
优化实践
背景说明
一家互联网公司的UC(User Center)系统,千万级注册用户,百万级DAU,暂时没有分库分表,所有的用户数据都在一张大表中。
UC会结合营销系统,依据某些设置条件作出筛选,然后给符合条件的用户推送消息,有时候筛选出来的数据量特别大,导致服务器性能急剧下降。
现在需要对这个UC系统的SQL查询做一些优化,提升服务器性能,下面是筛选用户的SQL语句。
> SELECT userid, type FROM user_auth WHERE userid IN (SELECT id FROM user WHERE age BETWEEN 26 AND 33);如果按照这个语句来直接查询,服务器可能会挂。
环境准备
实验环境对原始数据做了处理,分别有100万条用户数据和300万条用户认证数据。
如果使用SQL语句一条条导入再一条条导入,可能会直接死机,因此需要通过mysqldump导入实验数据(在导入备份数据前,需要创建和备份数据库名同名的数据库)。
-- 创建同名数据库(用户名密码和具体安装环境相关)
> mysqladmin -uroot -p123456 create sql_practice
-- 导入数据(具体路径取决于备份文件存放位置)
> mysql -uroot -p123456 sql_practice < /home/work/sql_practice.sql初期性能
在项目运行一段时间且数据量不大(几万用户)且没有任何索引时,查询速度很快,执行SQL耗时仅0.02s,可进行验证(具体耗时可能会因机器配置的不同而不同)。
- 将
user复制为user1,user_auth复制为user_auth1。
-- 删除表
> DROP TABLE IF EXISTS user1;
-- 复制表
> CREATE TABLE user1 AS SELECT * FROM user;
-- 指定主键
> ALTER TABLE user1 MODIFY id INT(11) NOT NULL PRIMARY KEY;
-- 删除表
> DROP TABLE IF EXISTS user_auth1;
-- 复制表
> CREATE TABLE user_auth1 AS SELECT * FROM user_auth;- 删除多余数据。
> DELETE FROM user1 WHERE id > 10000;
> DELETE FROM user_auth1 WHERE id > 30000;- 再执行SQL查询。
> SELECT userid, type FROM user_auth1 WHERE userid IN (SELECT id FROM user1 WHERE age BETWEEN 26 AND 33);然后观察执行结果。

结果显示。
MySQL首先对
user_auth1做了全表扫描,预估读取数量仅1行,这肯定是严重不准的,这也从另一方面说明EXPLAIN的局限性。接着对
user_auth1的userid匹配了user1的主键,这一点从type=eq_ref,ref=sql_practice.user_auth1.userid就可以看出来。
引申说明。
尝试给表加索引。
-- 给user1的age字段增加索引,提升子查询性能
> CREATE INDEX idx_user_age ON user1 (age);
