次登录时间、关注数、被关注数、综合评价、信用等级。
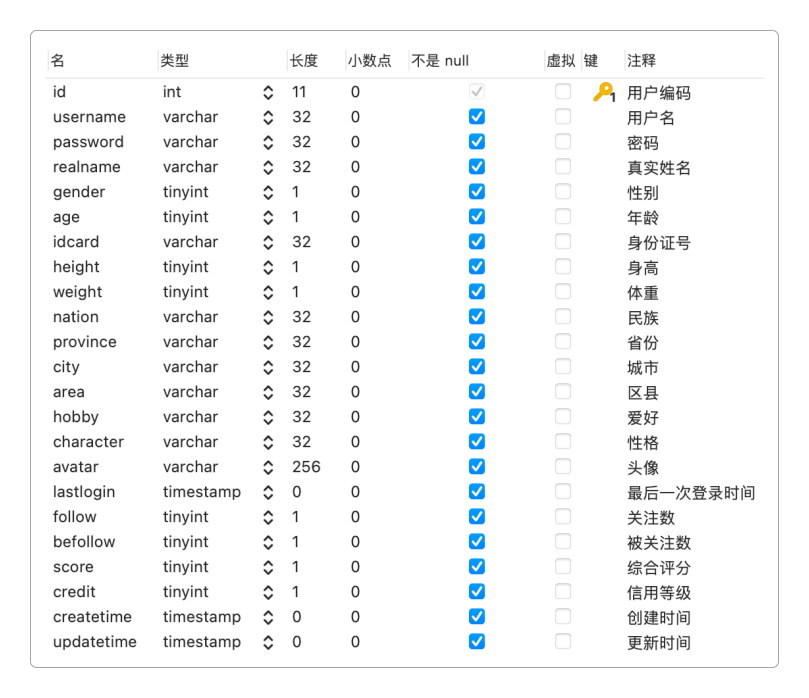
实际问题一
往往在实际开发中,WHERE和ORDER BY中的字段并不相同,而且还可能有冲突。
> SELECT * FROM user WHERE weight BETWEEN 160 AND 260 AND height BETWEEN 170 AND 180 ORDER BY score;在联合索引中,类似于分数、等级字段一般都不会在最左侧,但却经常需要根据它们来排序。
实际问题二
当WHERE和ORDER BY出现冲突的时候,到底是针对WHERE设计索引,还是针对ORDER BY设计索引呢?
也就是说,到底是先基于WHERE筛选出数据后再进行排序还是先通过联合索引做了排序再筛选数据呢?——大多数情况下,都会 优先基于WHERE筛选后再做排序,而且在分页条件下,每次筛选出来的数量都不会太大,对排序造成的影响有限。
需要针对哪些字段创建联合索引呢?——这个应该取决于实际业务场景,以社交应用为例来说的话是这样的。
- 首先将
省份、城市、性别、年龄这四个字段组成联合索引(province, city, gender, age),因为这是交友时的首要关注点。
此时的WHERE语句就可以像下面这样写。
> WHERE province = "x" AND city = "y" AND gender IN (0, 1) AND age BETWEEN 20 AND 30;- 至于字段基数问题,如果因为基数小就不做成联合索引,那么肯定会在索引查询之外再对这几个字段进行过滤,那就还不如把它们加到索引里去——规则也需要依据实际场景进行变通。
实际问题三
除了省份、城市、性别、年龄这四个字段组成的联合索引,可能爱好、性格也会有一些高频出现的选项。
如爱好中的旅游、读书、烹饪,性格中的暖男、御姐等,完全可以把它们加入到联合索引中去,形成(province, city, gender, hobby, character, age)这样的联合索引。
此时的WHERE语句就可以像下面这样写。
> WHERE province = "x" AND city = "y" AND gender IN (0, 1) AND hobby IN ("旅游", "读书", "烹饪") AND character IN ("暖男", "御姐") AND age >= 20 AND age <= 30;如果联合索引中有些查询条件不需要,可以用IN(所有枚举值)的方式加入到SQL语句中,这样可以让所有查询条件都用上索引,且不会导致索引条件中断。
- 之所以把
age字段放在最后,是因为依据等值匹配+范围匹配的原则,应该优先让联合索引最左侧开始的字段进行等值匹配,然后接着最后一个字段才是范围匹配——一旦有字段利用了范围匹配,那么后续的字段就都无法再利用索引了。
实际问题四
如果还需要依据用户最近的登录时间来筛选——例如近三天登录过的用户——该怎么处理呢?
因为即使是将联合主键设计成(province, city, gender, hobby, character, age, lastlogintime)这样,但按照范围匹配规则,如果age利用了范围查询,那么lastlogintime是无法再用到索引的。
可以通过一个设计技巧解决:保留lastlogintime字段,增加一个islastlogintimein3days字段,类型tinyint,0为false,1为true,这样一来,联合主键就成了(province, city, gender, hobby, character, islastlogintimein3days, age)。
此时的WHERE语句就可以像下面这样写。
> WHERE province = "x" AND city = "y" AND gender IN (0, 1) AND hobby IN ("旅游", "读书", "烹饪") AND character IN ("暖男", "御姐") AND islastlogintimein3days = 1 AND age >= 20 AND age <= 30;实际问题五
如果仅仅只是需要使用联合索引中某些基数很低的字段,比如性别,来进行筛选该怎么处理呢?因为由于字段基数小,可能某个状态就会有几百万条数据行,如果这时候还要在进行排序,性能可能就非常差了。
针对这个问题,可以将这类字段再加上排序字段单独创建一个辅助联合索引,专用于解决WHERE条件里低基数字段查询后排序分页的问题,比如(gender, score)。
> WHERE gender = 1 ORDER BY score LIMIT 100;此时score是可以利用到索引的,因为通过gender筛选出来数据后,剩下的原本就是按照score进行排序的,当然是可以利用到索引的了。
依此类推,用查询频率较高的主联合索引完成80%场景下的复杂WHERE条件筛选,同时针对余下的低基数字段 + 排序/分组的20%的场景,可以设计辅助联合索引来应对。
这种方式的核心重点是:尽量利用一两个复杂的多字段主联合索引,满足80%应用场景的查询需求,然后用一两个辅助联合索引满足剩下20%应用场景的查询需求——高低结合,保证99%以上的查询语句都能充分利用索引提升性能。
感谢支持
更多内容,请移步《超级个体》。