
索引(上)
数据页的存储结构
数据库中所有的数据,最终都是要存放到磁盘上的,而对应的磁盘文件,对于数据库管理系统RDBMS来说,其实都是一个个数据页的集合。
数据页是按顺序一页页存放的,相邻的数据页之间会采取双向链表的形式相互引用。在数据页内部会存储一行行的数据,每一行数据都会按照主键大小进行排序存储,每一行数据都有指针指向下一行数据的位置,数据行之间组成单向链表。
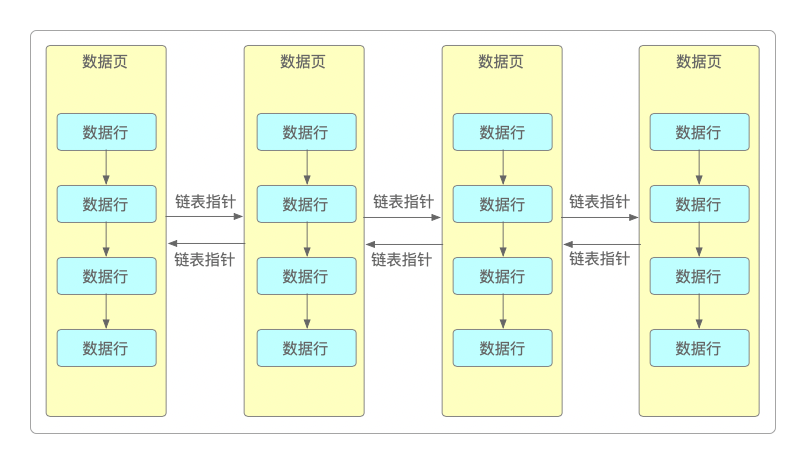
磁盘数据检索
数据行的主键是被分散存储到磁盘上不同「槽位」里面去的,每个数据页都会有一个页目录,记录的是每个数据行的主键槽位。
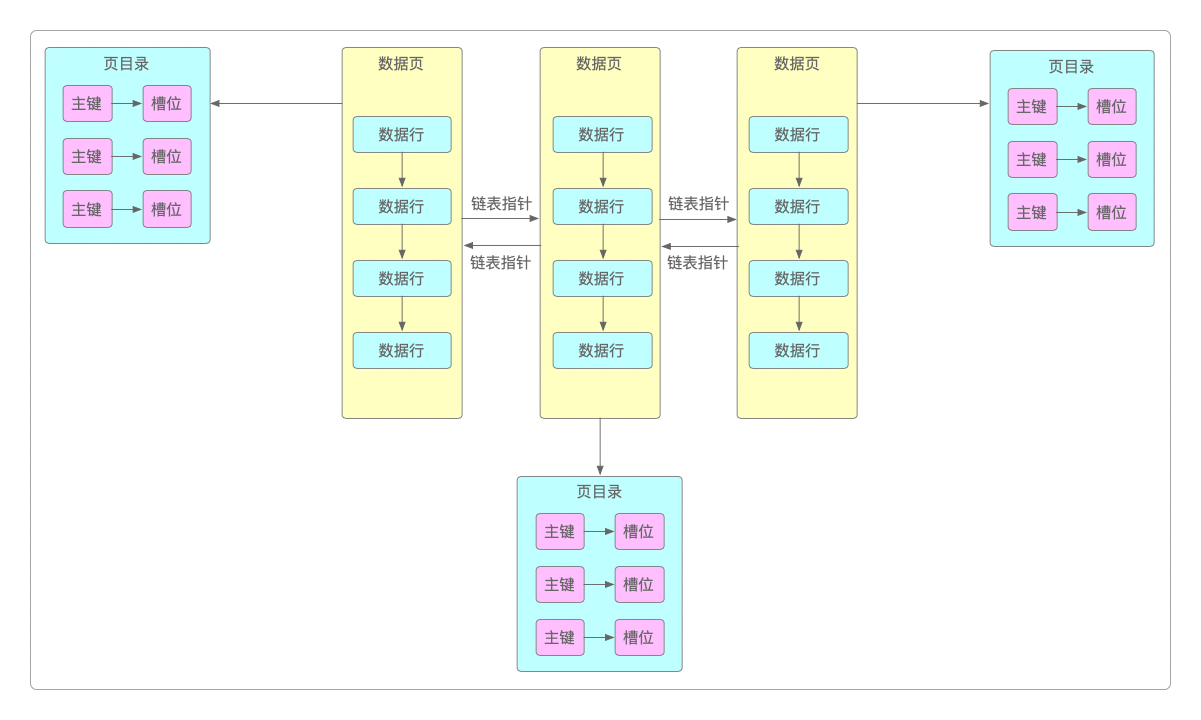
当数据量不大时,会先到数据页的页目录中根据主键进行二分查找,然后定位到主键所在的槽位,遍历槽位里每一行数据,就能快速找到主键对应的数据了。
如果是非主键,就只能逐个进入数据页,根据单向链表依次遍历查找,性能很差。如果没有索引,那么无论是主键还是非主键查询,都只能逐个数据页,逐个数据行地遍历查找,极端情况下,会进行全表扫描。
页分裂
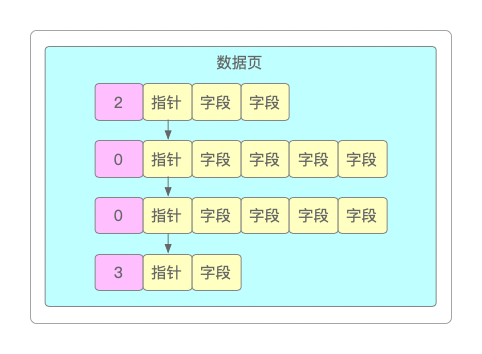
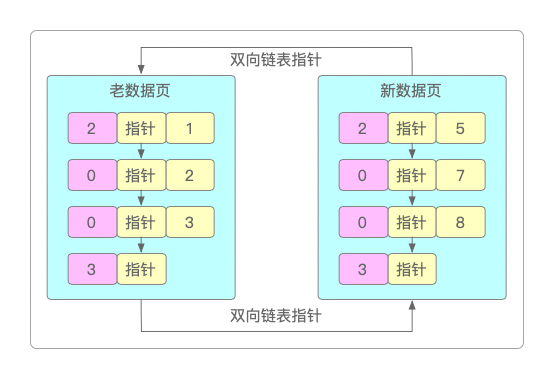
在数据页内部,数据会被组成单向链表,每一行数据都有自己每个字段的值,并且通过指针指向下一行数据,普通数据行的类型都是0,2是最小的一行,3是最大的一行。
