
索引(下)
根页
InnoDB存储引擎通过聚簇索引和二级索引实现对索引页、数据页和数据行的管理,搜索时根据不同的索引来查找主键或非主键字段值,通过页分裂实现对数据页的扩展。
但刚创建的一张新表,是没有这么复杂的结构的,甚至可能只有一个数据页。
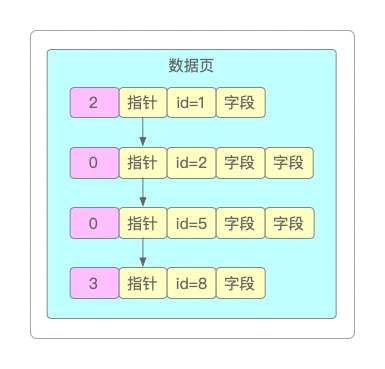
这个初始数据页可以称为原始页/根页,其内部就有一个页目录,直接通过主键来查找会非常快。
当数据不断插入,根页无法存储更多数据时,就通过页分裂创建一个新数据页,同时根据主键值大小进行排序挪动,新数据页的最小主键值一定要大于原始页的最大主键值。
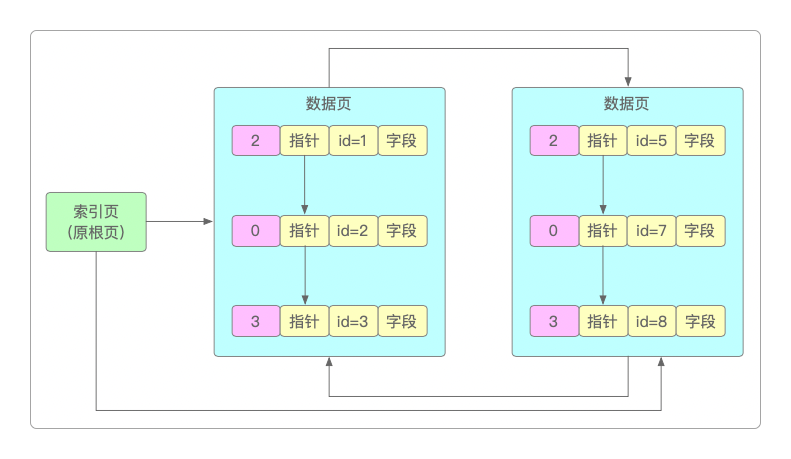
然而之前根页并不是直接变为另一个数据页,而是升级成了索引页,存放的是两个数据页的页号和数据行。
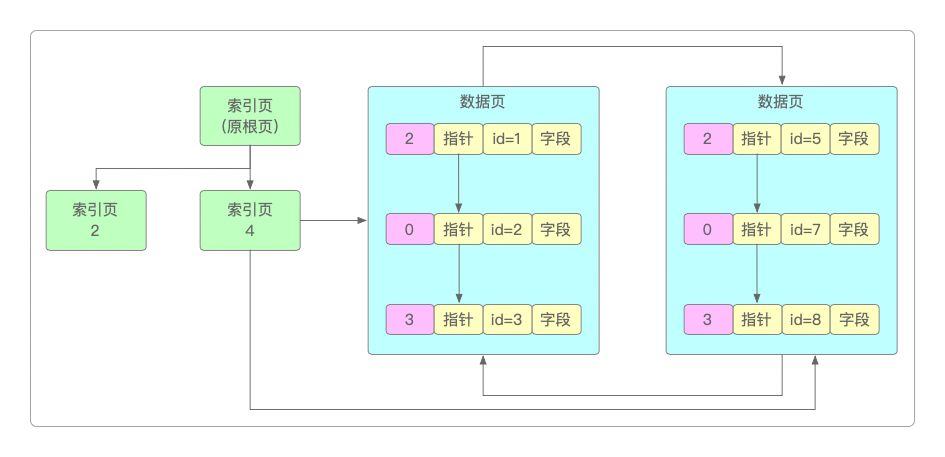
当数据不停插入时,也会不停地创建、分裂出越来越多的数据页。当索引越来越多,就会让索引页也实现页分裂,根页继续向上成为B+树中更高的层级,成为根索引,这就是聚簇索引的维护过程,二级索引也是同样的过程。
索引的特性
在不断插入数据的过程中,MySQL会自动创建聚簇索引和用户指定的二级索引,这是一个不断分裂、排序、重组、挪动的过程。
二级索引是不会保存整行数据全部字段信息的,只有聚簇索引才会,这也是它为什么会被称为聚簇的原因——全部字段信息都聚簇到主键之下。
数据页/索引页的特性如下。
页内数据都是按照大小有序排列并组成单向链表的。
页间数据也是按照大小有序排列并组成双向链表的。
索引太多必然需要更多空间,而且在操作数据时必然要同时维护更多的B+树,需要更多的时间——虽然查询更快了,但增删改却更慢了。
联合索引
假设存在一张用户订单表,主键自增,会自动创建聚簇索引,还有其他几个字段用来保存用户名、商品、数量和金额等信息,可以针对用户名、商品、数量建立联合索引。
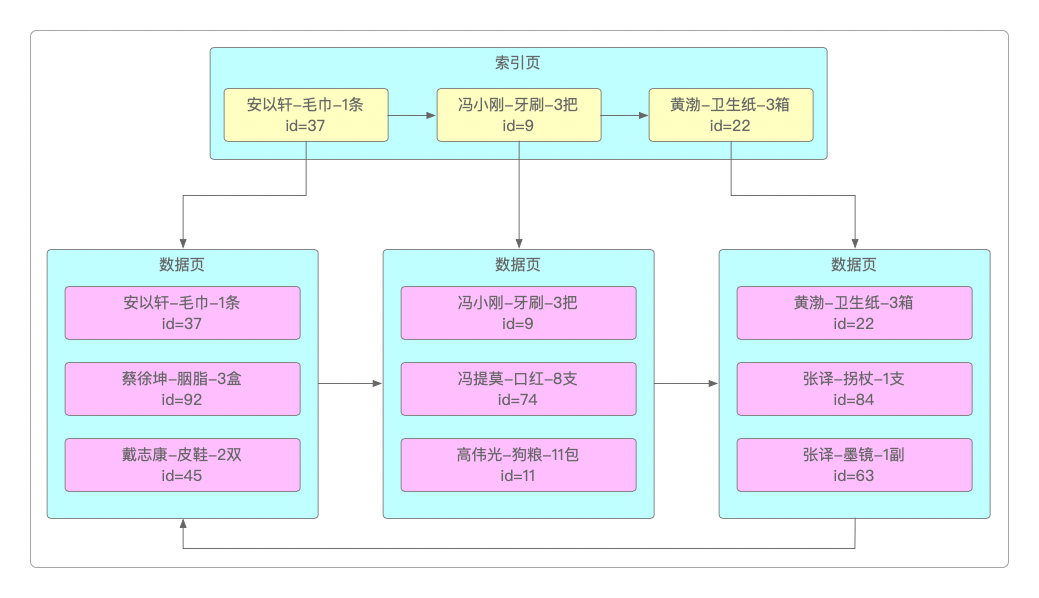
有一个索引页,两个数据页,每个数据页中都有三条数据,每条数据都包含了三个字段的值和主键值。
数据页内部先按照字段名排序,如果用户名相同,则按照商品名排序,而且数据行之间组成了单向链表。
数据页之间也是有序的,前一个数据页的最大值一定小于后一个数据页的最小值。
索引页的每条数据也是有序的,并且也组成了单向链表,分别指向每个数据页的第一条数据。
如果有多个索引页,那么它们之间也会组成双向链表。
现在想要搜索高伟光买狗粮的数据,可能会写出这样的SQL。
> SELECT * FROM order WHERE username="高伟光" AND product="狗粮" AND number=11;当SQL查询条件中的条件都是等号=,并且字段的名称和顺序也和联合索引一模一样的时候,就是全值匹配规则。
对于联合索引而言,就是依照各个字段来逐步进行二分查找,直到定位到某条或某几条数据。