-- 给user_auth1的userid字段增加索引,提升关联查询性能
> CREATE INDEX idx_user_auth_userid ON user_auth1 (userid);再次执行SQL查询。
> SELECT userid, type FROM user_auth1 WHERE userid IN (SELECT id FROM user1 WHERE age BETWEEN 26 AND 33);观察执行结果。

此时MySQL利用了二级索引执行了
user1的范围匹配,预估扫描5439条记录。然后又利用了
user_auth1的二级索引,匹配了user1的主键id索引。
中期性能
在经过一段时间的运行后,系统已经累积了100万的用户数据及300万的登录凭证数据,查询过程却越来越慢,已经慢到了令人无法忍受的30s左右。观察执行计划结果。

从结果可以知道。
先利用了
user表age字段的二级索引做range范围匹配,预估查询470203行记录。再通过
user_auth表userid字段的二级索引匹配user的主键,预估查询2行记录(明显严重不准)。这个执行计划和实际表现出来的应该是严重不匹配,但却无法提供更多关于如何改进索引性能的帮助。
原因分析
从连接算法可以知道,除了索引之外,查询性能与被驱动表的查询次数紧密相关,在已有索引的情况下,需要进一步确认是否是连接算法对性能造成了影响。
从前面的执行计划结果也可以知道,因为使用了IN,MySQL已经通过内连接把user选为驱动表了。
如果MySQL使用的是
SNL,那么会把被驱动表user_auth扫描300万次。如果将
user_auth作为驱动表,那么就会把被驱动表user扫描100万次。
为了验证猜想,可以把查询语句做一下改造,分别执行SQL语句及其执行计划(之所以说是猜想,是因为对于新手来说,这些内容并没有经过实践的检验,所以有一个逐渐认识的过程,在熟练掌握之后,就不再是猜想了)。
-- 左外连接,将user作为驱动表
> SELECT ua.userid, ua.type FROM user u LEFT JOIN user_auth ua ON u.id = ua.userid AND u.age >= 26 AND u.age <= 33;
-- 执行计划
> EXPLAIN SELECT ua.userid, ua.type FROM user u LEFT JOIN user_auth ua ON u.id = ua.userid AND u.age >= 26 AND u.age <= 33;
-- 左外连接,将user_auth作为驱动表
> EXPLAIN SELECT ua.userid, ua.type FROM user_auth ua LEFT JOIN user u ON u.id = ua.userid AND u.age >= 26 AND u.age <= 33;
-- 执行计划
> EXPLAIN SELECT ua.userid, ua.type FROM user_auth ua LEFT JOIN user u ON u.id = ua.userid AND u.age >= 26 AND u.age <= 33;观察执行结果。

虽然将