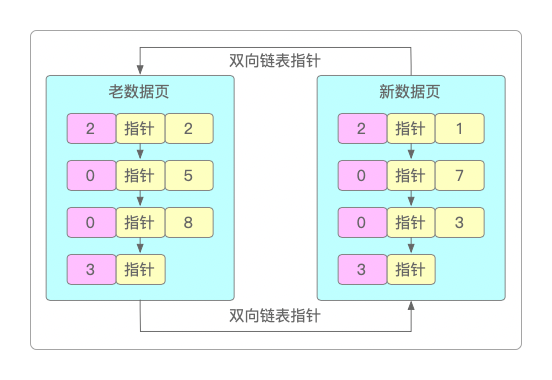
当不断往数据表里插入数据时,为了满足索引机制,一个最基础的要求就是双向链表中,后一个数据页中的最小主键值要大于前一个数据页中的最大主键值。
有时候主键值并不是自增长的,可能会出现较大的主键值跑到前一个数据页的情况,此时就会通过「页分裂」的过程来解决这个问题:在增加一个新的数据页时,会把前一个数据页中较大的主键值,移动到新的数据页中,然后把新插入的较小的主键值挪动到上一个数据页中去,保证做到前述的要求。
老数据页的最大主键值明显是大于新数据页的最小主键值的,需要进行页分裂来调整主键值,以满足老数据页的最大主键值 < 新数据页最小主键值的要求。
主键索引
如果在多个数据页中想要依据主键来查询数据,直接查询是查不到的,因为并不知道主键在哪,这时候除了全表扫描,没有别的办法了。这时就需要针对主键设计一个索引了,这就是一个主键目录。
主键目录,其实就是一个微缩的索引:它把每个数据页的页号,还有数据页的最小主键值放在一起组成一个目录。
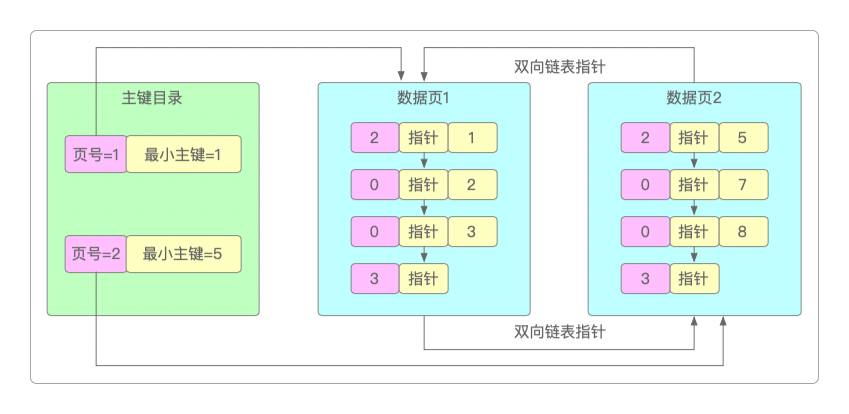
有了主键目录,就可以根据二分查找原理直接定位到某个数据页,这个效率肯定比全表扫描要高很多。
B+树索引
通过包含数据页与最小主键值的主键目录,就可以很方便快速地找到主键所在的那一行数据。但是如果数据量特别大,几千万甚至几亿条数据还能用做成主键目录的方法来处理吗?