索引使用规则
全值匹配规则
查询时WHERE子句中出现的字段名称和顺序,如果能与联合索引定义的字段名称和顺序完全一致,而且都是通过等号=来定位数据,那么就会100%利用到全值匹配规则,即使不一致,MySQL也会自动优化为按联合索引的顺序去查询。

最左侧列匹配规则
如果查询的字段只有部分联合索引最左侧部分的字段,并且没有跳字段,那么也是符合索引使用规则的,这就是最左侧列匹配规则。
WHERE username="高伟光" AND product="狗粮"符合最左侧列匹配规则。WHERE product="狗粮"不符合最左侧列匹配规则。
因为二级索引的B+树必须先按username查询,再按product查询,不能跳过第一个username字段而直接用第二字段来查,这样是没法高效利用索引的。
WHERE username="高伟光" AND number=11也不符合最左侧列匹配规则。
因为只有username可以利用索引查询,剩下的number是没法在索引里找的,道理同上。

最左前缀匹配规则
如果使用MySQL的LIKE语句做模糊查询,也是可以利用到索引规则的,只需要LIKE "n%"中查询的内容在%前面就行。
> SELECT * FROM TABLE WHERE username LIKE "高伟光%";这条SQL查询语句是可以利用到索引规则的,因为%左侧前缀就是索引中排序的字段,而且是最左侧列字段,可以完全匹配。
但"%高伟光"就不行了,因为在最左侧前缀的%并不是索引中的内容,当然也就利用不了索引了。
实际开发中,DBA、运维及开发工程师可以通过EXPLAIN来检查SQL语句的执行状况,尤其是慢查询的定位,接下来会通过它完成一些索引规则方面的实验。
-- 删除表
> DROP TABLE IF EXISTS t_test_2;
-- 复制表
> CREATE TABLE t_test_2 AS SELECT * FROM t_test;
-- 指定主键
> ALTER TABLE t_test_2 MODIFY id INT(11) NOT NULL PRIMARY KEY;
-- 创建索引
> CREATE INDEX t_test_2_name ON t_test_2 (name);
-- 无索引
> EXPLAIN SELECT * FROM t_test WHERE name LIKE "索引%";
-- 有索引:利用最左前缀匹配规则
> EXPLAIN SELECT * FROM t_test WHERE name LIKE "索引%";
-- 有索引:非最左前缀匹配规则
> EXPLAIN SELECT * FROM t_test WHERE name LIKE "%索引";三条语句的执行结果如下。