user_auth作为驱动表时预估读取数据量更大且会执行全表扫描,但整体执行时间大大降低,说明在索引不变的条件下,连接算法对性能影响巨大。在两张表都没有索引时,由于驱动表只会读一次,所以将
user作为驱动表时,会把user_auth表读300万次,而将user_auth作为驱动表时,则只会把user表读100万次,性能明显不一样(如果机器配置较低,可以适当降低数量级,否则会假死)。将
user作为被驱动表时,数据实际上是通过user的主键索引获得的,比user_auth的二级索引userid更高效。
继续优化
虽然通过改变连接算法,将查询响应时间从30s左右降低到了5s左右,但领导要求必须将查询时间降到1s以内。
由于SQL查询相对简单,仅断定是因为连接算法造成的查询性能低下未免有点武断,难道索引本身就一点问题都没有吗?
带着这个疑问,做了一些针对执行计划的调试和校准。
不当索引
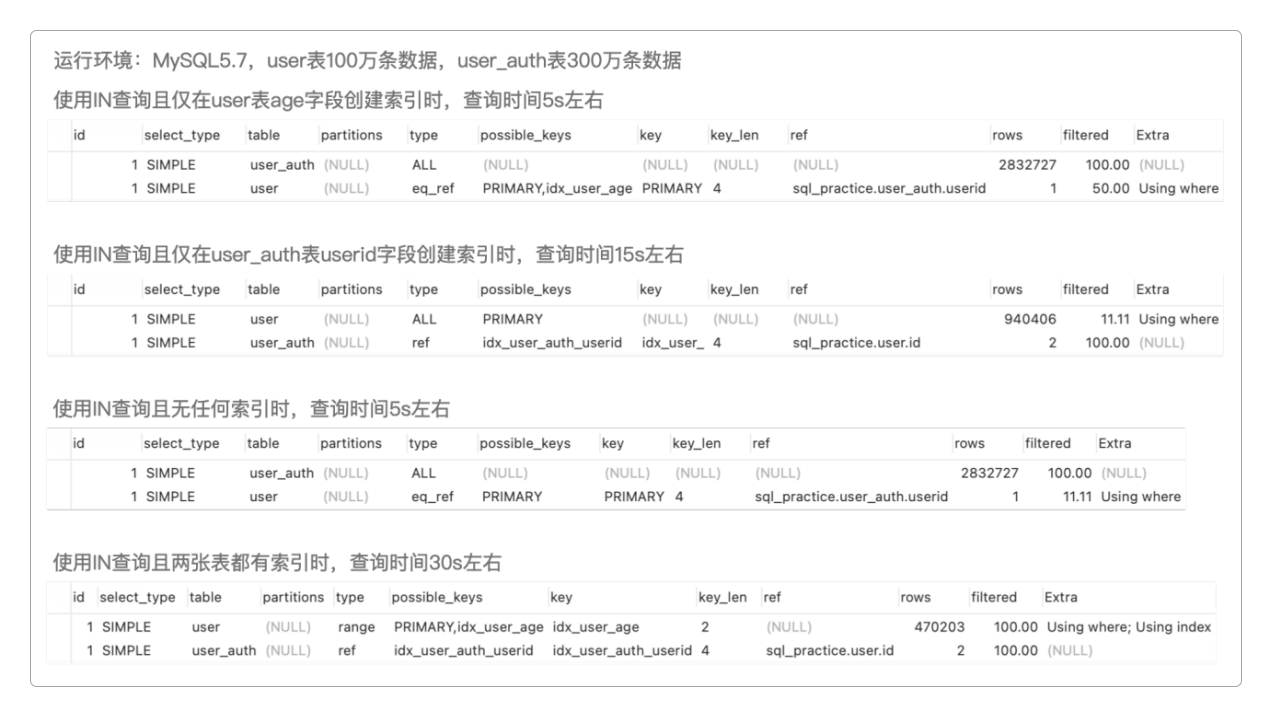
观察调试结果(与具体环境有关),可以发现一些比较有意思的现象——在userid字段上创建的索引与查询之间存在明显的联系。
没有
userid字段索引的查询比有userid字段索引的查询要快。当两张表都有索引或者在
userid字段上创建索引时,user表就会被当成驱动表。当两张表都没有索引或者没有在
userid字段上创建索引时,user_auth表就会被当成驱动表。
那么问题来了:是在userid字段上创建的索引使用不当?还是根本就不应该创建索引?
回顾MySQL索引相关的内容,比如联合索引规则、全值匹配规则、最左列匹配规则、最左前缀匹配规则、等值匹配规则、范围匹配规则似乎都用不到。
但是会注意到userid上创建的只是一个二级索引,即使依据索引找到了数据行,还是需要去做一个回表操作,是不是因为回表操作导致查询缓慢呢?
如果MySQL不做回表而能够直接拿到所需数据,会不会更快?
这就需要用到之前了解到的另一块知识内容——覆盖索引。
也就是说,在userid和type两个字段上建立联合索引,而在查询时将这两个字段全部列出来,就能100%覆盖到索引了。
将原来userid单字段索引改为(userid, type)联合索引。
-- 删除原有索引
> DROP INDEX idx_user_auth_userid ON user_auth;
-- 创建索引
> CREATE INDEX idx_user_auth_userid_type ON user_auth (userid, type);如果age字段无索引则恢复索引。
-- 删除原有索引
-- 创建索引
> CREATE INDEX idx_user_age ON user (age);再次执行SQL。
> SELECT userid, type FROM user_auth WHERE userid IN (SELECT id FROM user WHERE age BETWEEN 26 AND 33);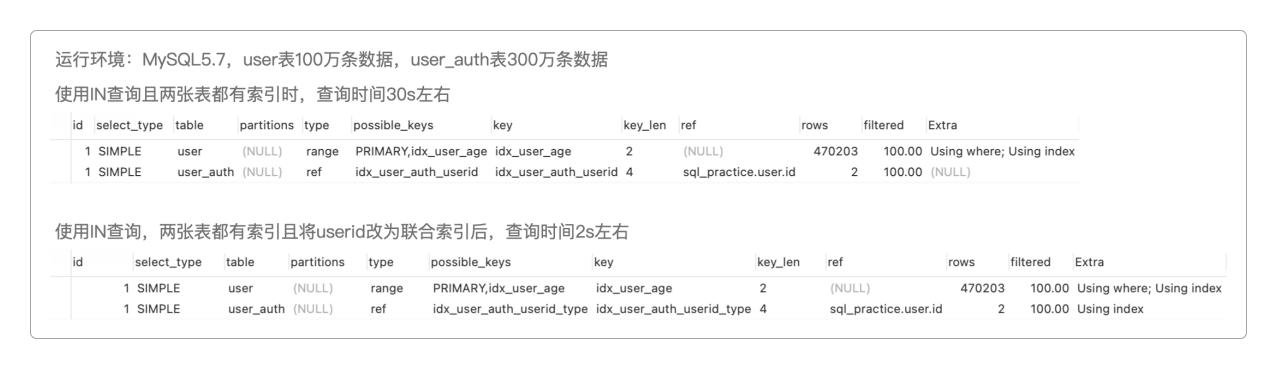
EXPLAIN毫无变化,唯一不同的是索引名称的变化。慢查询并不是需不需要创建索引的问题,而是索引使用不当导致的问题。
通过
覆盖索引,避免回表查询,极大地提高了性能。
将查询时间从30s降低到2s,性能已经提升10倍以上了,但是否还能进一步优化呢?