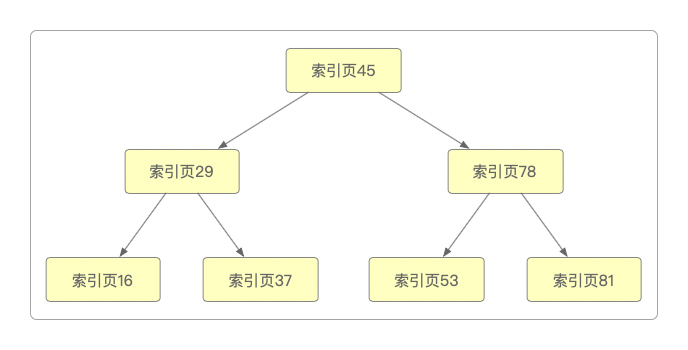
主键目录其实也是一种特殊的页,称为索引页,当索引页多了以后,又该怎么去管理、查找索引页呢?和数据页同样的道理,把索引页也按层级来划分,在更高的层级里,保存每个索引页和索引页中的最小主键值,当页数过多时,继续进行页分裂,当索引页数量足够多的时候,就会逐步形成了一颗树型结构。
之所以说MySQL的索引是按B+树来组织的,就是因为这个原因。
聚簇索引
查找主键的过程就是搜索B+树索引页的过程,依据B+树的特性进行遍历(遍历过程略)。找到主键值所在的索引页后,进入索引页所对应的数据页中再遍历实际主键值,最终找到数据。
之所以能够找到数据页,是因为B+树的叶子结点是存储数据的,而非叶子结点只存储索引——MySQL的B+树的叶子结点就是数据页。
B+树的另一个特性是所有叶子结点都是通过指针连接成一个单向链表的,聚簇索引 = B+树 + 索引页 + 数据页,聚簇索引又叫聚集索引。
典型的B+树结构如下。

聚簇索引默认是按照主键值来组织存储的,在InnoDB中对数据进行操作时,就是直接把数据页放在聚簇索引里面的,而数据也就是直接放在数据页里的,聚簇索引同时遵循数据页分裂的规则,而且在数据页分裂时,也会维护上层的索引数据结构。
如果一个索引页放不下了,聚簇索引也会遵循B+树的规则再创建新的索引页,依此类推。
二级索引
聚簇索引是InnoDB存储引擎默认创建的一套基于主键数据的索引结构,数据表就是直接放在聚簇索引中作为叶子结点的数据页。
除了主键之外,如果需要对其他字段建立索引,甚至是多字段联合索引,该怎么组织索引结构呢?
InnoDB一方面会针对主键建立聚簇索引,另一方面如果要为其他字段创建索引,同样会再建立一颗B+树。
比如,基于username和email字段建立联合索引,那么插入数据时,数据页中仅仅存放主键username和email字段的值,而且都是按照username和email的值进行排序的,也都遵循数据页的分裂规则。
> SELECT * FROM TABLE WHERE username = "xiang" AND email = "123@abc.com";上面的SQL语句,会先根据username和email字段值在二级B+树中查找。
只不过二级B+树的叶子结点也仅仅只包含username、email字段值和对应的主键值,而找不到这行数据完整的全部字段。
为了能找到username和email对应行的全部字段值,还需要进行一个称之为「回表」的操作——根据主键值,继续到聚簇索引中查找对应的主键值,然后再定位到对应数据页的完整数据行,才能找到所需的全部字段值。
其他字段上的索引也是同样的道理,不过就是建立B+树逐层进行二分查找罢了,只不过就是要到主键的聚簇索引中再做一次回表操作,这也是它为什么会被称为聚簇的原因。
感谢支持
更多内容,请移步《超级个体》。