type:显示查询在表中是怎么找到所需数据行的,跟性能强相关,从最好到最差依次是:system > const > eq_ref > ref > range > index > all(全表扫描)。rows:根据表统计信息及索引情况,估算找到记录所需读取的行数(越少越好)。filtered:返回结果的行占需要读取的行(rows列的值)的百分比。
范围匹配规则
> SELECT * FROM TABLE WHERE username > "2蛋" AND username < "3娃";当需要使用上面这样的范围查询语句来查找某些数据时,也是会用到索引的。
因为索引最下层的数据页都是有序的双向链表,所以完全可以先找到大于"2蛋"的那些数据页和小于"3娃"的那些数据页,两个数据页中间的那些数据页,就是查找范围内的数据了。
但是如果写成这样就不行了。
> SELECT * FROM TABLE WHERE number > 1 AND number < 5;上面这样的范围查询是无法利用到索引的,因为范围索引只对联合索引最左侧的列有效。
刚才的实验同样可以用范围查找规则再做一次,这里就不重复了。
等值匹配 + 范围匹配规则
> SELECT * FROM TABLE WHERE username = "2蛋" AND product > "361度" AND number < 10;首先
username会通过索引精准定位到一批用户名相同的数据;然后
product也可以基于索引顺序来找;但是
number是无法再利用索引的,虽然它也在联合主键里面——因为一旦有字段利用了范围匹配,那么后续的字段就都无法再利用索引了。
综上所述,最有效利用联合索引的方法如下。
用
索引最左侧的多个字段来进行 全值/等值匹配 + 范围匹配。用
最左侧部分字段实现 最左前缀模糊匹配。
ORDER BY中的索引
> ORDER BY F1 ASC, F2 DESC, F3 ASC LIMIT 200;这类按照多个字段排序后返回前N条数据的查询语句,经常出现于分页的SQL语句中。
对查出来的数据基于磁盘文件或临时中间表来排序,在MySQL的术语中叫filrsort或temporary,如果在EXPLAIN的extra的字段中出现这两种统计结果,那基本意味着MySQL随时可能卡死。
为了能更好说明问题,可以接着之前的数据表来做实验,去掉WHERE子句,只用ORDER BY来观察结果。
-- 无LIMIT限定的ORDER BY
> EXPLAIN SELECT * FROM t_test ORDER BY name;
> EXPLAIN SELECT * FROM t_test_2 ORDER BY name;
-- 有LIMIT限定的ORDER BY
> EXPLAIN SELECT * FROM t_test ORDER BY name LIMIT 100;
> EXPLAIN SELECT * FROM t_test_2 ORDER BY name LIMIT 100;
可以看到,在没有LIMIT限定的情况下,即使是有索引的表,在ORDER BY中同样出现了可怕的filesort。