结合业务进行优化
经过仔细与业务需求方沟通之后发现,其实没有必要一次取出全部的数据,完全可以分多次读取,也就是说:可以分区间查询——这意味着,SQL查询可以这样写:
> SELECT userid, type FROM user_auth WHERE userid IN (SELECT id FROM user WHERE age = 26);
> SELECT userid, type FROM user_auth WHERE userid IN (SELECT id FROM user WHERE age = 27);
......
> SELECT userid, type FROM user_auth WHERE userid IN (SELECT id FROM user WHERE age = 33);将一个区间值以分段的方式查询出来,然后在业务逻辑层代码中实现组装。
而且这样做还有另外一个好处:避免了一次查询出来的数据量过大导致内存紧张。
执行以上任意一条SQL查询后再观察执行结果。
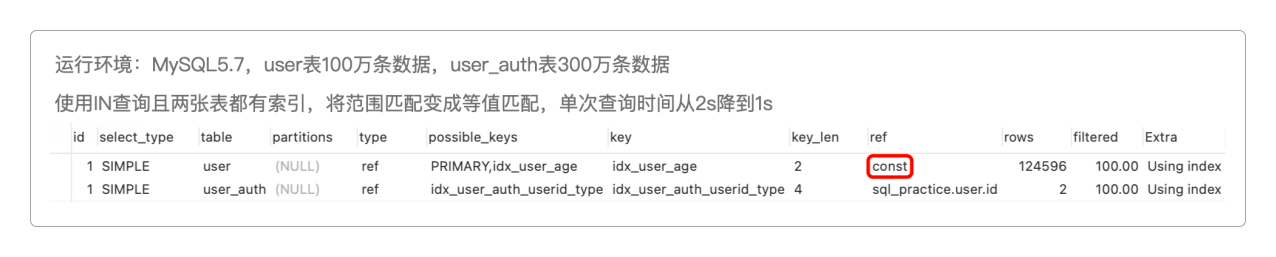
等值匹配后,第一行的
ref从NULL变成了const,预估读取的行数也从470203减少到了124596,说明多表关联时索引的查找方式是常量类型,将所需匹配的记录数量大大缩减,这也是等值匹配的意义。将范围查询变成等值匹配,给性能带来的提升并不明显,基本等同于是没有优化。
其实之所以改成等值匹配,无非就是想每次查询限制一下范围而已,可以考虑加上LIMIT限定,可以再次优化SQL。
> SELECT userid, type FROM user_auth WHERE userid IN (SELECT id FROM user WHERE age = 26) LIMIT 1000;
性能直接提升了200倍左右,效果非常明显,每次查询速度飞快,而且也避免了影响其他查询任务的执行。
调优️总结
通过对这个慢查询案例问题的一步步解决,能进一步地加深对数据库索引机制的理解。
通过对一个很简单的
SQL语句的优化过程,搞清楚了连接算法效率、执行计划、覆盖索引、等值匹配原则、LIMIT限定等核心问题。创建索引不一定能提高性能,甚至适得其反,所以准确理解索引机制非常重要,在完全理解业务的情况下,尽可能利用联合索引。
慢查询的优化是一个逐步深入,有时候甚至是反复的过程,在不同的数据量级的情况下,优化手段可能都不同——整个优化过程其实是一个
无索引 -> 有索引 -> 无索引 -> 联合索引这样一个演变过程。优化不仅仅是数据库的问题,不同的数据库索引机制也会不同,归根到底,需要对业务中所使用的数据引擎有比较深入的了解。
慢查询问题与业务需求、实现手段都有关系,需要跳出框框,从更多维度思考,尤其是要搞清楚问题是什么,否则一定会事倍功半。
感谢支持
更多内容,请移步《超级个体》。