所以,不要觉得有了索引做任何查询都万事大吉了。
应该尽量按照联合索引的字段顺序查询数据。
对于查询返回的数据尽量加上
LIMIT限定,哪怕做全值匹配的精准查询,也建议加上LIMIT 1,保持好习惯。另外,由于联合索引都是按照从小到大排序的。
ORDER BY要么就默认ORDER BY F1, F2, F3 LIMIT 10。ORDER BY要么就都加ORDER BY F1 DESC, F2 DESC, F3 DESC LIMIT 10。如果有的字段按升序排列,有的字段按降序排列,或者有的字段使用了复杂的函数,都是无法利用索引的。
GROUP BY中的索引
有时候在查询时,会需要用到GROUP BY进行数据分组,然后做聚合统计。
同样,为了验证查询效率,可以接着做实验。
-- 无索引
> EXPLAIN SELECT COUNT(0) FROM t_test GROUP BY name;
-- 有索引
> EXPLAIN SELECT COUNT(0) FROM t_test_2 GROUP BY name;
可以看到,在没有索引的表,filesort和temporary居然同时出现。
所以,GROUP BY之后的字段,也需要按照联合索引中的最左侧列匹配规则来执行,这样就可以完美地运用索引来直接提取分组数据(至于加或不加LIMIT的区别,这里就略过)。
本质上,GROUP BY和SELECT、ORDER BY对索引的使用规则是相通的。
最左侧列匹配规则。字段顺序与索引一致。
因此在创建索引时,需要充分考虑到后续的SQL语句会怎么写,大概需要如何过滤等等,而这些,在业务初期是做不到的——也就是说,好的索引一定是长期使用SQL查询数据的经验积累,而不是拍脑袋想象出来的结果。
把查询的索引规则搞清楚了,接下来就可以对于更新而言就好办了——索引不能太多,否则维护成本飙升,适得其反。
概念澄清
除了聚簇索引之外,每个二级索引都对应着一颗独立的
B+树,其中除了包含建立索引的字段值外,还包括主键值。即使依据索引找到了所需数据,也还需要再根据主键值在聚簇索引中找到完整的数据行其他字段值,这就需要进行一个称之为
回表的操作——除非需要查找的值都在索引里才不需要。覆盖索引并不是另一种索引分类,而是一种基于索引查询的方式——比如SELECT F1, F2, F3 FROM TABLE ORDER BY F1, F2, F3这样的SQL语句,仅仅只需要联合索引里几个字段值,而不需要再做回表操作,这种完全覆盖(查询字段小于等于索引字段)的查询就是覆盖查询。所以MySQL在执行时,会判断是否可能会导致大量的
回表操作,如果是的话,可能就直接执行全表扫描而不走联合索引了,这也是为什么查询禁止写成SELECT *的原因。即使是真要回表到聚簇索引,也最好加上
WHERE、LIMIT之类的语句限制一下回表到聚簇索引的次数,这样性能也会好一些。
感谢支持
更多内容,请移步《超级个体》。